前言
關於 Service,有兩個重點部份是必須先了解的:
當 workload 變成 micro service(pod) 進到 k8s 後,在存取上會遇到什麼問題?
Service 如何解決這些問題?
Pod 存取問題
pod 的生命周期不是並永久的,一旦掛掉之後就不會在自己恢復,因此若使用者針對 pod 有多個 replica 的需求,k8s 中額外設計了像是 ReplicaSet or Deployment 這一類的 resource object 來確保 pod 掛掉之後可以再重啟。
但 pod 重啟以後會發生什麼問題呢? 答案就是 **”IP 也會跟著改變”**。
其實佈署 pod 時也無法指定 IP address
由於 pod IP 可能隨時會變動,因此若是依照傳統 application 的設定方式,使用 ip 設定 DB or web 的位址,上到 k8s 之後可能就很快就無法正常運作,因此 pod 的存取就變成了一個大問題。
Service 如何解決問題?
有鑑於上面的問題,k8s 就提出了 Service 這個 resource object,在 pod 的前方提供了一個抽象層,讓外部的服務可以用 domain name 的方式存取 pod,而 domain name <–> Pod 這一段問題,就由 Service 來處理。
但利用 domain name 來存取終究還是需要一個 IP address,而每個 Service 都會自帶 VIP,讓 network traffic 有辦法正常送過來,並導到後方真正提供服務的 pod。
而當 network traffic 進到 service 後,要決定導到哪些 pod 是要怎麼做呢? 答案則是透過 Label Selector。
定義 Service
搭配 selector
由於要先有 Pod 才會有定義 Service 的需求,因此假設 k8s 中已經有一些 Pod 的存在(同時對外開放 TCP port 9376),並帶有 app=MyApp 的 label,此時就可以定義一個 Service 來作為這些 pod 前方的抽象層,透過 domain name 的方式提供服務:
1 | kind: Service |
透過以上的定義,會產生出以下的 network topology:
1 | Pod <---> Endpoint(tcp:9376) <---> Service(tcp:80, with VIP) |
Service 會為每個符合 label selector 設定的 pod 建立一個 Endpoint 的 resource object 來與之搭配。
此外,在 Service 設定上還有以下有幾個需要額外注意的重點:
若是 targetPort 不設定,預設會與
spec.ports.port相同若 protocol 不設定,預設使用
