Kinesis
什麼是 Kinesis?
以下是 AWS 官網對 Kinesis 的介紹:
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information. Amazon Kinesis offers key capabilities to cost-effectively process streaming data at any scale, along with the flexibility to choose the tools that best suit the requirements of your application. With Amazon Kinesis, you can ingest real-time data such as video, audio, application logs, website clickstreams, and IoT telemetry data for machine learning, analytics, and other applications. Amazon Kinesis enables you to process and analyze data as it arrives and respond instantly instead of having to wait until all your data is collected before the processing can begin.
從上面的官方介紹可以整理出幾個 Kinesis 的服務重點:
處理 streaming data 用
可針對串流資料進行即時分析處理,不需要等待資料全部到齊
資料來源可以從 video, audio, application log, 網站點擊所產生的資料、IoT 遙測資料 … 等等
可針對資料進行分析,甚至可以搭配其他服務進行 machine learning 相關的工作
其他特性
可將 Kinesis 的資料 export 到多種不同的 AWS 服務,例如:
- EMR (分析)
- S3 / DynamoDB (儲存)
- Redshift (大資料分析儲存)
- Lambda (事件驅動)
主要的組成元件包含:
Stream(資料本身)、Producer(資料來源)、Consumer(資料使用者)、Shard(關係到資料處理能力)Producer 會持續不斷的送資料到 Kinesis stream 中進行處理 (相關的資料處理程式要預先設定好)
越多資料要處理,就需要增加越多個 shard 到 Kinesis sream 中 (每個 shard 的資料處理能力是每秒 2MB read & 1MB write)
