What is Job & CroneJob?
Kubernetes Job 就像 Linux at 一樣,是個執行一次性工作的手段,而 Kubernetes CroneJob 也就跟 Linux CronJob 一樣,是個定期執行特定工作的手段。
但回到 k8s 本身來看,Job & CroneJob 這兩件事情是如何被完成的?
Job
在 k8s 中,一個 Job 會建立一個 or 多個 pod 來執行工作,並確保指定數量的 pod 有成功的完成工作並終止。
這代表 k8s 會去追蹤 Job pod 執行的狀態,並確保有成功的執行完成,當指定數量(例如: 5 個中的其中 3 個)的 Job pod 完成工作後,這個 Job 就會被註記為 complete。
因此換個角度來看,透過 Job 來建立 pod 執行工作的目的,是為了確保工作一定有完成,若是因為特殊原因(例如: node hardware failure, node reboot) 而造成 pod 無法正常完成工作,Job 則會自動啟動新的 pod 來繼續完成工作。
此外,Job 還有以下特性:
當 Job 被刪除時,所有相關的 pod 也都一併會被刪除
Job 可以同時執行多個 pod 來完成多個工作
CronJob
試試第一個 Job
有了以上的概念後,接著要來試試看執行第一個 k8s Job,使用以下定義:
1 | apiVersion: batch/v1 |
以下是操作 Job 的過程:
1 | # 可以儲存成本地檔案執行 or 執行以下指令也可 |
如何正確的撰寫 Job
以下用一個範例來做說明:
1 | # apiVersion, kind, metadata 這3個欄位是必須的 |
關於 Job 的平行處理
Parallel Job Type
由於平行處理的部份稍微複雜點,因此把這個部份額外拉出來說明,Job type 共分為三種:
非平行處理的工作
一般同時間只會有一個 pod 啟動做事情,除非有 pod 工作執行失敗
當 pod 成功終止後,job 狀態便轉為完成
帶有固定完成數量的平行處理工作
同時平行處理的工作數量是由
.spec.parallelism所設定在
.spec.completions中有設定完成的數量(必須是大於零的整數值)當 successful pod 的數量到達
.spec.completions所設定時,這個 job 的狀態就會轉換為完成
以上面的例子作示範,會有類似以下的輸出結果:
1 | $ kubectl get all |
基本上 job pod 會一直長出來執行工作,一直到 DESIRED = SUCCESSFUL 為止。
與 work queue 搭配的平行工作
不需要設定
.spec.completions,此時會預設為 .spec.parallelism = .spec.completions需要透過外部的服務來協助執行
這部份的應用目前不是很清楚對應的實際範例,之後若有對這部份更詳細的了解,再回來補齊
Parallel Job Control
基本上,.spec.parallelism 可以設定為任何非負整數值,若是沒有設定的話,則預設為 1,若設定為 0,則表示 Job 暫停,直到被改成大於 0 為止。
然而,實際上同時執行的工作數量可能會少於 .spec.parallelism 所指定的值,可能的原因如下:
若有設定
.spec.completions,同時執行的 job 數量加上已經成功完成的 job 數量就不會超過這個數字,因此到後面會愈來愈少 job 同時執行若是 work queue jobs,若是有任何的 pod 已經成功結束,就不會再有新的 pod 產生
controller 可能沒空回應請求
因為某些原因造成無法再建立新的 pod (例如: ResourceQuota 不足 or 權限不足)
因此若有想要使用 pod 來執行 parallel job,需要注意的地方其實是很多的。
當 Pod or Container 無法成功執行
只要是人寫出來的程式,總是會有 bug 的,因此 container 中的程式執行時發生錯誤而造成 exit code 大於 0 的狀況也是時常會發生,因此程式開發者就必須要了解到在 k8s 中有什麼機制可以來處理這樣的狀況。
