Application Load Balancer
運行在 Layer 7
可將 request 送到多個 target group;而 target group 可以是 EC2、ECS、Lambda … 等服務(IP 也行,但一定得是 private IP,例如:on-premise site service)
支援以 path、hostname、query string、header 資訊為基礎的 routing,可根據這些條件將 request 遞送到不同的 target group 中
還可針對不同的 target group 有權重(weight)的設計,來決定轉發流量的百分比;透過此功能,可達到 Blue/Green Deployment 的效果
application 端看不到 client IP,這資訊會放到
x-forwarded-forheader 中
Network Load Balancer
運行在 Layer 4,用來轉發 TCP/UDP 流量
相較於 ALB,有較低的 latency (400ms -> 100ms)
每個 NLB 在一個 AZ 都會有一個固定 IP(其他 ELB 只有 hostname)
不包含在 free tier 中
target group 可以是 EC2、IP address(private IP only)、也可以是另一個 ALB
Gateway Load Balancer
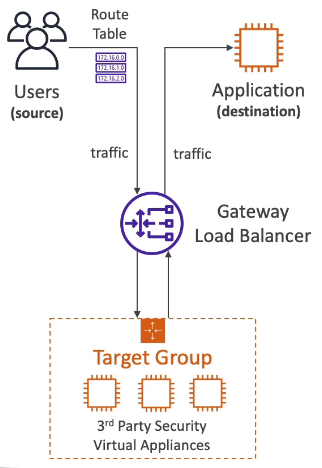
這個服務是用在內部若是安裝了多個 3rd-party security virtual appliance 時,若是希望從外部進來的流量都可以經過這些 appliance 的檢測,那就需要搭配 Gateway Load Balancer 來完成
firewall, intrusion detection、prevention system, deep packet inspection system, payload manupulation 都屬於這類的 appliance
後面的 target group(appliance 安裝的地方) 可以是 EC2 instane,也可以是個 IP address(必須是 private IP)
運行在 TCP Layer 3,其實就是
transparent network gateway+load balancer的功能使用
GENEVEprotocol (port 6081)
Sticky Session
Sticky Session功能是讓同一個 client 送的 reuqest 可讓 ELB 導向同一個 instance,有可能造成 request 無法平均轉發目前支援的 ELB 有 CLB & ALB
此功能是透過 cookie 實現的,一共分為以下兩種類型:
Application-based Cookie
又可分為custom cookie&application cookie兩種,差異如下:- custom cookie:
- 由 application 產生,可以包含任何自訂的 key/value 組合
- 設定必須指定在 target group 中
- 不能使用
AWSALB、AWSALBAPP、AWSALBTG… 等關鍵字作為 cookie name
- application cookie:由 ELB 自動產生,cookie name 為
AWSALBAPP
- custom cookie:
Duration-based Cookie:由 ELB 自動產生,cookie name 為
AWSALB(for ALB) orAWSELB(for CLB),可以自行決定有效期間是多久
ELB - SSL/TLS Certificate
SNI(Server Name Indication) 是用來解決一個 web server 同時服務多個域名的狀況
client 也需要使用較新的 protocol,才可以在 SSL handshake 階段指定 hostname
目前 AWS 中僅有 ALB/NLB/CloudFront 支援 SNI,CLB 沒有
ELB - Monitoring, Troubleshooting, Logging, and Tracing
HTTP 400屬於 BAD_REQUEST,表示 client 送了不合法的 HTTP requestHTTP 503 Service Unavailable,必須確認 ELB 後方是否有 healthy instance,需要檢查一下 CloudWatch 中 ELB 的HealthyHostCountmetricsHTTP 504 Gateway Timeout表示要檢查 EC2 instance 是否有開啟 keep-alive 設定,並確保這個設定的時間比 ELB 的 idle timeout 設定時間更長ALB 會為每個 request 額外加上
X-Amzn-Trace-Idheader,這可用來追蹤 request 從 ELB 轉發出來後是到哪裡去(但 ALB 目前還沒與 X-Ray 整合)
Target Group 相關設定
target group 有些設定可以用來調整 ELB 轉發 request 的行為,以下介紹幾個比較重要的設定:
deregistration_delay.timeout_second:這是用來設定當要對 EC2 instance 進行 deregistration 時,要等待的時間,確保 request 可以完成後再斷掉連線slow_start.duration_seconds:這可以用來設定給剛加入的 healthy instance 暖身的時間,在設定時間內不會把足量 request 轉發過去,會逐漸增加轉發數量,直到時間到了後,才會轉發足量 request 過去load_balancing.algorithm.type:用來決定 ELB 如何轉發 request,有 round robin & least outstanding request 兩種,這是 ALB 擁有的兩種模式若是 NLB,還有 Flow Hash(基於 IP address、source/destination port、TCP sequence number) 可選
sitckness.enable:是否啟用 sticky sessionsitckness.type:分為 application-based & duration-based cookie 兩種sitckness.app_cookie.cookie_name&sitckness.app_cookie.duration_seconds&sitckness.lb_cookie.duration_seconds:這幾個設定的用法可以參考上面 sticky session 章節的說明
Auto Scaling Group
Overview
可根據 CPU、Network …. 等 CloudWatch metric 來作為 scaling policy,也可以使用 custom metrics(memory 用量算這個)
ASG 透過 Launch Configuration or Launch Template 來建立新的 EC2 instance
包含 AMI + Instance Type、EC2 User Data、EBS volume、Securiry Group、SSH KeyPair … 等設定
設定在 ASG 上的 IAM role 會被指定到由 ASG 產生出來的 EC2 instance
若是透過 ASG 產生出來的 EC2 instance 因為某些不明原因被移除了,ASG 會幫忙重新產生出來
ASG 可以協助將被 ELB 標記為 unhealthy 的 EC2 instance,然後再重建一個取代他
ASG 相關的 CloudWatch metric 需要 enable group metric 才會開始蒐集,蒐集間隔為 1 分鐘
Launch Configuration 與 Launch Template 的差異
相同處:
- 都需要設定 AMI ID、instance type、SSH key pair, security group、EC2 user data … 等跟啟動 EC2 相關的資訊
差異處:
Launch Configuration:舊版的設定,任何一次更新都需要重建
Launch Template:(較新的版本,建議使用)
- 有版本管理的功能,因此一個 launch template 可以有多個版本
- 可建立 parameter subset,因此一部份的設定可以被重複利用 or 繼承
- 可部屬 on-demand & spot instance (混合也可)
- 支援 plancement group, capacity reservation、dedicated host、multiple instance type …. 等設定
- 可使用 T2 unlimited burst 功能
使用限制:
- 無法同時使用 Launch Configuration 與 Launch Template
Lifecycle Hooks
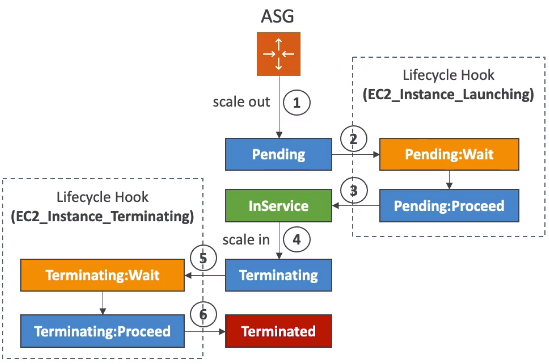
預設情況下,透過 ASG 產生的 instance 啟動後就會被歸類在 InService 的狀態;若是要在 instance 被歸類在 InService 之前執行一些命令,那就需要透過 Lifecycle Hook 來完成。
從上圖來看,當 instance 進入 pending 狀態後,搭配 lifecycle hook,就會進入上圖的第 2 & 3 階段,並可以指定執行一段 script 後,再進入到 InService 階段。
而移除 instance 階段也可以加入這個 hook,讓 instance 實際被移除之前,搭配 hook 進入到第 5 & 6 階段,做一些額外的操作,而通常這樣的 hook 常用在清理資源、取得 log … 等工作。
最後,Lifecycle Hook 可與 EventBridge、SNS、SQS …. 等服務進行整合串接。
Health Check
為了確保 HA,ASG 中有 multi-AZ 的設定是必須要的
ASG 支援以下幾種 health check 方式:
- EC2 status check
- ELB health check
- custom health check:這方式是透過 AWS CLI/SDK 送訊息給 ASG
ASG 會把 unhealthy instance 移除後重建一個新的,不會用 reboot 的方式
這個部份可能需要了解的 CLI command:
set-instance-health:用來作為 custom health check 用terminate-instance-in-a-auto-scaling-group
Troubleshooting
使用 ASG 時可能會發生以下幾種狀況:
有
<number of instances>個 instance 已經運行中,後續啟動新的 EC2 instance 失敗可能是 ASG 已經達到 MaximumCapacity 的限制;需要時可增加來解決此 issue
