Kubernetes 的前身 - Google Borg
Kubernetes 源自於 Google 內部的 Borg,因此看看原生的 Borg 會有助於從大方向了解 Kubernets 架構中的各個 component 是如何協同運作的,以下是 Borg 的系統架構:
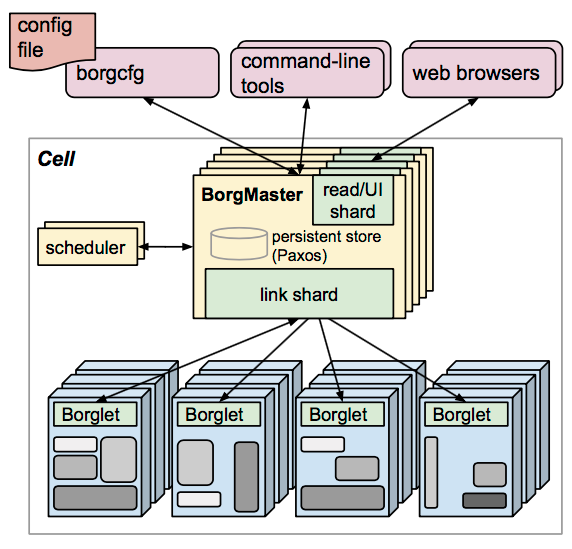
從上面的架構圖可以看出幾個重點:
BorgMaster
BorgMaster 是整個系統的大腦,用來負責與系統中的不同元件進行溝通,確保系統可以正常運作。
Borglet
這是在每個 host 中負責管理 container 生命周期的元件,接收來自 BorgMaster 的命令並進行相對應的操作。
Scheduler
負責進行任務的調度,根據不同應用的需求,將 workload 調度到不同的機器去執行。
Paxos (persistent store)
由於整體系統在設計上就是預期會有某些 node 在某些時候會發生故障,因此當要儲存系統運作狀態時,就不會考慮儲存在自身的儲存空間上;因此 Paxos 就是在整個系統中負責儲存系統運作狀態的地方。
borgcfg
用來操作 Borg 系統的 CLI 所使用的設定檔
Kubernets 架構
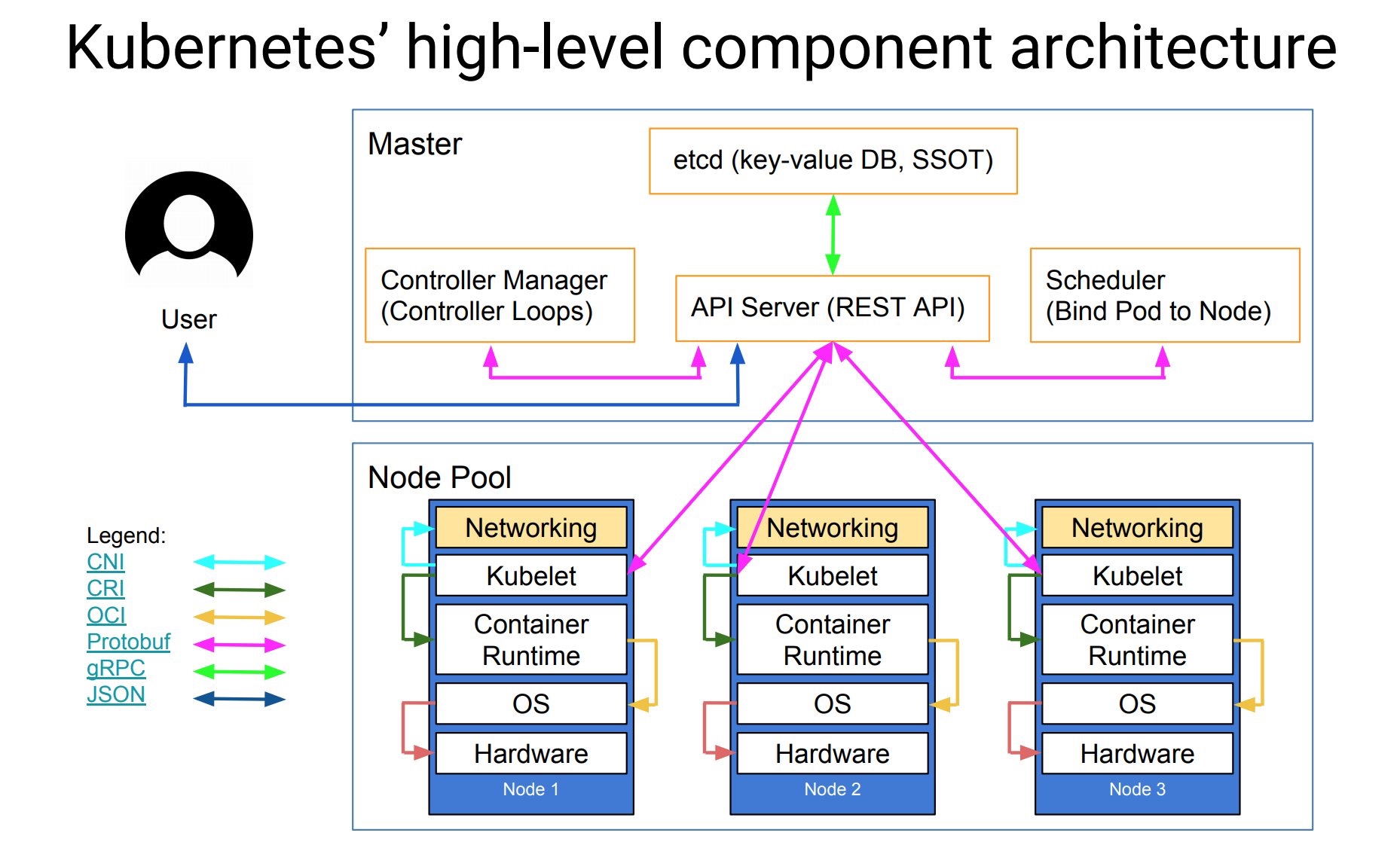
Kubernetes 的架構設計上也極為類似 Borg,如下圖所示:
在把上面複雜的架構圖抽象化一點:
從上圖可以看出以下結論:
不論是透過 CLI or UI,都只能透過呼叫 API 的方式與 Kubernetes 溝通