Consumer 可以取用 Kinesis stream 的資料(可以同時被多個 consumer 存取資料)
Consumer 可能是 real-time dashboard、DynamoDB、S3、Redshift、EMR … 等等,也可以自行開發程式來取得 stream 資料
Kinesis 預設存放 24 小時的資料,最長可以設定為 7 天
Kinesis 可以提供哪些類型的服務?
Kinesis 根據功能共分為以下四類:
Kinesis Video Streams
Kinesis Data Streams
Kinesis Data Firehose
Kinesis Data Analytics
Kinesis Video Streams
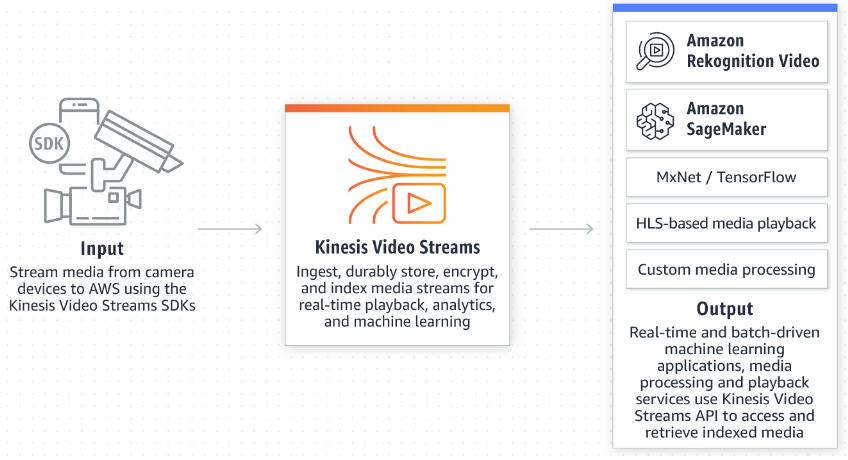
可針對視訊的串流資料進行回放、安全監控、臉部辨識、機器學習,或是其他分析….等工作。
Kinesis Data Streams
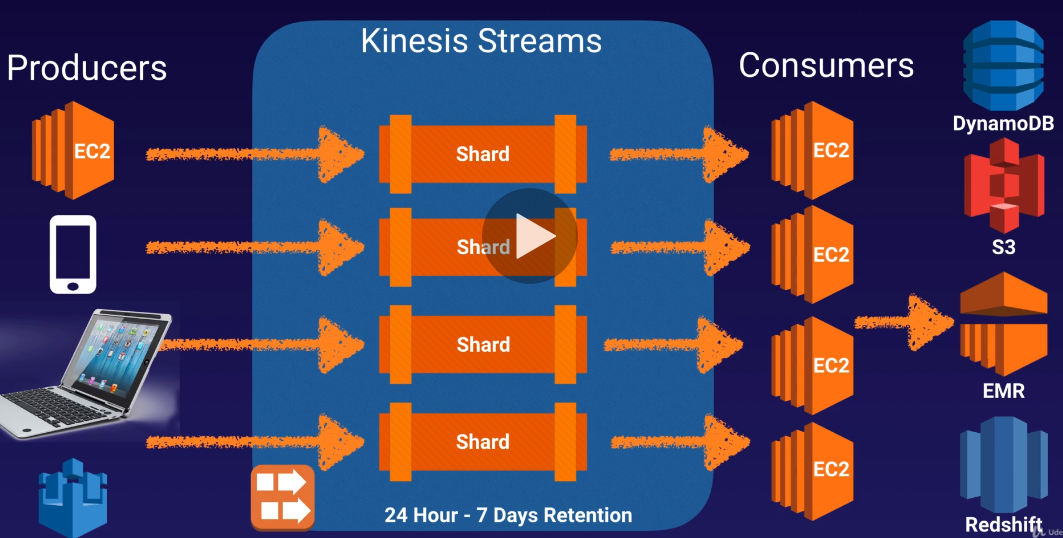
資料在 Kinesis 中會以 shard 的形式存在,保留在 persistent storage 中
搭配後方的服務(例如:EC2, Lambda, Kinesis Data Analytics) 進行後續的分析處理工作
處理完的資料可以存到 S3, EMR, Redshift, DynamoDB …. 等地方做後續運用
Kinesis 處理資料的能力會因為 shard 的數量不同而不同,而 shard 的數量需要手動指定,無法自動擴展
Kinesis Data Firehose
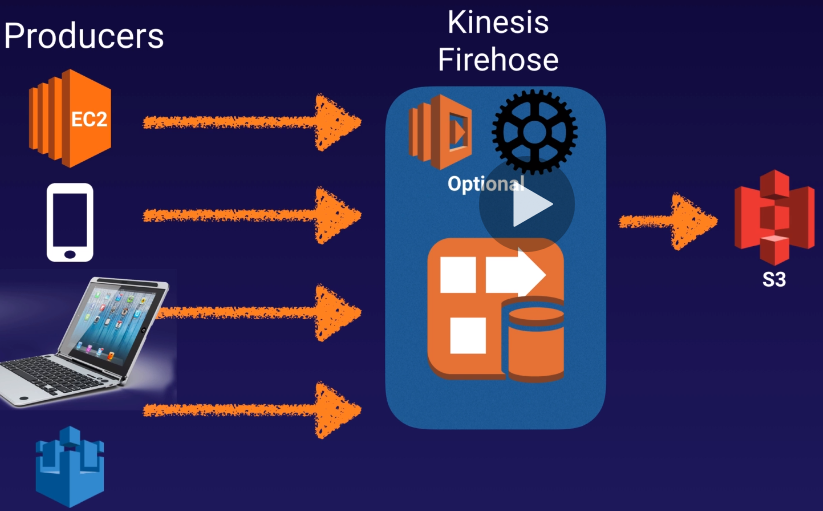
是個全託管的服務,會根據 request & throughput 自動 scale out/in
沒有 persistent storage,資料進入 Kinesis 後要立即處理
可選擇搭配 Lambda function or Kinesis Data Analytics 來進行資料處理
處理完後的資料可以轉存入 S3、RedShift、Elasticsearch 服務中並進行後續的即時分析之用
Kinesis Data Analytics

此類型的 Kinesis 則是將查詢和分析直接設定在 Kinesis 服務本身
輸出的結果可以存到 S3, Redshift, Elasticsearch … 等服務
考試重點
了解
Kinesis Data Streams&Kinesis Data Firehose的差異了解 Kinesis Data Analytics 可以如何被使用