Restart Policy
這個部份的設定來自於 .spec.template.spec.restartPolicy,當 Container 工作執行失敗時,k8s 會進行處理的方式,而:
OnFailure:pod 依然會待在原本的 node 上,但 pod 中的 container 會重新啟動;而 application 的開發者必須要撰寫相關程式碼處理當 fail 後,重新啟動時要如何恢復正常狀態的工作Never:此時 container 不會再重新啟動,就維持失敗的狀態
最後 pod 中的 container 若是有全部成功執行,pod 的狀態就會變成 complete,反之則是 failed。
接著是當 Pod 的部份,首先下圖說明 pod life cycle:
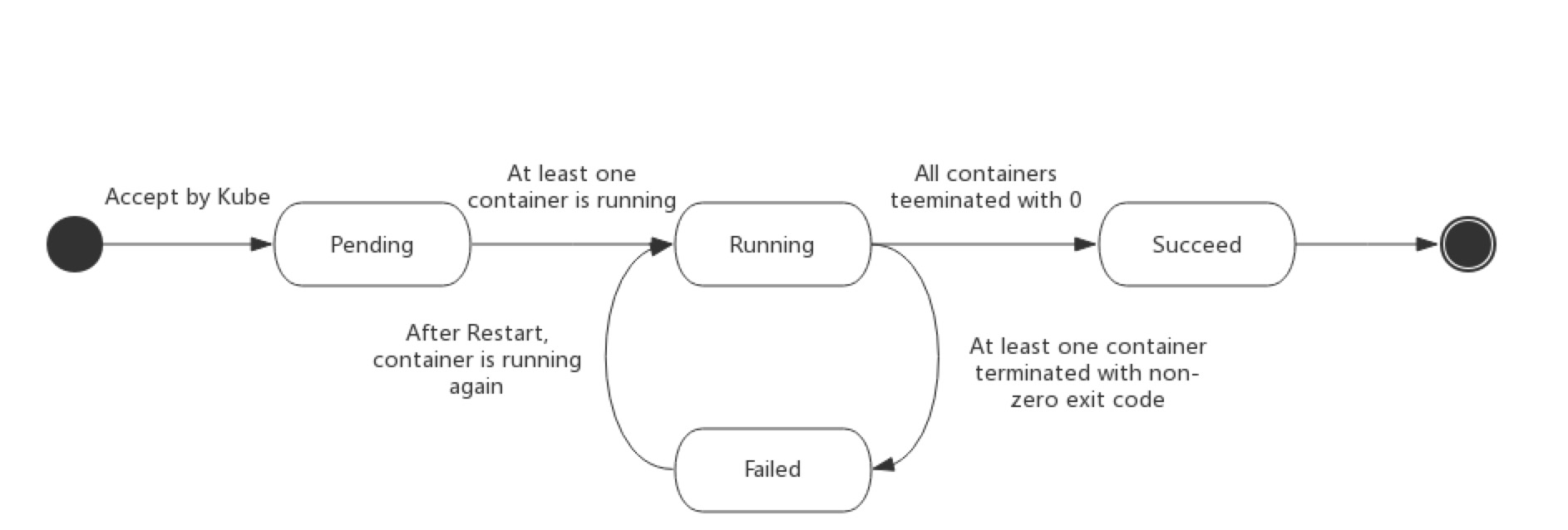
可以看出當 pod 被判定為 failed,k8s 會自動將其重新啟動並回到 Running 的狀態;而因為不明原因重新啟動後,為了要讓 application 能夠恢復到正常運作的狀態,可能需要處理暫存檔、lock、未完成的輸出…等等,則是 application 開發者需要自己寫程式處理。
restart policy 是套用在 container 上而非 pod,因此即使
.spec.template.spec.restartPolicy = "Never",不是因為 container exit code > 0 造成的失敗還是會讓 pod 重新啟動 (例如: node failed)
因此了解了以上 k8s 的處理邏輯後,就可以得出以下結論:
即使設定
.spec.parallelism = 1+.spec.completions = 1+.spec.template.spec.restartPolicy = "Never",同樣的程式可能還是會執行兩次(因為 pod failed 造成的重新啟動),因此程式設計師永遠需要考慮程式執行第二次以上時所需要的額外處理若
.spec.parallelism = 1&.spec.completions = 1皆大於 1,此時就會有多個 pod 同時運行的狀況發生,因此 application 開發者也要妥善處理程式同時多個運作時的相互溝通問題
Backoff Limit
當 pod failed 之後的重新啟動,在 k8s 中稱為 backoff,但每一次的重新啟動會稍微延長 delay 的時間,從 10s, 20s, 40s … 等比例上升,一直到達 5 mins 為止,而這個 delay 的數字會在 pod 成功執行 10 mins 後重置。
Job Termination
要終止 job pod 的方式除了上面所提到的,不斷的 pod failed 造成達到 backoff limit 之外,還可以設定 .spec.activeDeadlineSeconds 來直接設定 job 可存活的時間,而 activeDeadlineSeconds 的優先權大於 backoffLimit
若是觀察 activeDeadlineSeconds 比 backoffLimit 提早發生,可使用下面的範例:
1 | apiVersion: batch/v1 |
若要觀察
backoffLimit比activeDeadlineSeconds提早發生,則可將數字調整成3&300
如何清除執行完的 Job
當 job 完成後,不會再有 pod 被產生,原本已經存在的 pod 也不會被刪除,而保留這些 pod 可以用來檢視有沒有特別的錯誤或是警告、察看相關的 log 或是診斷輸出之類的訊息。
然而這些資料也許很多不會需要永久保存,如果沒有進行清理的話,整個系統就會被很多不需要的資訊佔據,因此 k8s 提供了幾個方式可以讓使用者作清理的工作:
手動使用 kubectl
這個很直覺,以上面的例子來說,就是執行類似下面兩個指令即可:
1 | # 指定 name,刪除特定的 job |
自動清理 Job
如果可以自動完成,誰想要手動呢? 而自動的方式可以有兩種,其中的第一種是利用 CronJob 來管理 Job,並利用 CronJob 的特性定期的清理不需要的 Job 資訊。