master node 收到 API request 後,針對使用者需求對後面的 worker node 進行指定的工作(透過 kubelet)
worker node 到 master node 的溝通,僅能透過 API server 作為窗口,kubelet 是無法存取到 master node 上的其他元件
唯一可以存取 etcd 的只有 REST service(kube-apiserver)
外部的到 worker node 的 traffic 則是由 kube-proxy 來負責處理,將流量導到正確的 pod 上
接著以下用不同 node type 的角度來切入進行細部檢視:
Master Node
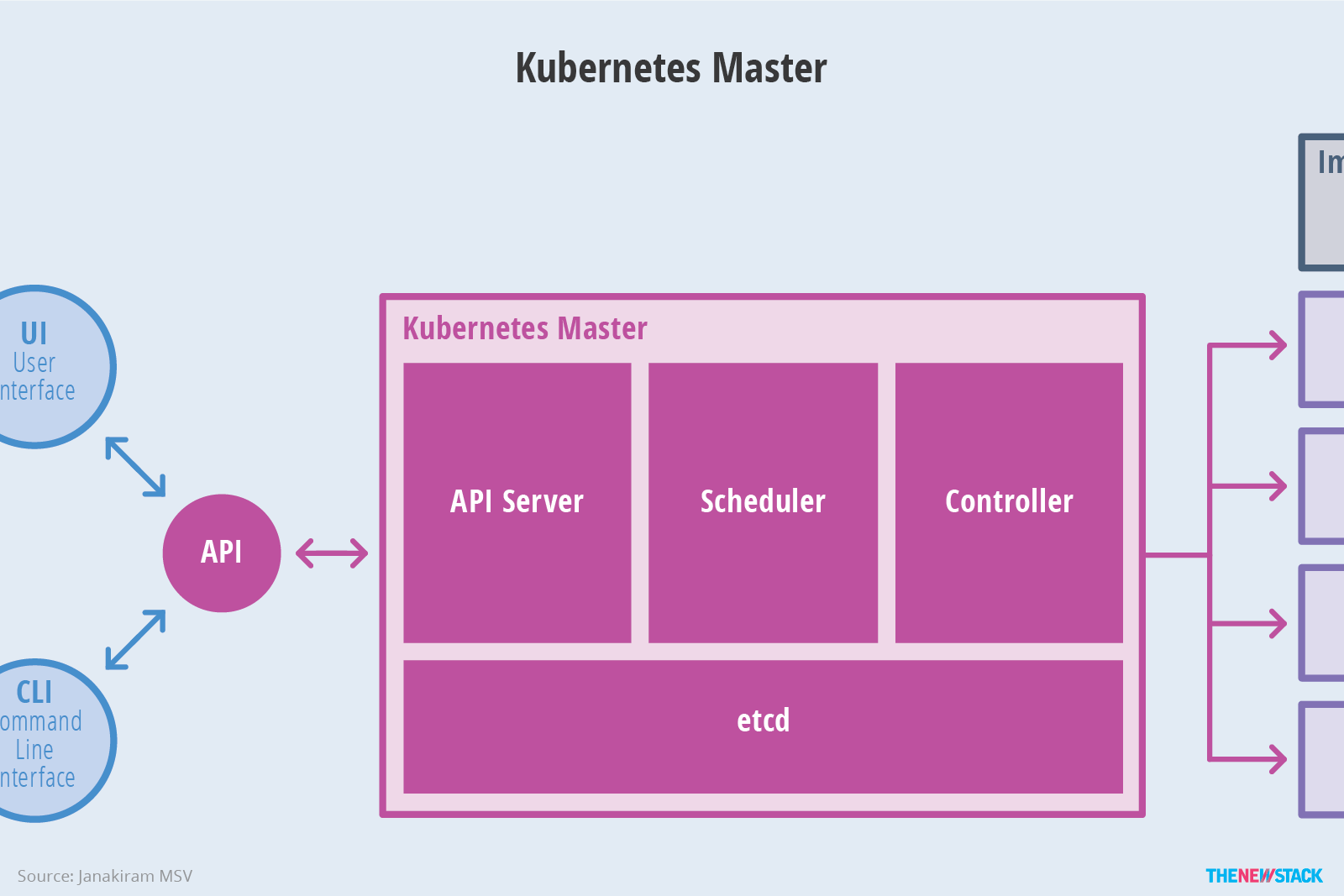
在 master node 上有幾個相當重要的 component 分別是:
API server
此為所有資源操作的唯一入口,並負責 Authentication、Authorization、Access Control、API registration & discovery。
Scheduler
負責進行任務的調度,根據不同應用的需求,將 workload 調度到不同的機器去執行。
Controller Manager
負責維護 cluster 的狀態,包含 failure detection、auto scale in/out、rolling update …. 等等。
etcd
負責保存整個 cluster 的運行狀態
若 cluster 的 node 數量龐大,etcd 也有可能會被獨立於 master 之外來單獨安裝。
