變更 Instance Type
當 EC2 instace 需要 scale up 時,那可以透過調整 instance type 的方式達成(例如:m5.large -> m5.xlarge),只是此項操作僅支援 EBS-Backed instance,不支援 Instance Store instance (差異可參考此文章),執行流程如下:
停止(stop) instance
調整 instace type (透過 instance settings)
啟動(start) instance
至於為什麼 change instance type 僅支援 EBS-Backed instance;原因是,這類的 EC2 instance 使用的 volume 來自於透過網路接上的 EBS 服務,因此調整了 instance type 後,很有可能會被 schedule 到其他實體機器重啟,只有在 volume 位於 EBS 這樣的情況下,才可以重新將 root volume 掛回來;而 Instance Store 是存在於實體機器上的,自然也就喪失了在不同實體機器間遷移的能力,因此也就不會支援 change instance type 的操作。
Enhance Networking
目前 EC2 目前的 instance type 幾乎都有使用 SR-IOV 的技術,支援 enhanced networking 的功能,可以提昇 bandwith & 更高的 PPS(packet per second),並且還可降低 latency。
若要比 ENA 更快的網路速度,那還有 EFA(Elastic Fabric Adapter) 可以選擇,可以大幅提昇 node 之間的通訊效率,而這選項通常用於 HPC 相關應用上,而且僅支援 Linux。
在新世代的 instance type 上就會有支援 ENA 的功能,但舊世代的可能就沒有;以下啟用兩個 instance 進行測試,分別是 t2.micro & t3.micro,其中 t3.micro 就有支援 ENA:
1 | # 來自於 t2.micro |
Placement Group
之前有寫過,可參考 AWS CSA Associate 學習筆記 - EC2(Elastic Compute Cloud) Part 3。
Troubleshooting
EC2 啟動異常
InstanceLimitExceeded
超過使用限額了,每個服務都有其使用限額(可參考官網文件),可以申請提高 limit
on-demand 的額度是以 region-based 的方式計算的
vCPU-based limit 僅適用於 on-demand & spot instance
InsufficientInstanceCapacity
這是 AWS 的問題,該 AZ 的硬體容量不足以產生更多 on-demand instance
可以嘗試等幾分鐘後再試試看
把原本一大包的請求(例如:10 個),拆成多個小請求(例如:2 個)慢慢送
如果很緊急,可以嘗試調整 instance type,或許可以成功;然後晚點再調整回來
Instance 從 pending 狀態直接進入 terminated
發生這件事情的原因可能包含:
可能已經達到 EBS volume limit
EBS snapshot 壞掉了
root EBS volume 是加密的,但沒有存取 KMS key 的權限來進行解密
用來啟動 instance 的 instance store backed AMI 缺了某些必要的檔案
要找到真正的原因,則須透過 AWS EC2 console 中的 instances >> Description tab,觀察一下 reason 相關資訊
EC2 SSH 連線異常
一般的遇到 SSH 無法連線狀況,可能來自於以下其中幾個狀況:
SSH key 存取權限是否設定為
400user name 可能給錯
security group / Network ACL / Routing Table 可能沒設定好
instance 沒有 public IP
CPU 使用率過高
另外一個連線到 EC2 instance 的方法稱為 EC2 Instance Connect,其實這個方法實際是從 AWS 內部進行連線,因此來源 IP 並非來自使用者本身,所以設定 security group 時就需要注意。
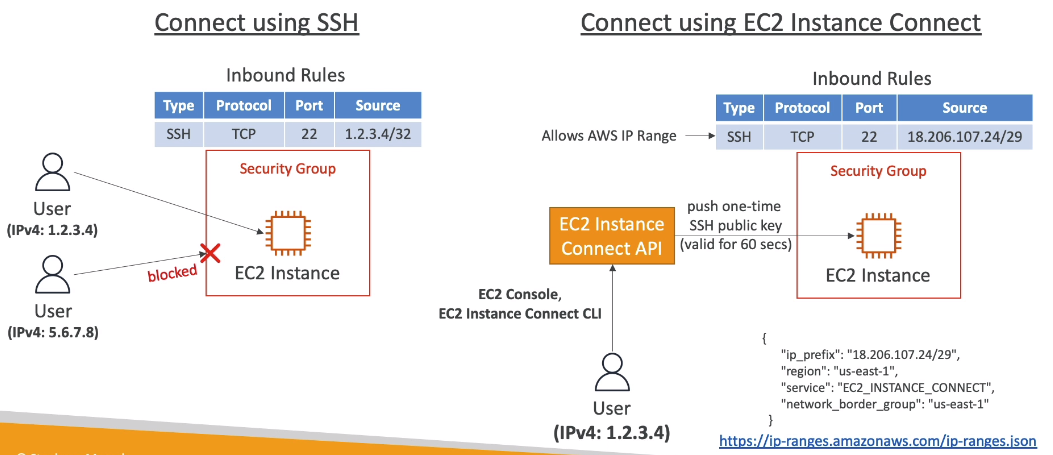
實際上 EC2 Instance Connect 的原理是:
使用者送出 EC2 Instance Connect API 到 AWS
AWS 推送一次性的 SSH public key 進入 EC2 instance (因此若是啟動 EC2 instance 沒有指定 key 也沒關係)
使用者透過 AWS 提供的網頁界面連入 EC2 instance
若是要明確的指定 EC2 Instance Connect 的 source IP range,可以從 https://ip-ranges.amazonaws.com/ip-ranges.json 取得 IP 清單,搜尋
EC2_INSTANCE_CONNECT,找到對應的 region 即可找到正確的 IP CIDR range
Spot Instance & Spot Fleet
基本使用規則
spot instance 的特色就是相較於 on-demand,可以透過很低的價格(70%+ off)購買 EC2 instance 來使用,但要正確使用 spot instance 還是要搞清楚遊戲規則的,基本運行規則如下:
spot instance 的價格是浮動的,會根據目前 AZ 的硬體容量不同而不同
必須預先定義一個最大願意支付的價格(max price);若是 spot instance price 大於 max price,使用者會被通知,在兩分鐘內決定要 stop or terminate instance
若希望 spot instance 不要被收走,可以設定
spot block,指定 1~6 小時的長度,那 AWS 會盡可能的保留給你使用但還是有極低的機率會有可能被回收
有鑑於 spot instance 是會被回收的,因此比較適合用 spot instance 運行的就會是 batch job, data analysis, 失敗可以重來的工作 … 等這一類型的 workload
Lifecycle
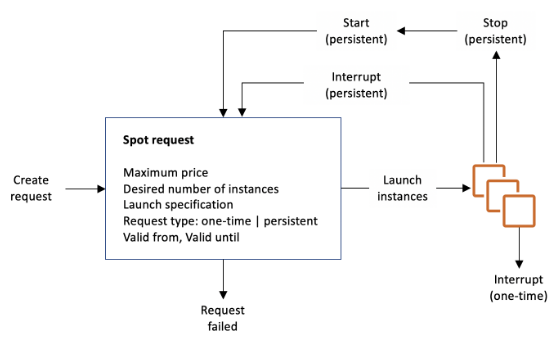
要使用 spot instance,要建立一個 spot request,裡面會包含 max price … 等像上圖中的相關資訊,其中比較需要注意的是 request type 是 one-time or persistent,這關係到了 spot instance lifecycle 的表現,基本原則如下:
max price > spot instance price,那 spot instance 就會啟動
若是 spot instance 被回收的情況下:
- request type 設定為
one-time,那即使價格降低下來,spot instance 也不會再重啟了 - request type 設定為
persistent,如果價格重新回到 max price 以下,那 spot instance 就會被重啟
- request type 設定為
spot request 會被
valid from&valid until兩個參數影響,決定上述的收回 & 重啟動的行為是否會持續運作
但這衍生出來了另外一個問題 => 如何正確移除 spot instance ?
