高可用儲存架構:雙機架構
儲存高可用方案的本質都是通過將數據複製到多個儲存設備,通過數據冗餘的方式來實現高可用
複雜性主要體現在如何應對複製延遲和中斷導致的數據不一致問題,思考的面向有以下幾個:
- 數據如何複製?
- 各個節點的職責是什麼?
- 如何應對複製延遲?
- 如何應對複製中斷?
主備複製
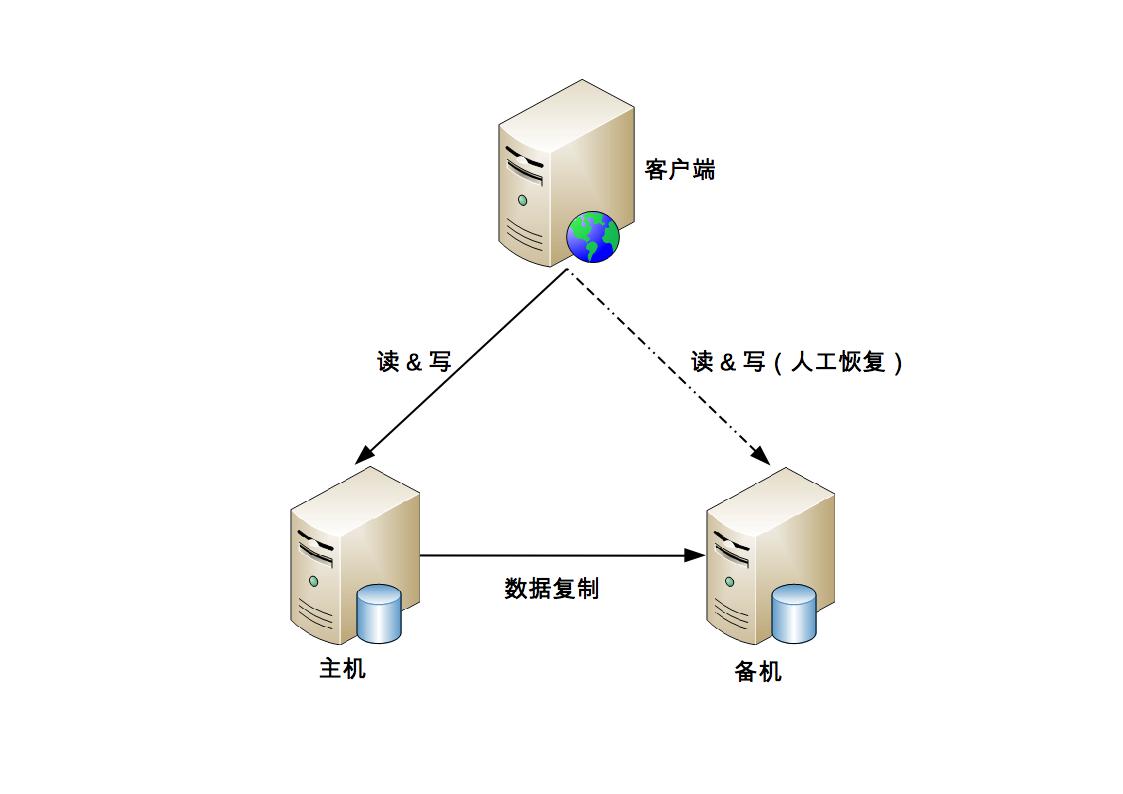
主備複製是最常見也是最簡單的一種儲存高可用方案,幾乎所有的儲存系統都提供了主備複製的功能,例如 MySQL、Redis、MongoDB 等
主備架構中的”備機”主要作為備份用途,並不承擔實際的業務讀寫操作,如果要把備機改為主機,需要人工操作
優點:
- 對於 client 來說,不需要感知備機的存在
- 對於主機和備機來說,雙方只需要進行數據複製即可,無須進行狀態判斷和主備切換這類複雜的操作
缺點:
- 備機僅僅只為備份,並沒有提供讀寫操作,硬體成本上有浪費
- 故障後需要人工干預,無法自動恢復
- 人工在執行恢復操作的過程中也容易出錯,因為這類操作並不常見,實際操作的時候很可能遇到各種意想不到的問題
主從複製
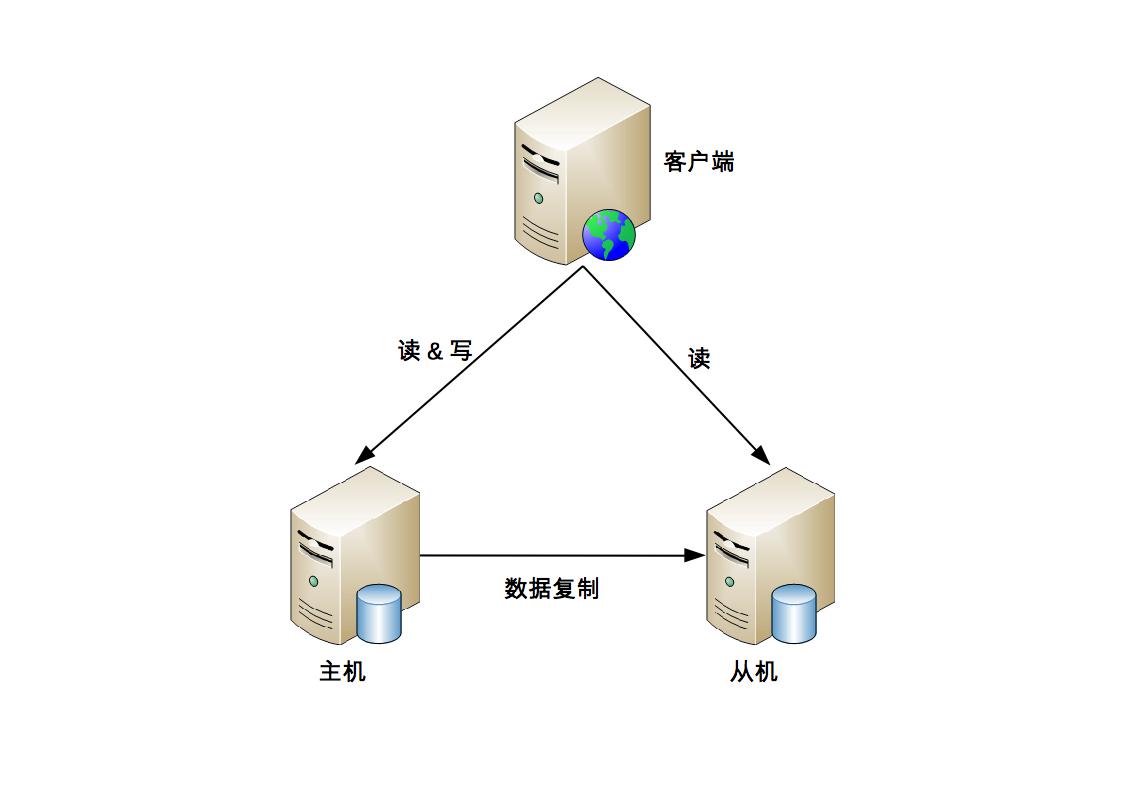