EMR (Elastic MapReduce)
EMR 概觀
EMR 是 AWS 一個全託管的 big data 處理服務
EMR 本身的功能是由許多開源工具(例如:Spark、Hive, HBase, Flink、Hudi、Presto)所組成
底層的 framework 除了可以選擇 Hadoop 之外,也可以選擇 HBase、Presto、Spark … 等等
基本上就是啟動多台 EC2 instance,並安裝相關軟體之後,協助做 big data 的處理
標準的 workflow
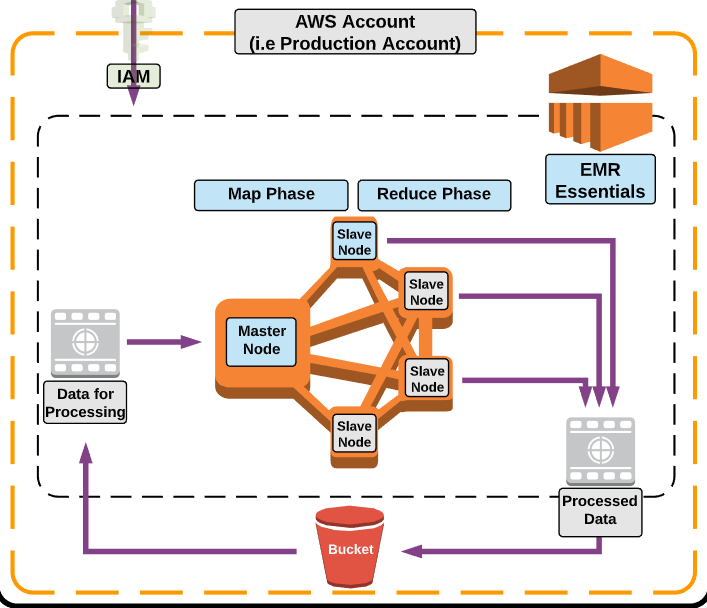
首先,資料必須存放在 AWS S3、DynamoDB or Redshift 上,資料可以從幾個地方送到 EMR 中處理
資料會經過一個
map的過程,並分散到不同的 cluster 進行處理,每個 cluster 中有 master & slave node (這個 cluster size 可以隨時調整,也可以佈署多個 cluster)使用者還可以進入到 cluster node 中的 OS 進行客製化的調整
slave node 會負責資料的處理 & 計算 (平行處理)
處理完的結果,會再度經過一個
reduce的過程,整合成一個輸出後回傳處理完的資料同樣也可以回到 S3、DynamoDB or Redshift …. 等服務
Map & Reduce
Map
map 是個用來將大容量的資料檔案切分成多個適合處理的小檔案的一個 function
在 map 過程中,檔案會被切分成大小為 128MB 的 chunk
若是 chunk 數量多過 node 的數量,就會被 queue 起來
Reduce
reduce 是用來將多個資料處理後的結果整合成單一結果的 function
整合後的結果需要存放在其他地方(例如:S3、DynamoDB、Redshift),EMR 本身不會存放經過 reduce function 整合後的資料
EMR master/slave node
master node 是用來作為 coordinator,用來分派資料 & 任務給 slave node
master node 會負責追蹤 & 監控每個任務的處理狀況
slave node 有兩種,分別是
core node&task nodeslave core node 可以執行任務,也可以儲存資料(存放於 HDFS 中,而這個分散式 file system 是使用 slave core nore 的硬碟所建置而成的)
slave task node 僅執行任務,不屬於 HDFS 的一部分,因此在佈署上不一定要有