另一種則是在 v1.12 提出來的 TTL(Time to Live) 的機制,在 v1.12 中新增了一個 TTL controller 來實現 TTL 的功能,透過設定 .spec.ttlSecondsAfterFinished 欄位來設定 TTL,以下是一個設定範例檔:
1 | apiVersion: batch/v1 |
而 TTL controller 在移除 Job 會連同所以相關的 resource object(例如: pod) 一同移除,但不會全然暴力移除,若是有設定 finalizer 的話,會先執行完後才會移除相關的 object。
關於 .spec.ttlSecondsAfterFinished 的設定以及對應的運作的規則如下:
假設設定 30,當 Job 執行完後的 30 秒,會被 TTL controller 自動清除
若設定 0,當 Job 執行完畢後會被馬上清除
若沒有設定,Job 則永遠不會被清除
注意! 這功能只有 v1.12.0 以後可用,而且需要啟用 feature gate
TTLAfterFinished
如何在 Job 指定 pod selector?
一般來說,建立 job 時是不需要設定 .spec.selector,即使設定了 API server 也會回報錯誤給你,讓你知道這件事情是不被允許的;而這樣的作法是為了確保 Job 產生出來的 pod 中的 .spec.selector 不會互相重複而造成問題,因此 Job pod selector 統一由 k8s 自動來分配。
但如果在某些時候真的需要覆寫這些自動產生出來的 pod selector 資訊時,要怎麼做? 這問題的答案當然還是要回頭設定 .spec.selector,但方法有些不同。
首先要說明要採取這樣的行動會有以下幾點需要注意:
必須確保設定的
.spec.selector是獨一無二的若跟其他 job pod selector 有重複,可能會被刪除,或是讓其他 job 在計算完成數量時發生錯誤(畢竟 k8s 都是靠 selector 在完成這些事情的)
若 pod selector 跟其他 controller(例如: replication controller) 所管理的 pod 相同時,可能會有無法預期的事情發生
k8s 本身並不會阻止你設定有問題的 pod selector,因此這部份需要自己確認好
接著要說明如何自訂 .spec.selector (嚴格來說並不全然算自訂)。
首先假設有個名稱為 old 的 job 已經正在運行,已經有部份的 pod 被啟動並執行中,有些 pod 還沒開始啟動,此時若想要保留原本正在執行的 pod,但又希望後面產生的 pod 可以套用新的 pod template 時該怎麼做?
直接使用 kubectl edit job/old 來完成嗎? 答案是不行的,k8s 不允許更改 job。
正確的流程應該是這樣:
確認 job/old 所自動產生的 pod selector
可以透過 kubectl describe job/old 命令來檢視,假設出現下面的訊息:
1 | kind: Job |
取得上面自動產生的 pod selector(job-uid: a8f3d00d-c6d2-11e5-9f87-42010af00002) 之後,就可以繼續往下做
刪除 job/old
接著可以使用以下指令移除 job,但又保留目前正常執行中的 pod:
kubectl delete jobs/old –cascade=false
重新建立 Job
接著就是修改 job YAML 定義檔,並加入上面取得的 pod selector,並搭配 manualSelector: true(.spec.manualSelector) 的關鍵設定,讓 k8s 同意我們在 job 中自訂 .spec.selector,因此 job YAML 大概會是下面這個樣子:
1 | kind: Job |
接下來 job/new 就可以完全接手原本的 pod 並使用新的 pod template 產生新的 pod 繼續往下執行。
有其他方式執行 Job 嗎?