啟用 EC2 instance 時失敗:
指定的 security group or SSH key pair 可能因為被移除而不存在
若是 ASG 持續啟用 EC2 instance 但卻失敗,且維持持續失敗狀態超過了 24 小時,它就會自動中止這個行為不會再繼續嘗試
另外 ASG 無法正常運作也有可能是以下原因造成:
autoscaling config 沒有正確運作
沒找到指定的 autoscaling group
AZ 不支援指定的 instance type
AZ 已經不存在了 (機率很低)
不支援指定的 EBS mapping
autoscaling 服務並沒有在 AWS account 中啟用
嘗試將 EBS block device 繫結到 instance-store AMI
RDS and Multi-AZ Failover
RDS
Multi-AZ failover 不是種 scaling solution,因為無法降低負載
若是有啟用 multi-AZ,那 snapshot 的操作會對 secondary DB(slave) 執行,不會對 master DB 執行,因此 master DB 不會有 performance impact;但若是沒有啟用 multi-AZ,那 snapshot 就會對 master DB 執行,會造成短暫的 performance impact (取決於資料量的多寡)
reboot with failover,會讓 RDS instance 重新啟動後換到另一個 AZ (在啟動 multi-AZ 的情況下)
當 failover 發生時,AWS 會將 RDS endpoint DNS 切到正常的 AZ 中的 slave(standby) RDS instance
Read Replica
最多 5 個 read replica
read replica 可以跨 AZ & region
replication 是非同步的,因此需要關心 replica lag metric
Read Replica 可以被 promote 成獨立(standalone)的 DB,接著就可以當 master DB 用,但會斷開與 master DB 的 replication link,因此在 promote 開始就會與 master DB 開始有資料上的差異
promote read replica 並不會取代原本的 master DB,這跟 multi-AZ 架構中的 failover 是完全不同的概念
若沒有啟用 automated backups 並設定 retention period 大於 0,那就無法新增 read replica
加密 RDS
看教學影片中,有看到
db.t2.micro的 RDS instance type 不支援建立時就加密;不過現在都至少是 t3 以上,也都可以加密了無法對現有未加密的 RDS instance 進行加密,正確的流程是:
- 對現有的 RDS instance 進行 snapshot
- 將 snapshot 複製到同一個(or 另外一個) region,並在複製選項中勾選
Encrypt選項 - 將加密(encrypted)後的 snapshot 還原成新的 RDS instance
若是要將加密後的 RDS snapshot 分享給另外一個帳號,需要注意的是:
- 不能用預設的 default KMS key,因為這無法分享,必須使用 custom AWS KMS key 才可以
- 用來加密的 custom AWS KMS key 要分享給另外一個帳號,對方才可以解密
- 透過 AWS console / CLI / RDS API 都可以將 encrypted snapshot 分享給另外一個帳號
- 不能將 encrypted snapshot 公開分享
- 不能分享透過 TDE(Transparent Data Encryption) 技術加密的 snapshot (for Oracle or Microsoft SQL Server)
Maintenance Windows
在 AWS service 中,有些有 maintenance windows 的設計,而這個設計是用來讓管理者可以指定日常系統維護的時間(例如:每週三凌晨 04:00~06:00),告知 AWS 若是服務有 software or security 相關的更新,可以在 maintenance windows 指定的時間進行。
目前可以設定 maintenance windows 的 AWS managed service 有以下幾個:
- RDS
- Elasticache
- Redshift
- DynamoDB DAX
- Neptune
- Amazon DocumentDB
而沒有 maintenance windows 設計的常見服務則有:
- EC2
- Lambda
- Amazon QLDB
Elasticache
目前 AWS Elasticache 提供 Memcached & Redis 兩個 cache engine 選項
僅有 Redis 可以提供 Master/Slave replication & cross-AZ redundency 的架構;而 Memcached 僅有 single AZ
若要減輕 DB 存取壓力/負載,那使用
Elasticache是正確的處理方式;但若是要減輕運行 OLAP transaction 的負載,那Redshift才是正確的選擇