Worker Node
在 Kubernetes 中,worker node 也稱為 minion,可以是實體機或是 VM,以下是 worker node 的架構圖:
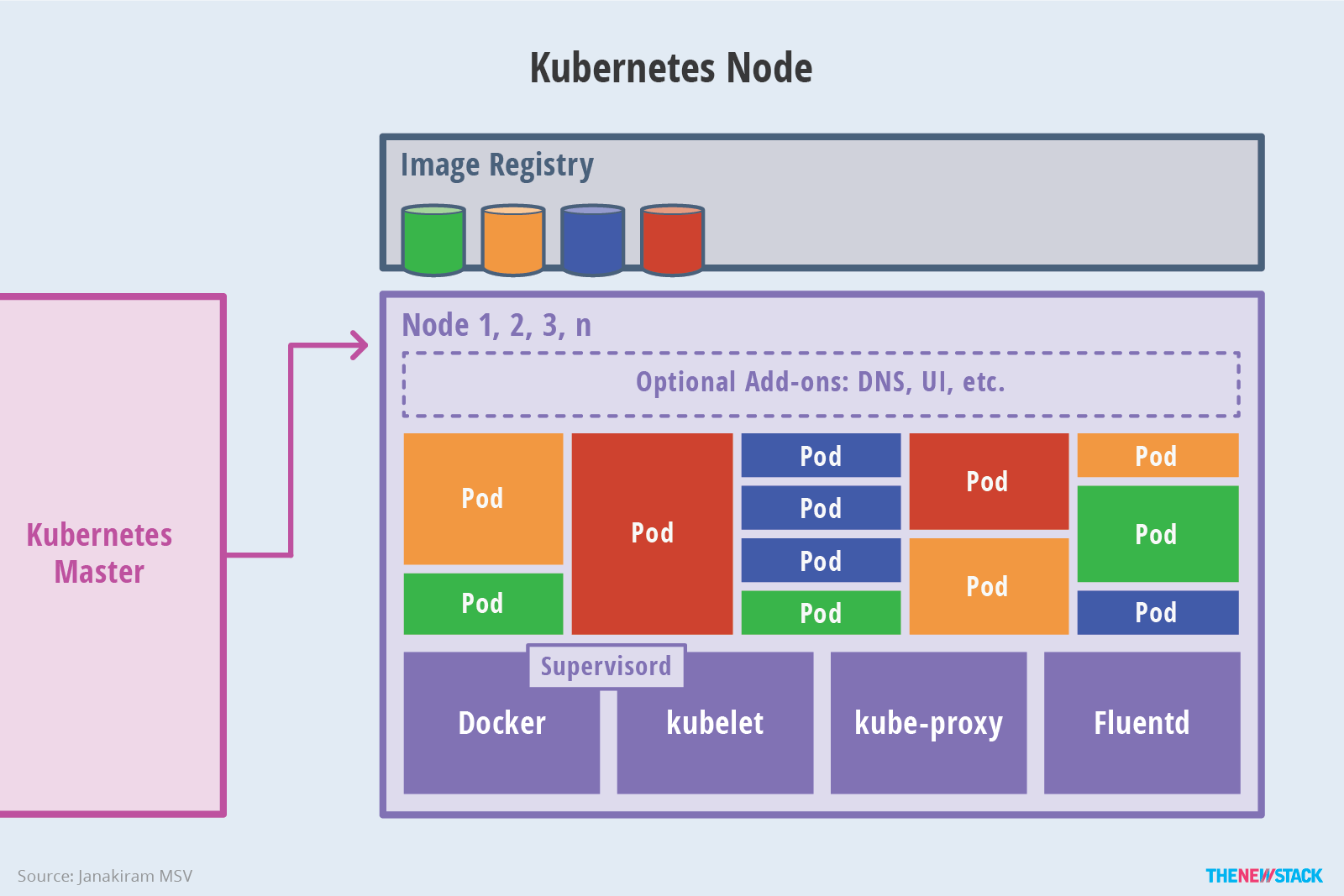
Container Runtime
負責 container image 的管理並透過 CRI(Container Runtime Interface) 來管理 pod 的運行。
大部份時候會以 Docker 作為 container runtime,但其實可以作為 container runtime 的除了 Docker 之外,還有以下幾個選項:
CRI-O - OCI-based implementation of Kubernetes Container Runtime Interface
Frakti - The hypervisor-based container runtime for Kubernetes
kubelet
負責接收來自 API server 的命令、維護 container 的生命周期,並負責 CSI(Container Storage Interface) & CNI(Container Network Interface) 的管理。
kube-proxy
在 Kubernetes 中,service 將多個 pod 抽象化成一個單一群組,並為此群組提供一個 virtual IP,並提供其他 pod or service 進行存取。