主機負責讀寫操作,從機只負責讀操作,不負責寫操作
與主備複製架構比較類似,主要的差別點在於從機正常情況下也是要提供讀的操作
適合寫少讀多的業務,例如:論壇、BBS、新聞網站 … etc
優點:
- 主從複製在主機故障時,讀操作相關的業務可以繼續運行
- 主從複製架構的從機提供讀操作,發揮了硬體的性能
缺點:
- client 需要感知主從關係,並將不同的操作發給不同的機器進行處理,複雜度比主備複製要高
- 從機提供讀業務,如果主從複製延遲比較大,業務會因為數據不一致出現問題
- 故障時需要人工干預
雙機(主備/主從)切換
前面兩個架構的問題:
- 主機故障後,無法進行寫操作
- 如果主機無法恢復,需要人工指定新的主機角色
雙機切換即是在原有方案的基礎上增加”切換”功能,即系統自動決定主機角色,並完成角色切換
切換方案比複製方案不只是多了一個切換功能那麼簡單,而是複雜度上升了一個量級
設計關鍵
主備間狀態判斷
- 狀態檢測的內容:例如機器是否斷電、process 是否存在、響應是否緩慢…等
- 狀態傳遞的管道:是相互間互相連接,還是第三方仲裁?
切換決策
- 切換時機:什麼情況下備機應該升級為主機?