若是 request type 設定為 persistent,若直接 terminate 一個 spot instance,根據上述的 lifecycle 定義,那 spot request 就會重啟一個新的 spot instance;因此正確移除 spot instance 的流程是:
移除 spot request
再移除 spot instance
Spot Fleet
為了進一步的達成更大程度的自動化,AWS 提供了 Spot Fleet 的功能,而這功能要達成讓使用者可以設定 target capacity & 價格限制,並提供自動化配置 spot instance 的功能,省去自行手動配置的繁瑣操作的目標。
其實主要概念是 Spot Fleet = 一群 spot instance + (optional) on-demand instance
這個自動化工作要達成的流程是:
使用者必須先定義 Launch Pool,這包含了提供 instance type、OS、AZ … 等資訊 (可以設定多個 Launch Pool)
spot fleet 會根據設定好的 target capacity & 價格限制,從 Launch Pool 啟動 spot instance(不夠的話就會改成啟動 on-demand instance),直到滿足 target capacity or 達到價格上限
而配置 spot instance 有以下策略可以設定:
lowestPrice:從 Launch Pool 找最便宜的啟動 spot instance
diversified:盡可能從不同的 Launch Pool 啟動 spot instance
capacityOptimized:使用最能滿足 capacity 的 Launch Pool 啟動 spot instance
總結來說,Spot Fleet 就是把配置 spot instace 這件事情給自動化了,使用者只要設定好條件即可。
Burstable Instances
AWS 提供了稱為 burstable type 的 instance T2 & T3,可以根據使用者需求,短時間內取得比較好的 CPU 性能
但要 burst 需要有
burst credit,提昇 CPU 性能的代價就是會消耗 credit,而當 credit 消耗完後,CPU 性能就會變得很差若是 instance 停止 burst,那 credit 就會逐漸累積起來,但不同的 instance type 各有其上限
適合用來應付偶發性的 traffic spike 時需要大量 CPU 運算的場景
有鑑於 burst credit 有時會有不夠用的問題,因此 AWS 還提供了
T2/T3 Unlimited的 instance type 可用,那就沒有 credit 的問題,不過一直將 CPU 用滿,會需要多花費不少錢,那不如就使用 M or C 系列的 instance type
監控 (Unified CloudWatch Agent)
基本監控
AWS 預設提供免費的 5 mins 一次的監控;若是要改成 1 min 的 detailed 監控,那就需要付費
基本的監控項目包含 CPU、Network、Disk & Status Check Metrics(包含 Instance Status & System Status 兩種)
Instance Status 為 instance level 的狀態檢查 (通常發生問題需要使用者自行處理);反之 System Status 則是底層硬體的問題,由 AWS 負責處理
客製化監控
收集資料的間隔可設定 1 min(Basic Resolution) ~ 1 sec(High Resolution)
可收集 RAM & 其他 Appication level 的 metric
需要確保 EC2 Instance Role 的 IAM 權限有設定正確,否則資料無法送到 CloudWatch
Unified CloudWatch Agent
若是要更進階的監控資料蒐集,甚至包含 log,那就可以考慮使用 Unified CloudWatch Agent,這個工作有以下特性:
除了 EC2 instance 之外,也可以用在 on-premise 的機器上
可以蒐集蠻多 system-level metric,例如:RAM、process(利用
procstatplugin)、disk … 等等;可以將 instance 中的特定 log 上傳到 CloudWatch Logs 中 (預設不會傳)
可透過 SSM Parameter Store 來統一管理 Unified CloudWatch Agent 的設定
預設上傳的 metric 的 default namespace 為
CWAgent具備上傳資料到 CloudWatch 的 IAM 權限也是必備的
CloudWatch Agent 可以蒐集到詳細的 metric 有哪些,可以參考官網文件
EC2 Instance Status Check
基本概念說明
AWS 會協助自動偵測 EC2 instance 的運行狀況,包含以下兩種:
System Status Check:這是監控底層硬體的狀況,有問題 AWS 會負責處理;通常遇到這問題,stop & start instance,讓 instance 重新在其他硬體運行起來是標準解法
Instance Status Check:這是單純 instance 真的故障 or 設定有誤造成的,可以嘗試調整設定(例如:網路) or reboot instance 試試看
如何監控 & 處理
與 status check 相關的 CloudWatch metric 有以下三個:
StatusCheckFailed_System
StatusCheckFailed_Instance
StatusCheckFailed (兩種狀況都適用)
可以透過監控上面三個 metric 來設計應對方式,一般可能會有以下幾種方式來處理:
設計 CloudWatch Alarm,並透過 SNS 發送通知
設計 Auto Scaling Group,明確指定 min/max/desired 的設定,那有 instance 掛掉後,ASG 就會幫補上新的
Hibernate
這是休眠功能,其原理就是把運行在 memory 中的資料透過寫到 EBS volume 的方式達成的,但使用上有以下幾個需要注意的地方:
執行 Hibernate 後,資料會寫進 root EBS volume 的某個檔案中
root EBS volume 必須是加密的
並非所有 instance family 都會支援此功能;Bare Metal 的機型也不支援
instance memory 容量必須低於 150GB
不論是 On-Demaid or RI 的機器都可以用這功能
Instance 不能在 Hibernate mode 維持超過 60 天