TCP從 v1.12 開始支援 SCTP(適合用於電信產業 or 提供串流服務時使用),但預設關閉,需要透過
SCTPSupportfeature gate 開啟
不與 selector 搭配
一般 Service 是作為 存取 pod 用的抽象層,但其實作為其他 backend 的抽象層,而這一類的需求可能來自於下列的情況:
在生產環境中有個 external database,但在測試環境中是使用 internal database
想要將 Service 指到位於其他 namespace or cluster 中的 service
想要將某些 workload 移到 k8s 上面跑,但有些 backend service 依然還在 k8s 之外
在以上的情況下,就不需要設定 label selector,因為此時的 service 並不是以 pod 作為 backend service,因此可以透過以下的定義來建立:
1 | kind: Service |
由於沒有設定 label selector,因此也就不會產生相對應的 endpoint,此時我們就需要自己建立一個 Endpoint resource object,並指到真正的 backend service:
1 | kind: Endpoints |
透過以上兩組設定,就可以將到達 my-service 的網路流量導向 1.2.3.4:9376 去。
另外,在設定 Endpoint 時有幾點需要注意:
不能使用 loopback (127.0.0.0/8), link-local (169.254.0.0/16), or link-local multicast (224.0.0.0/24) … 等幾段 IP
也不能使用設定在 k8s 中的 cluster ip 網段
以上的範例的 service type 皆為
ClusterIP;另外還有一種稱為ExternalName,同樣也是沒有 selector 但以 DNS name 為基礎來進行設定
Multi-Port Services
若是 service 想要對外開放多個 port 也沒有問題:
1 | kind: Service |
但相對的後端的 pod 也要有開放多個 port 才有效果
Virtual IPs & service proxies
其實 Service 從 v1.0 開始到現在,在功能面上已經進化了不少,透過了解這些功能的發展歷史,為何新功能會被發展出來? 以及新功能的優缺點 … 等等,使用者可以根據需求選擇適合的 solution。
演進歷史
每個 k8s 的 node 中都會有一個 kube-proxy 的服務,用來處理到達 Service(不包含 ExternalName type) VIP 的網路流量。
而 Service 的發展歷史大概如下:
v1.0:Service 此時作為一個 proxy 且只能進行 layer 4(TCP/UDP over IP) 的處理,而 proxy process 存在於 userspacev1.1:新增了 Ingress,透過 Ingress 可以處理 layer 7(HTTP) 的流量,而 Service 的部份同時也有 iptables proxy mode 新增v1.2:iptables proxy mode 變成 Service 預設的運作模式v1.8:新增 ipvs proxy mode (v1.9 之後變成 beta 功能)
以下說明三種不同的 proxy mode(userspace, iptables, ipvs) 是如何實現,以及每一種的優缺點。
userspace proxy mode
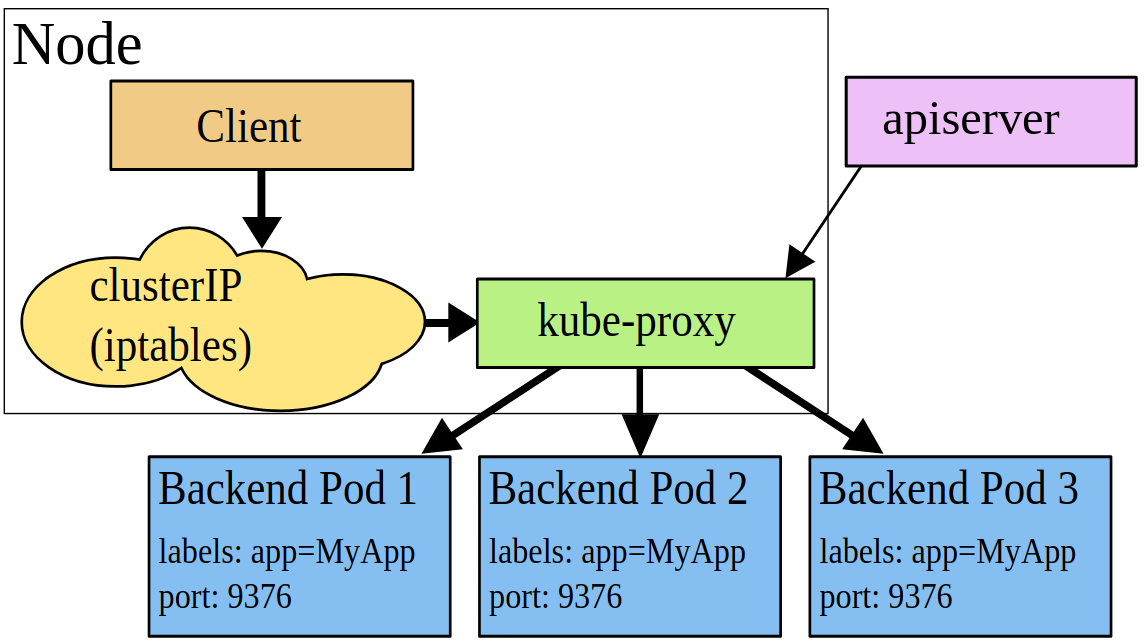
kube-proxy 會為每一個 service 隨機開啟一個 port 在本地端上,任何通往該 port 的網路流量都會經由 kube-proxy 導向後方的 pod(也就是 Endpoint);後來 service 增加了 clusterIP + port 的方式,可以透過 IP:port 的方式存取 service,但所有的網路流量依然會透過 kube-proxy 來導向後方的 pod。
然而這樣的問題在於,由於 kube-proxy 本身是屬於 userspace process,因此實際上網路封包的處理會變成:
service –> kube-proxy(userspace) –> Linux kernel(kernelspace) –> pod(userspace)
一個網路封包必須從 userspace 進入到 kernelspace,再回到 userspace,整體的效能會損耗不少,因此後來才會有其他 proxy mode 的出現。
iptables proxy mode
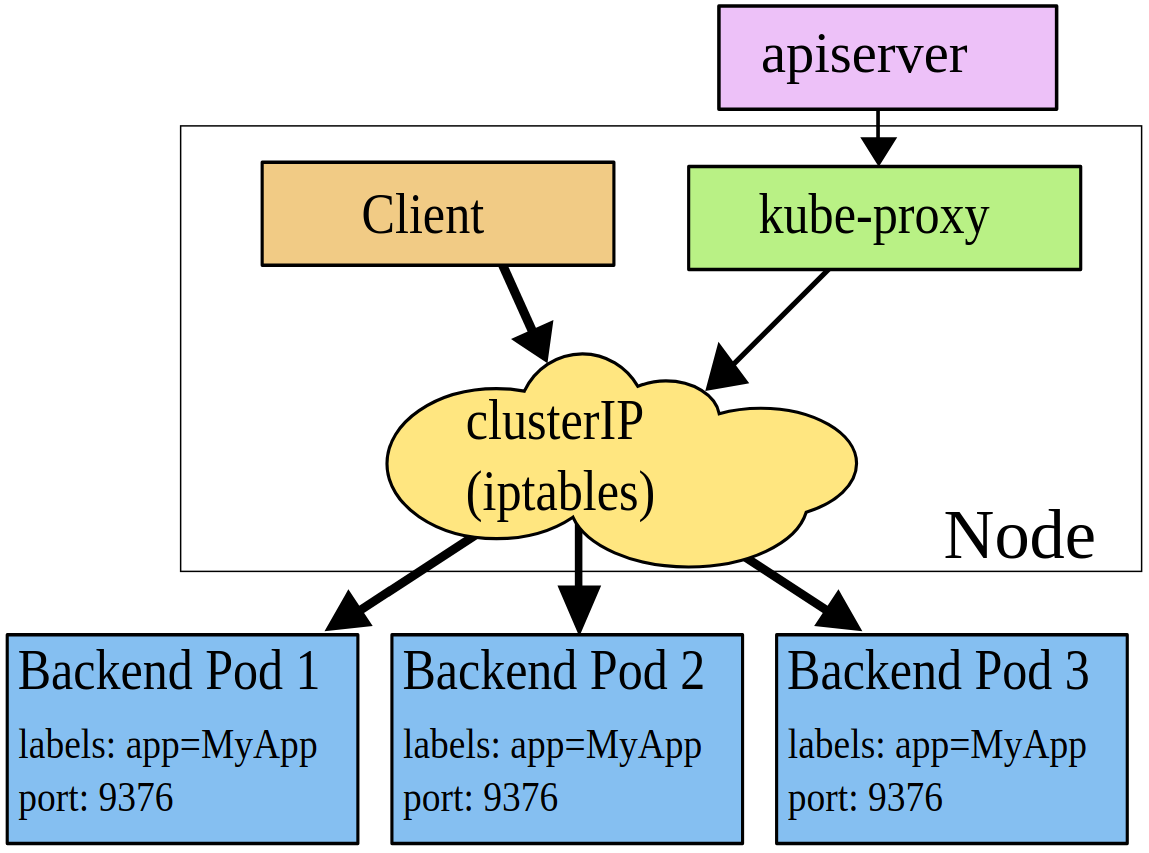
在 iptables proxy mode 中,完全利用了 kernel netfilter 來實現 service 的功能,而每個 service 依然是由 ClusterIP + Port + Endpoint(Pod) 的組合,而這些組合會變成一條一條的 Linux iptables 規則並設定到 k8s cluster 的每一個 node 上
由於所有網路流量都透過 netfilter 處理,因此也就不會有封包在 userspace & kernelspace 中來來回回的狀況發生,也因此效能上比起 userspace proxy mode 會比較好。
當然這樣的作法也產生另外一個問題,就是 Pod 會重啟,那要如何正確的維護 iptables rules?