- 切換策略:原來的主機故障恢復後,要再次切換,確保原來的主機繼續做主機,還是原來的主機故障恢復後自動成為新的備機?
- 自動程度:切換是完全自動的,還是半自動的?
數據衝突解決
- 當原有故障的主機恢復後,新舊主機之間可能存在數據衝突
常見架構
互連式
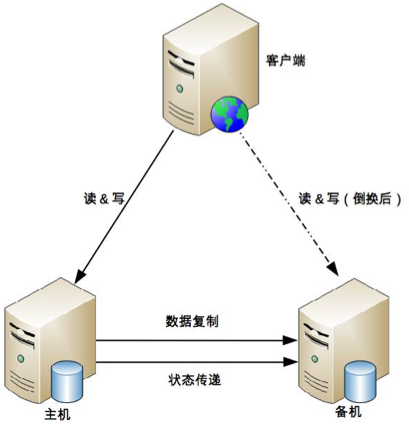
主備機直接建立狀態傳遞的渠道
在主備複製的架構基礎上,主機和備機多了一個”狀態傳遞”的通道,這個通道就是用來傳遞狀態信息的
client 這裡也會有一些相應的改變:
- 主機和備機之間共享一個對 client 來說唯一的地址。例如虛擬 IP,主機需要綁定這個虛擬的 IP
- client 同時記錄主備機的地址,哪個能訪問就訪問哪個;備機雖然能收到 client 的操作請求,但是會直接拒絕,拒絕的原因就是”備機不對外提供服務”
缺點:
- 如果狀態傳遞的通道本身有故障,而此時主機並沒有故障,最終就可能出現兩個主機
- 可以通過增加多個通道來增強狀態傳遞的可靠性,但這樣做只是降低了通道故障機率而已,不能從根本上解決這個缺點
中介式
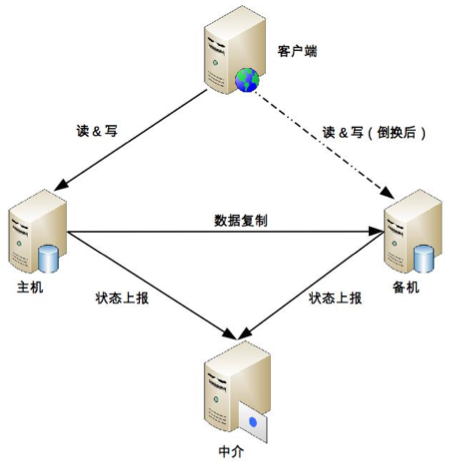
在主備兩者之外引入第三方中介,主備機之間不直接連接,而都去連接中介,並且通過中介來傳遞狀態信息
連接管理更簡單:主備機無須再建立和管理多種類型的狀態傳遞連接通道,只要連接到中介即可,實際上是降低了主備機的連接管理複雜度
狀態決策更簡單:主備機的狀態決策簡單了,無須考慮多種類型的連接通道獲取的狀態信息如何決策的問題
關鍵代價就在於如何實現中介本身的高可用
在工程實踐中推薦基於 ZooKeeper 搭建中介式切換架構,解決中介本身的可靠性問題
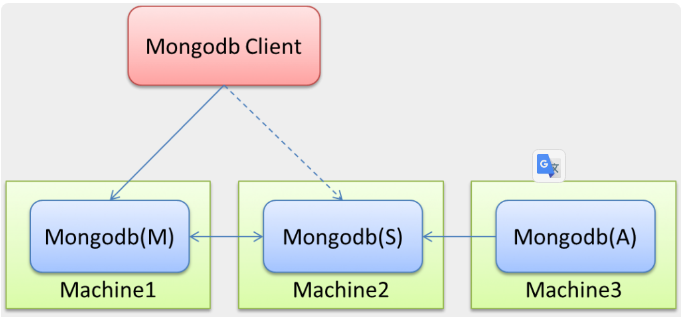
MongoDB(M) 表示主節點,MongoDB(S) 表示備節點,MongoDB(A) 表示仲裁節點
主備節點儲存數據,仲裁節點不儲存數據
client 同時連接主節點與備節點,不連接仲裁節點
模擬式
模擬式指主備機之間並不傳遞任何狀態數據,而是備機模擬成一個 client ,向主機發起模擬的讀寫操作,根據讀寫操作的響應情況來判斷主機的狀態
實現更加簡單,因為省去了狀態傳遞通道的建立和管理工作
模擬式讀寫操作獲取的狀態信息只有響應信息(例如,HTTP 404,超時、響應時間超過 3 秒等),沒有互連式那樣多樣(例如:CPU 負載、I/O 負載、吞吐量),基於有限的狀態來做狀態決策,可能出現偏差
主主複製
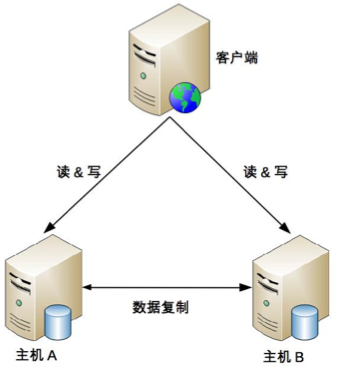
兩台都是主機,不存在切換的概念,互相將數據複製給對方
client 無須區分不同角色的主機,隨便將讀寫操作發送給哪台主機都可以
