前言
Compute HA 的本質是通過 Redundancy(冗餘) 來規避部分故障的風險
Compute HA 架構的設計複雜度主要體現在任務管理方面:當任務在某台 server 上執行失敗後,如何將任務重新分配到新的 server 執行
架構設計的關鍵點:
- 那些 server 可以執行任務?
- 每個 server 都可以執行任務
- 只有特定 server(通常叫”master”)可以執行任務
- 任務如何重新執行?
- 對於已經分配的任務即使執行失敗也不做任何處理
- 設計一個任務管理器來管理需要執行的計算任務, server 執行完任務後,需要向任務管理器回報任務執行結果
- 那些 server 可以執行任務?
“ Job Scheduler “是一個邏輯的概念,並不一定要求系統存在一個獨立的 Job Scheduler module
主備架構
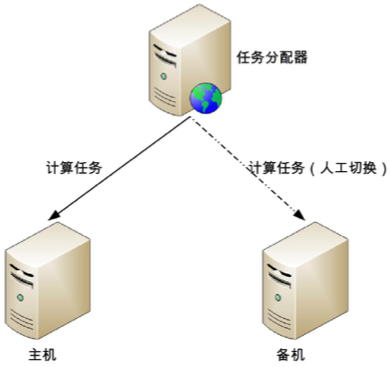
Compute HA 的主備架構無須資料複製
如果主機不能夠恢復,則需要人工操作,將備機升為主機,然後讓 Job Scheduler 將任務發送給新的主機
主備架構的優點就是簡單,主備機之間不需要進行交互,狀態判斷和切換操作由人工執行
人工操作的時間不可控制,操作效率也比較低,可能需要半個小時才完成切換操作,而且手動操作過程中容易出錯
Compute HA 的主備架構也比較適合與內部管理系統、後台管理系統這類使用人數不多、使用頻率不高的業務,不太適合 online 面對眾多使用者的業務
主從架構
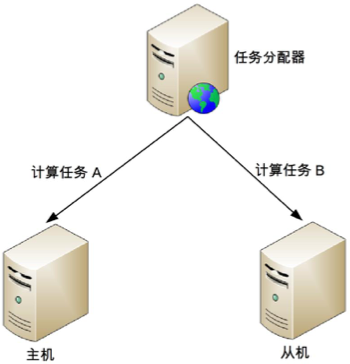
Job Scheduler 需要將任務進行分類,確定哪些任務可以發送給主機執行,哪些任務可以發送給備機執行
主從架構與主備架構相比,優缺點有:
- 優點:主從架構的從機也執行任務,發揮了從機的硬體效能
- 缺點:主從架構需要將任務分類, Job Scheduler 會復雜一些
Cluster 架構
主備架構和主從架構通過冗餘一台 server 來提升可用性,且需要人工來切換主備或者主從,會有以下缺點:
- 人工操作效率低
- 容易出錯
- 不能及時處理故障
根據 Cluster 中 server 節點角色的不同:
- Symmetric Cluster : Cluster 中每個 server 的角色都是一樣的,都可以執行所有任務
- Asymmetric Cluster : Cluster 中的 server 分為多個不同的角色,不同的角色執行不同的任務
在Compute HA Cluster 架構中,2 台 server 的 Cluster 和多台 server 的 Cluster ,在設計上沒有本質區別
storage HA cluster 基本上會是以 3, 5, 7 … 的方式配置
Symmetric Cluster
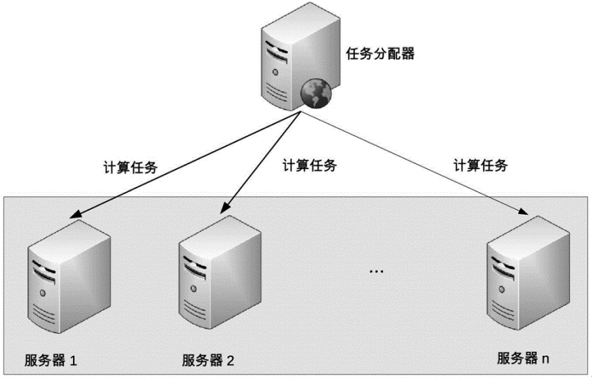
也稱為
負載均衡集群運作行為:
- Job Scheduler 採取某種策略(隨機、輪詢等)將計算任務分配給 Cluster 中的不同 server
- 當 Cluster 中的某台 server 故障後,Job Scheduler 不再將任務分配給它
- 當故障的 server 恢復後,Job Scheduler 重新將任務分配給它執行
設計關鍵點:
- Job Scheduler 需要選定分配策略
- Job Scheduler 需要有能力檢測 server 狀態
狀態檢測稍微複雜一些,既要檢測 server 的狀態(例如:server 是否當機、網路是否正常等);同時還要檢測任務的執行狀態(例如任務是否卡死、是否執行時間過長…等)
不同業務場景的狀態判斷條件差異很大,實際設計時要根據業務需求來進行設計和優化
一個線上系統,正常情況下頁面平均會在 500 ms 內返回,那麼狀態判斷條件可以設計為:1 min 內回應時間超過 1 sec(包括 timeout)的頁面數量佔了 80% 時,就認為 server 有故障
Asymmetric Cluster
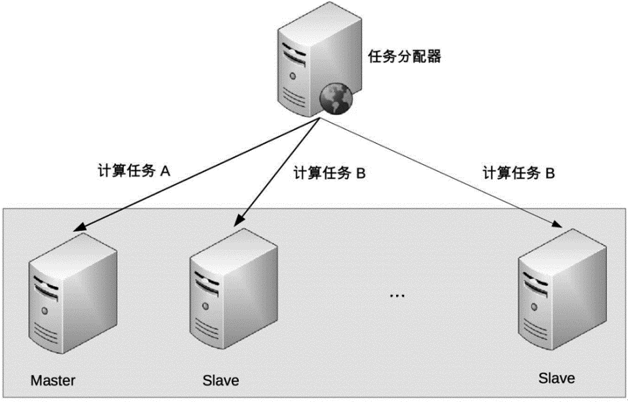
Cluster 中不同 server 的角色是不同的,不同角色的 server 承擔不同的職責;部分任務是 Master server 才能執行,部分任務是 Slave server 才能執行
運作行為:
- Cluster 會通過某種方式來區分不同 server 的角色,例如:ZAB 算法選舉
- Job Scheduler 將不同任務發送給不同 server
- 當指定類型的 server 故障時,需要重新分配角色
與對稱 Cluster 相比,設計複雜度在於:
- 任務分配策略更加複雜:需要將任務劃分為不同類型並分配給不同角色的 Cluster 節點
- 角色分配策略實現比較複雜:例如,可能需要使用 ZAB、Raft 這類複雜的算法來實現 Leader 的選舉
討論整理精華
要想 HA 就離不開 redundancy,無論是 Compute HA 還是 Storage HA 都會面對機器狀態檢測、切換以及機器選擇的問題,在這幾個方面二者複雜度差別不大
對於 compute 而言, Cluster 中的機器間之間基本上是無交互的,對於需要重試的計算任務,是有任務管理器來維護處理;而 Storage HA 還會涉及到機器之間資料的同步和一致性問題,在同步時還需要考慮效能、穩定性、同步中斷、個別失敗、重複同步等問題,因此就會複雜許多
Compute HA 系統需考慮 safety 和 liveness,而 Storage HA 除了前面兩個考量點之外,還受 CAP 約束
Storage HA 比 Compute HA 要複雜的多,存儲高可用是有狀態的,Compute HA 一般解決的都是無狀態問題,有狀態就會存在著如何保存狀態、同步狀態的問題