而這問題的解決方式並不難,只要讓 k8s 知道 pod 是否還可以正常服務即可,我們可以設定 k8s 中的 [Pod Readiness Probes] 來達到此目的。
最後,其實 iptables proxy mode 並沒有解決 performace 的問題,因為當 service & endpoint 的組合的數量龐大時,那就會產生成千上萬的 iptables rules 在 node 上,每個網路封包進來都要比對所有規則,對於資源的虛耗可想而知。
ipvs proxy mode
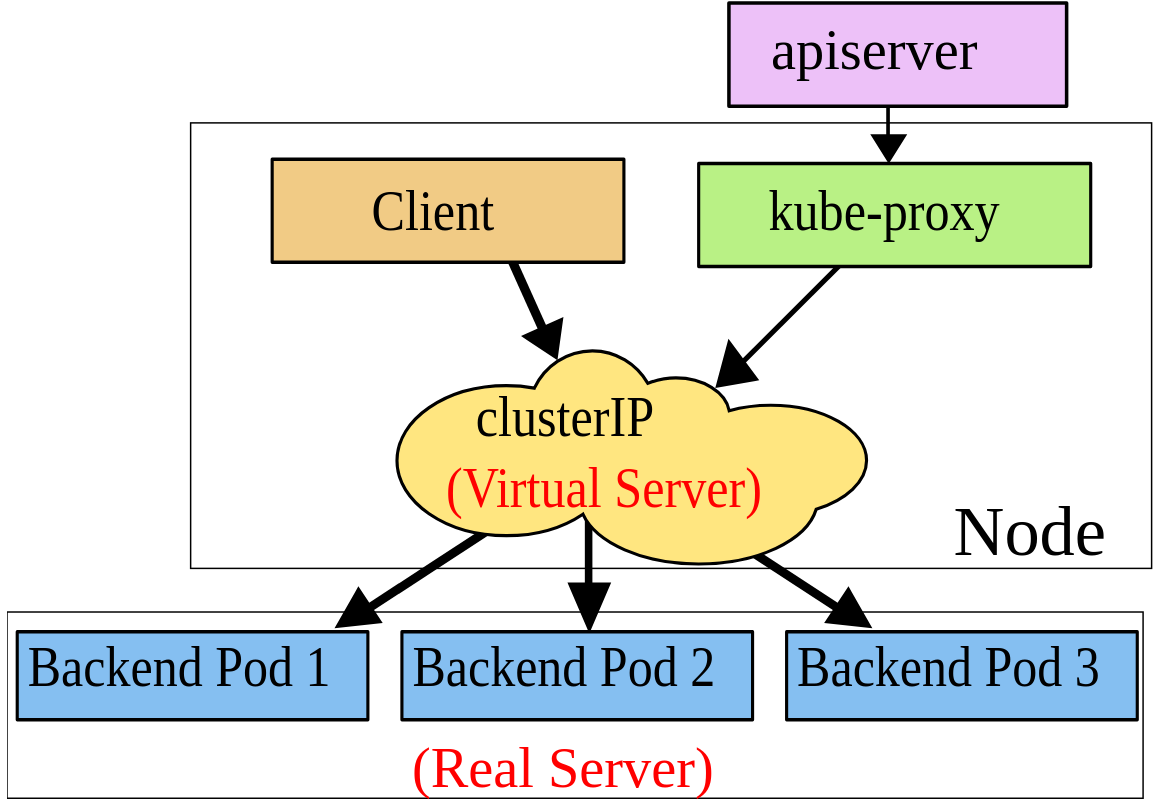
在 ipvs proxy mode 中,kube-proxy 一樣會監控 Service & Endpoint 的變化,並呼叫 netlink 來同步產生對應的 ipvs rules。
跟 iptables 很類似,ipvs 的運作也是基於 netfilter hook function,但在 kernel space 中是搭配 hash table 來運作,因此在效率上比起 iptables proxy mode 快上許多,也不會因為規則變多而讓效能急遽下降。
此外,ipvs 在負載平衡的演算法部份提供了更多選項,例如:rr(round-robin), lc(least connection), dh(destination hashing), sh(source hashing), sed(shortest expected delay) 以及 nq(never queue) … 等等。
在此模式下,任何到達 ServiceVIP:port 的網路封包都會直接被導向後端的 pod,跟 iptables proxy mode 很像,但就是由 virtual server 的角色來處理掉了。
要安裝 ipvs proxy mode 必須安裝 IPVS kernel module 才行,否則會被強制改回 iptables proxy mode
Service Discovery
Service 身為多個 pod 的服務入口,必須要有簡單的方式可以找到這些 Service 才對,在 k8s 中提供了兩種模式來進行 service discovery,分別是環境變數 & DNS。
環境變數
在此模式下,k8s 會在 pod 分派到 worker node 上時,塞進一些與這個 pod 相關的 service 環境變數資訊,並以 {SVCNAME}_SERVICE_HOST & {SVCNAME}_SERVICE_PORT 兩種格式的環境變數存在 pod 中。
假設指定 service redis-master 並開放 TCP port 6379,且 Service cluster IP address 為 10.0.0.11,在 pod 中就會出現以下環境變數:
1 | REDIS_MASTER_SERVICE_HOST=10.0.0.11 |
雖然這個模式不需要 DNS resolution,但會有另外兩個問題:
環境變數的管理上會較為複雜
Service 必須要比 Pod 更早出現才行(必須考慮佈署時的順序),否則 pod 不會有相對應的環境變數存在(因為這些環境變數是在 pod 生成時放入的)
因此其實不太推荐使用這個模式來佈署 Service。
DNS
在此模式下,會在 k8s cluster 中安裝一個額外的 DNS server(KubeDNS or CoreDNS) 來處理 DNS resolution 的問題,那 Service 的命名方式呢?