有人可能會想知道,在 k8s 內是否有其他機制可以來執行所謂”一次性的工作”,當然是有的,只是是不是真的合適的問題而已。
Bare Pod
bare pod 的問題就是掛掉不會自己啟動,而 job pod 會自動幫你重新啟動 pod 並取代原本掛掉的 pod,因此若要確保工作一定會執行完成,還是建議使用 job。
Replication Controller
基本上 job 是 replication controller 的互補。
因為 replication controller 的目的是確保 pod 不會被終止,可以維持使用者所期待的狀態;而 job 正好相反,它會在 job pod 都執行完畢後終止 pod,甚至進行清理。
也因為這樣,在 job 的定義中一定要設定 .spec.template.restartPolicy 為 Never or OnFailure,因為若是不設定的話,預設會是 Always,但這樣就違反了 job 的設計原則了。
Single Job starts Controller Pod
這是最麻煩且完全自幹的方式,在 job pod 中放一個控制用的 container,而這些控制邏輯完全由使用者自己控制。
這樣的方式擁有最大的自主權跟彈性,但這樣就無法有效的與 k8s 提供的機制進行整合。
CronJob
CronJob 其實就是定時執行的 job,但在使用上有一些特性是需要了解的:
一般 CronJob 會在指定的時間執行一次指定的 Job
但也有可能兩個 job 被同時產生出來並執行,這種事情不太常發生,但必須還是要考慮到,因此 job 的執行工作要能夠確保是
idempotent(就像是設計 Ansible playbook 一樣,無論執行多少次工作,都會得到相同的結果)CronJob controller 會檢查從上次產生 job 之後到現在,有多少次 job 被遺漏執行,有漏掉就會補上,但如果這個數目超過 100,CronJob 就不會執行工作CronJob 並回報錯誤
若有設定
startingDeadlineSeconds(假設是 200),那 CronJob 檢查有多少次 job 被遺漏執行時,就只會檢查最近 200 秒所漏掉的 job,而不是上述的狀況若 CronJob 無法在指定時間產生 job pod 來執行工作,就會被判定為
missed(例如:concurrencyPolicy設定為Forbid,但要產生新 job pod 時還有上一個 job pod 正在執行)
最後補上關於 startingDeadlineSeconds 的說明,若是設定 CronJob 在 08:30:00 執行 & 設定 startingDeadlineSeconds 為 600,但又因為某個原因讓 CronJob controller 在 08:29:00 ~ 08:42:00 這一段時間無法運作;在這樣的情況下,會超過 dealine 的設定,因此這個 CronJob 就不會被啟動。
以上述的情況來說,延長 startingDeadlineSeconds 或許是個比較好的處理方式,畢竟晚一點執行總比完全不執行來的好。
關於 TTL Controller
k8s 可以讓使用者執行很多一次性的工作,但執行完成後,即使過程中的 log 或是 resource object 本身都已經不再需要了,它們都還是會一直留在 k8s 上,於是就會看到很多狀態為 Complete(or Failed) 的 resource object,久而久之為了環境不要過度雜亂,可能一段時間就要清理一次,不論是手動 or 寫 script 完成,但其實這是一件挺麻煩的事情。
而在 v1.12 之後,k8s 新增了 TTL controller 這個新功能,目的就是透過限制已經執行完成的 resource object 的生命周期,藉此來達成自動清理的目的;這個設計其實是針對多種不同的 resource object,但在 v1.12 中,僅支援 Job 而已,未來可能或擴充支援到 Pod or Custom Resource。
TTL 在 v1.12 版本中仍是 alpha 而已,且必須透過啟用
TTLAfterFinishedfeature gate 才可使用
如何使用?
使用 TTL controller 的方式就是透過在 Job 上設定 .spec.ttlSecondsAfterFinished,而設定的方式有以下幾種:
設定在 Job 上完建立前
透過 kubectl edit 的方式(or apply -f),設定在 Job 建立後
透過 Admission Webhook 的機制,為未來新增的 Job 建立預設的規則,因此當 Job 建立時,TTL 的設定就可以自動被帶入
透過 Admission Webhook 的機制,為已經完成的 Job,根據 resource status or label 等資訊來動態加入 TTL 的設定