主主複製架構從總體上來看要簡單很多,無須狀態信息傳遞,也無須狀態決策和狀態切換,但有其獨特的複雜性
如果採取主主複製架構,必須保證數據能夠雙向複製,而很多數據是不能雙向複製的(例如:按照數字增長的 ID、庫存、餘額…etc)
主主複製架構對數據的設計有嚴格的要求,一般適合於那些臨時性、可丟失、可覆蓋的數據場景,例如:用戶登錄產生的 session 數據(可以重新登錄生成)、用戶行為的日誌數據(可以丟失)、論壇的草稿數據(可以丟失)…etc
討論整理精華
政府信息公開網站的特點:
- 用戶量和QPS不會很大
- 其次讀/寫都非常少,讀相較於寫多
- 可忍受一定時間範圍的不可用
主主架構因其固有的雙向複雜性,很少在實際中使用;再加上此場景並不適合用主主架,故排除使用它。
根據第 3 個特點就可以排除使用雙機互換架構。
對於主備架構來說,主機正常時,備機不提供讀寫服務,比較浪費
綜合來看,選擇主從的儲存架構
高可用儲存架構:集群和分區
數據集群
主備、主從、主主架構本質上都有一個隱含的假設:主機能夠儲存所有數據,但主機本身的儲存和處理能力肯定是有極限的
集群就是多台機器組合在一起形成一個統一的系統,這裡的”多台”,數量上至少是 3 台
數據集中集群
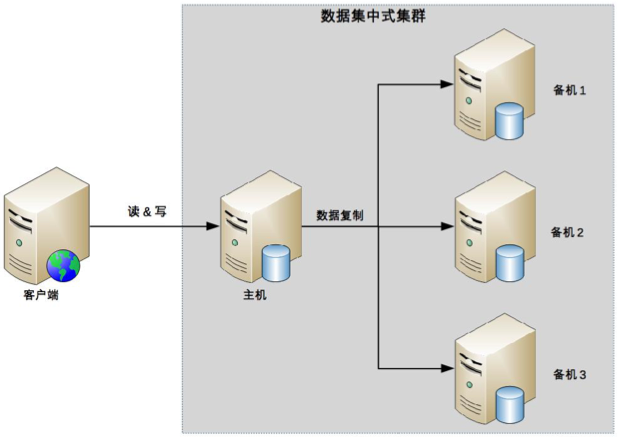
數據集中集群為 1 主多備或者 1 主多從
數據都只能往主機中寫,而讀操作可以參考主備、主從架構進行靈活多變
複雜度整體更高一些,具體體現在:
- 主機如何將數據複製給備機:多條複製通道首先會增大主機複製的壓力
- 備機如何檢測主機狀態:多台備機都需要對主機狀態進行判斷,而不同的備機判斷的結果可能是不同的
- 主機故障後,如何決定新的主機
數據分散集群
多個 server 組成一個集群,每台 server 都會負責儲存一部分數據
為了提升硬體利用率,每台 server 又會備份一部分數據
複雜點在於如何將數據分配到不同的 server 上,算法需要考慮這些設計點:
- 均衡性
- 容錯性:當出現部分 server 故障時,算法需要將原來分配給故障 server 的數據分區分配給其他 server
- 可伸縮性:當集群容量不夠,擴充新的 server 後,算法能夠自動將部分數據分區遷移到新 server ,並保證擴容後所有 server 的均衡性
數據分散集群和數據集中集群的不同點 => 數據分散集群中的每台 server 都可以處理讀寫請求,因此不存在數據集中集群中負責寫的主機那樣的角色
數據集中集群架構中,client 只能將數據寫到主機;數據分散集群架構中,client 可以向任意 server 中讀寫數據
必須有一個角色來負責執行數據分配算法
- Hadoop 的實現就是獨立的 server 負責數據分區的分配,這台 server 叫作 Namenode