假設 service 所在的 namespace 為 my-ns,service name 為 my-service,cluster domain name 為 cluster.local(安裝時指定),那 service 就可以用以下的 DNS 來存取:
my-service(必須在同一個 namespace 中)my-service.my-nsmy-service.my-ns.cluster.local
而 port number 的部份同樣也可以查詢,以上面的例子來說,設定了一個 port name 為 http & protocol TCP,就可以透過 DNS SRV 查詢 _http._tcp.my-service.my-ns 來取得所設定的 port number。
若是要使用
ExternalName的功能,就只能使用 DNS 模式。
Headless Service
介紹 Headless Service 之前,先回顧一下一般的 service 是如何運作的….
一般的 service 都會帶有一個 ClusterIP,而 client 存取 service 時,k8s 中的 DNS server 會協助將 service domain name 解析為對應的 ClusterIP,而網路流量到達 ClusterIP 後,就會由 kube-proxy 所維護的 iptables rules 來將其分配到後端的 pod 中
詳細的運作流程可以看此篇文章([Kubernetes] How to Implement Kubernetes Service - ClusterIP | Hwchiu Learning Note)的介紹,說明的很詳細。
那 Headless 又是怎麼回事? 顧名思義就是一個沒有定義 ClusterIP 的 Service (將 .spec.clusterIP 設定為 None),以下是一個簡單的範例:
1 | apiVersion: v1 |
沒有定義 ClusterIP 的 Service 會有什麼特性 or 效果呢?
沒有 ClusterIP,因此存取 service 時,k8s DNS 就沒有任何 ClusterIP 的資訊可以回應給 client
若有搭配 Label Selectors,k8s 就會建立相對應的 endpoint,而存取 service 時,k8s DNS 就會直接回應 endpoint list 的資訊(A record),因此 client 可以使用 service domain name 直接存取到 pod
這代表原本 service 透過 Linux iptables 所提供的負載平衡的功能就沒有了,但 client 可以根據 endpoint 的資訊來對 pod 進行直接的存取
- 若是沒有搭配 Label Selector,就沒有 ClusterIP 也沒有對應的 Endpoint,但應該沒有人會做這麼做,而是改以以 ExternalName type 的方式來進行(後面會提到)
最後,需要知道的是,在一般情況下 Headless Service 應該沒什麼機會會使用到,但若是要定義 Statefulful resource object,就必須要搭配 Headless Service 才行。
Service Types
上面所介紹的部份,其實都是屬於 ClusterIP type 的 service,但其實 service type 一共有四種,分別是:
ClusterIP:提供 cluster 內部存取NodePort:供外部存取LoadBalancer:供外部存取 (但只限於支援此 type 的 public cloud)ExternalName:單純回應給 client 外部的 DNS CName record (並非由 k8s cluster 內部的 pod 服務)
ClusterIP
這個部份上面就有介紹過了,詳細的運作行為可以參考以下文章說明:
只是必須注意的是,將 type 設定為 ClusterIP 的 service,只能在 k8s cluster 內部存取;若是要提供給外部存取,則是要使用下面介紹的 NodePort & LoadBalancer 兩種 service type
NodePort
在私有內部的環境中,要讓 k8s cluster 外部存取佈署好的 pod,透過 NodePort type service 是其中一個方式,以下是一個設定 NodePort type service 的簡單範例:
1 | kind: Service |
套用以上設定後,可以看到 cluster 內部就出現了相對應的資訊:
1 | $ kubectl get all |
而且 kube-proxy 還會在每個 node 上放上相對應的 iptables rule:
1 | # 不僅放上規則,還會附帶清楚的註解 |
最後,NodePort service 在使用上有以下幾個重點需要注意:
NodePort 所分配到的 port number 是從 API server 啟動參數中的
--service-node-port-range來的,預設是30000 ~ 32767若要自訂 NodePort number,則是在 Service 中定義
.spec.ports[*].nodePort(只能使用在上面定義的範圍內的 port number)NodePort 預設的有效範圍是 node 的所有 interface
若希望只由特定的 IP 來處理 NodePort 的流量,可透過 API server 啟動參數中的
--nodeport-addresses來指定(例如:使用--nodeport-addresses=127.0.0.0/8表示所有 NodePort 流量都會有 loopback interface 來處理)設定 NodePort 後,可以透過兩種方式存取 Service,分別是
<NodeIP>:spec.ports[*].nodePort&.spec.clusterIP:spec.ports[*].port