而 kube-proxy 就是負責在 host 中針對 service 與 pod 的配置設定,產生相對應的 iptables rule,讓送到 service virtual IP 的流量可以正確的導向 service 後端的 pod 中。
因此總結來說,kube-proxy 就是負責為 service 提供 cluster 內部的 service discovery & load balance
核心元件之間的通訊
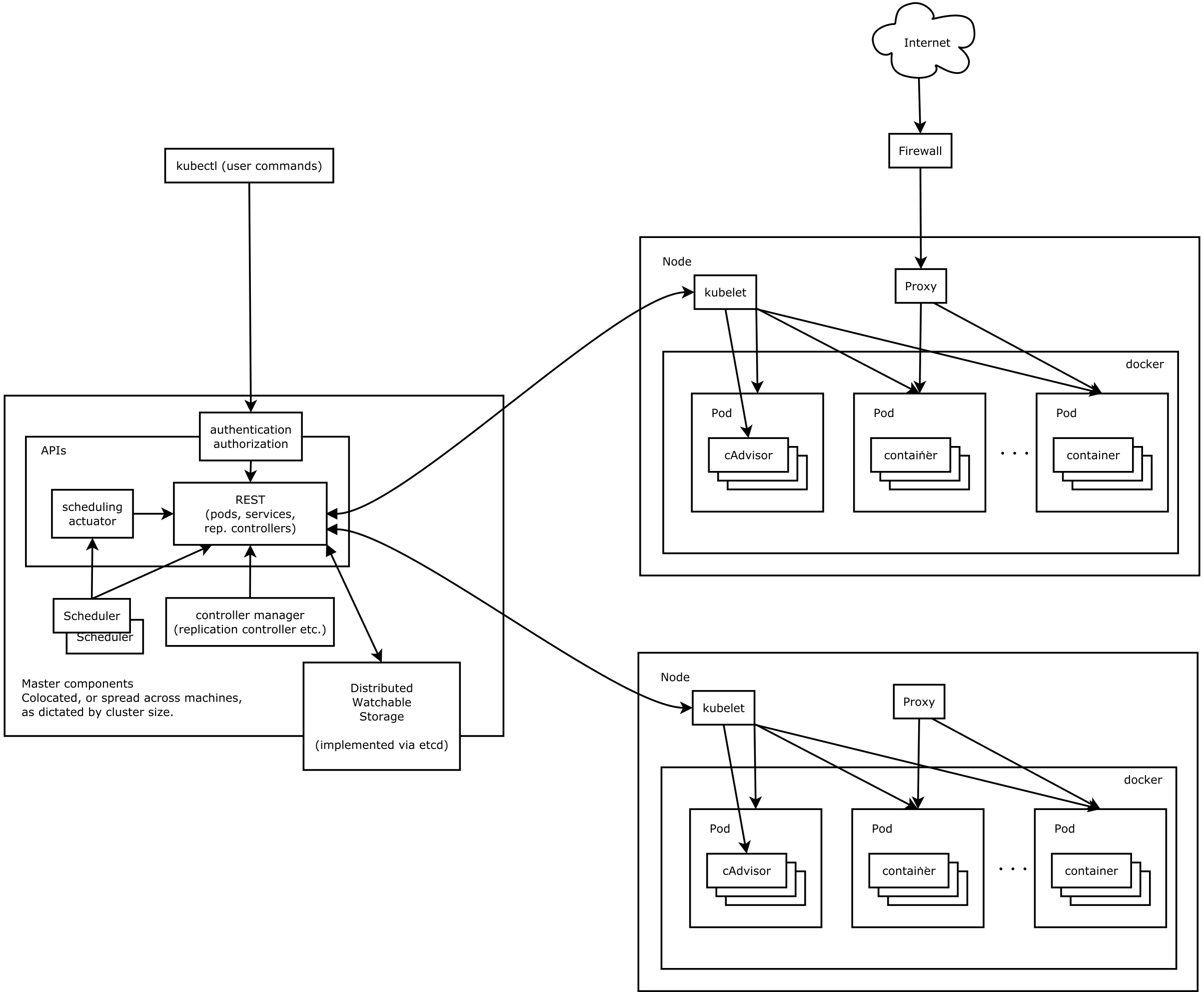
接著來探討一下 Kubernetes 核心元件之間的通信細節,以下面的圖片進行說明:
External <–> Master
- 管理者從外面僅能透過 API server 進行對 Kubernetes cluster 的管理 (傳送 JSON 格式的資料)
Inside Master
不論是負責管理 cluster 狀態的 controller manager,或是負責任務調度的 scheduler,要調整 worker 的工作狀態,都必須透過送 request 給 API server,再由 API server 統一對 host 上的 kubelet 進行操作 (這幾個元件之間傳送的資料格式為 protobuf)
在 master node 中的元件,唯一會對 etcd 服務進行 cluster 狀態存取的僅有 API server,雙方使用 gRPC 進行通訊
Master <–> Worker
- 所有對 worker node 上的狀態變更,都是由 master node 上的 API server 所發過來,並由 kubelet 接收後進行處理 (透過 protobuf) 資料格式傳送資料)
Inside Worker
kubelet 透過 CRI(Container Runtime Interface),控制 container runtime 進行 pod 的管理
contain runtime 則是透過符合 OCI(Open Container Initiative) 介面,在 OS 中實際的產生出相對應的 container
kubelet 透過 CNI(Container Network Interface),呼叫 CNI plugin 來進行 pod network 的設定
Add-Ons
除了上面在 master & worker node 上的核心元件外,還有一些 add-on 可以讓 Kubernetes 運作的更好,例如:
Ingress controller:負責讓外部的流量可以正確的導到 Kubernetes 內部的 service
Resource Monitoring:原先是由 Heapster 來負責,但由於 Prometheus 從 CNCF 變成正式專案後,在 resource monitoring 這個部份開始推薦使用 Prometheus 來實現
Dashboard:為了提供使用者更好的體驗,除了 Kubernetes 官方正式維護的 Dashboard 之外,也可以考慮其他的選項,例如:Cockpit or Rancher(透過 import Kubernetes Clusters 的功能)
當然上面的 add-on 並不是全部,詳細的 add-on 清單可以到 Kubernetes 的專案中去查詢。