- Elasticsearch 集群通過選舉一台 server 來做數據分區的分配,叫作 master node
數據集中集群適合數據量不大,集群機器數量不多的場景
數據分散集群,由於其良好的可伸縮性,適合業務數據量巨大、集群機器數量龐大的業務場景
數據分區
對於一些影響非常大的災難或者事故來說,有可能所有的硬體全部故障,因此需要基於地理級別的故障來設計高可用架構,這就是數據分區架構產生的背景
將數據按照一定的規則進行分區,不同分區分佈在不同的地理位置上,每個分區儲存一部分數據,通過這種方式來規避地理級別的故障所造成的巨大影響
數據量
數據量的大小直接決定了分區的規則複雜度
數據量越大,分區規則會越複雜,考慮的情況也越多
- 故障出現時,不容易定位
- 增加新機器,分區配置調整可能會發生錯誤
- 還要考慮地理區域級別的容災
分區規則
地理位置有近有遠,因此可以得到不同的分區規則,包括洲際分區、國家分區、城市分區
具體採取哪種或者哪幾種規則,需要綜合考慮業務範圍、成本等因素
複製規則
每個分區本身的數據量雖然只是整體數據的一部分,但還是很大,這部分數據如果損壞或者丟失,損失同樣難以接受
即使是分區架構,同樣需要考慮複製方案
集中式
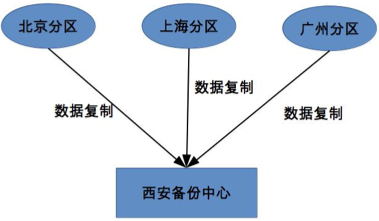
集中式備份指存在一個統一的備份中心,所有的分區都將數據備份到備份中心
優點:設計簡單、擴展容易
缺點:成本較高
互備式
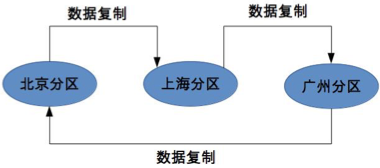
指每個分區備份另外一個分區的數據
優點:成本低
缺點:設計比較複雜、擴展麻煩
獨立式
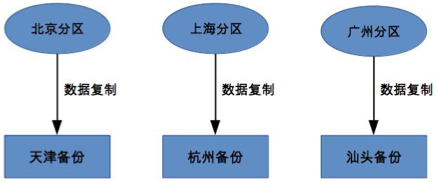
每個分區自己有獨立的備份中心,並不和原來的分區在一個地方
主要目的是規避同城或者相同地理位置同時發生災難性故障的極端情況
優點:設計簡單、擴展容易
缺點:成本高,每個分區需要獨立的備份中心
討論整理精華
數據集群可以做到在不同節點之間複製數據,確保當一個集群斷網斷電的情況下,仍然有機房可以讀取數據
在對外提供服務時不僅僅考慮是否能讀寫數據,還需要考慮讀寫數據所需的耗時
距離過遠意味著耗時較長,如果是搭建專線,成本也會非常高,因而從
成本和用戶體驗兩個緯度考量遠距離同步集群不適合直接對外提供服務對於城市級數據集群出故障,主要還是通過短距異地(網路耗時在十毫秒級別)集群來解決,遠距離集群主要還是用於做冷備、數據離線比對等功能
數據分散集群具有均衡性,容錯性,可伸縮性特點,響應比較快
遠距離分佈的集群可有如下特點:
- 更容易出現不可用性,具體表現在業務響應慢,數據讀/寫/複製延遲高
- 一致性也難保證
- 也難保證均衡性,容錯性,可伸縮性特點
- 複雜度較近距離的集群呈現指數級增長