關於 NodePort 詳細的運作原理,可以參考此篇文章 => [Kubernetes] How to Implement Kubernetes Service - NodePort | Hwchiu Learning Note
Load Balancer
Load Balancer type 是另一個讓外部可以直接存取 cluster 內部 service 的方式。
但這個 Service Type 需要與外部的 load balancer 服務搭配,因此目前僅有在 public cloud or OpenStack 上才有支援,但由於我目前都不是在這環境上架設 k8s,因此這個部份就先略過。
有需求的人可以參考官網文件說明。
ExternalName
ExternalName 的設定其實就是把 Service 導向指定的 DNS name,而不是 service 中 label selector 所設定的 pod,以下是一個簡單範例:
1 | kind: Service |
當 cluster 內部查找 my-service.prod.svc 的時候,k8s DNS service 就只會回應 my.database.example.com 這個 CNAME recrd。
但回應 CNAME record 跟其他 type 有何差別? 其實就是當存取 ExternalName type 的 service 時,網路流量的導向是發生在 DNS level 而不是透過 proxying or forwarding 達成的。
注意! 若要使用 ExternalName,k8s DNS service 的部份僅能安裝
kube-dns,且版本需要是1.7以上
External IP
這不算是一個 service type,但可以讓使用者指定 service 要黏在哪個 IP 上,以下是個簡單範例:
1 | kind: Service |
透過以上設定,service 只會將進入 80.11.12.10:80 的 網路流量導向使用 Label Selector 選出來的 endpoint(Pod) 中。
而需要注意的是,External IP 的部份並不屬於 k8s 個管理範圍內,使用者若要使用就必須自己負責管理好這個部份。
Future Plan
k8s 是一個快速持續進化的平台,因此 Service 的部份也是有相關計劃準備要繼續改進,而改進的方向大概會是:
proxy policy 在管理上可以更細緻(例如:master-elected or sharded),而不是只有簡單的 round-robin load balancing
Service 未來會有真正的 load balancer,而不像目前 VIP 是指負責轉發封包
可能增加對 L7(HTTP) 的支援
可能支援更多種 ingress mode
一些 Service 背後的運作細節
Service VIP 如何避免衝突?
為了讓使用者可以自訂 service port number,卻又不能發生衝突,因此這意味著要保證每個 service 都會被分配到唯一的 IP。
但這件事情是怎麼辦到的? 透過一個 global allocation map 來完成! (這個 map 存在於 etcd 上)
且 k8s cluster 會遵循以下規則運作:
在 service 建立(or 移除)的時候,k8s cluster 內部的 allocator 會更新這個 global allocation map,將 IP & 其他 service 相關資訊進行新增(or 刪除)
global allocation map object 在 service 建立(or 移除) 的時候一定要存在,否則系統會回報操作失敗的訊息
k8s cluster 內部會有另外一個 background controller 來負責確保 global allocation map object 可以正確的被生成
background controller 同時還會協助確保是否管理者的操作違反規則 & 清理釋放目前沒有 service 佔用的 IP
IPs & VIPs
service VIP 不像是 pod IP 是個真實的 IP,而是透過 Linux iptables rules 去定義當網路流量進到 VIP 時應該如何導向正確的 endpoints(也就是 pod IP),而這個處理過程如下:
1 | networking traffic ---> Service_VIP:port ---> Pod:targetPort |
若是直接對 service VIP 進行存取,但不是存取原本在 service 中定義好的 port,就完全不會得到任何回應。
而當 service 建立 or 刪除時,相對應的 DNS record 也會由 k8s 中的 DNS service 所維護,確保使用者可以透過 domain name 找到 service VIP。
關於 SCTP protocol 的支援
目前在 v1.12 中還是個 alpha 功能,但使用上其實還是很多限制的:
預設不開啟,需透過設定 feature gate 中的
SCTPSupport來開啟此功能若要做 multihomed SCTP association,需要搭配可以為 pod 分配多個 interface & IP 的 CNI plugin 才行
NAT 的部份需要搭配相對應的 kernel module 才可以正常運作
若搭配
type=LoadBalancer,就需要 cloud provider 也一起支援 SCTP protocol 才行,但目前(2018 年底)都還沒有 public cloud provider 支援這個功能Windows worker node 目前並不支援這功能(2018 年底)
userspace kube-proxy 不支援此功能
因此看起來要使用 SCTP protocol,可能就還需要再多等一陣子…..