What is StatefulSet?
StatefulSet 在 v1.9 版後正式支援,是在 Kubernetes 中用來建構 stateful application 的 resource(API) object。
在一般的觀念裡,container 相當合適作為 stateless application 之用(例如:api service),但由於 stateful application 的需求眾多(例如:官網範例中的 ZooKeeper & Kafka 應用),因此 Kubernetes 就額外增加了一些管理維運的機制,讓 pod 也開始適合承載 stateful application。
基本上 StatefulSet 中在 pod 的管理上都是與 Deployment 相同,基於相同的 container spec 來進行;而其中的差別在於 StatefulSet controller 會為每一個 pod 產生一個固定的識別資訊,不會因為 pod reschedule 後有變動。
什麼時候需要使用 StatefulSet?
而到底如何研判某某 application 是否需要使用 StatefulSet 來佈署呢? 如果有符合以下條件,就需要使用 StatefulSet 來進行佈署:
需要穩定 & 唯一的網路識別 (pod reschedule 後的 pod name & hostname 都不會變動)
需要穩定的 persistent storage (pod reschedule 後還是能存取到相同的資料,基本上用 PVC 就可以解決)
佈署 & scale out 的時後,每個 pod 的產生都是有其順序且逐一慢慢完成的
進行更新操作時,也是與上面的需求相同
有什麼限制?
v1.5 之前的版本不支援 StatefulSet,v1.5 ~ v1.9 之間是 beta(需額外開啟此功能),v1.9 之後才有正式支援
storage 的部份一定要綁定 PVC,並綁定到特定的 StorageClass or 預先配置好的 PersistentVolume,確保 pod 被刪除後資料依然存在
需要額外定義一個 Headless Service 與 StatefulSet 搭配,確保 pod 有固定的 network identity
所謂的 network identity,即是可以透過 domain name 直接可以取得 pod IP;實現的方法則是佈署一個 ClusterIP=None 的 Service,讓 cluster 內部存取 service 時,可以直接連到 pod 而不是 service VIP。
Headless Service 詳細的設定方式可以參考此文章。
以 MongoDB 作為示範
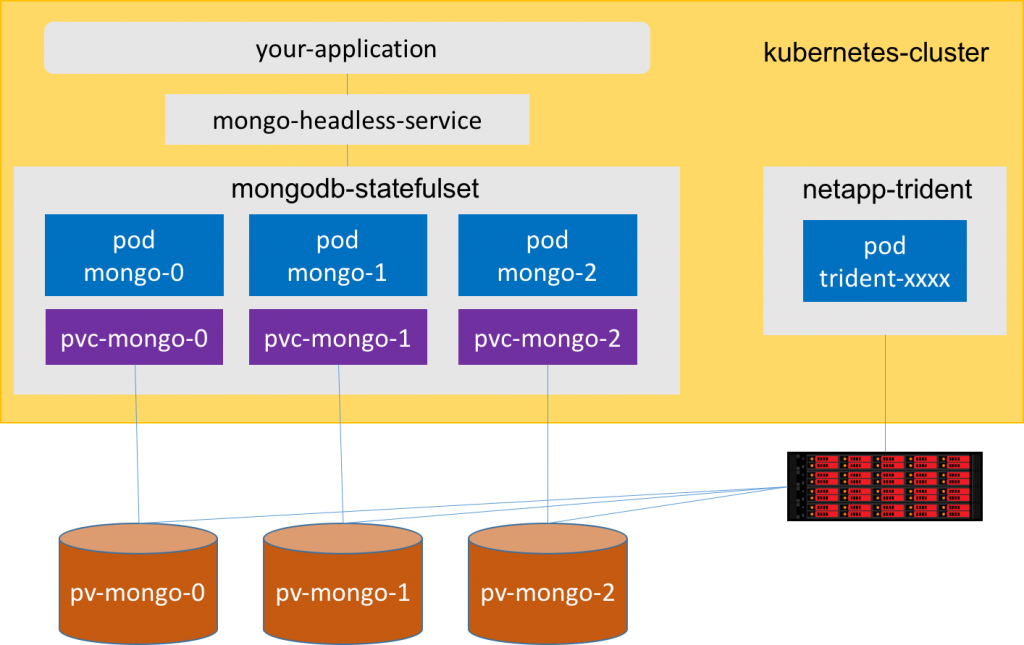
如何撰寫一個 StatefulSet?
要撰寫一個 StatefulSet,有幾個重要的部份必須涵蓋:
Application & Persistent Volume Claim
.spec.selector所定義的內容(matchLabels)必須與.spec.template.metadata.labels相同
其他的部份則是跟 Deployment 幾乎是相同的。
Application & Persistent Volume Claim
首先是關於 Application & Persistent Volume Claim 的定義:
1 |
|
關於 GlusterFS 的設定,可參考文章 [Kubernetes] 快速安裝 GlusterFS + Heketi 並與 StorageClass 搭配使用 進行安裝設定
套用上面的設定後,接著檢視一下在 k8s 中到底生成了哪些 resource object:
1 | # 取得在目前 namespace 中所有的 resource object |
從上面可看出,Pod & Service 這兩個部份的 resource object name,都會帶有一個有順序性的 index,而這個 index 不會因為 pod reschedule 而改變,而且還會將原本的 PVC 掛載回來。(透過 Service -> PVC 的路徑)
Headless Service
Headless Service 則是要定義一個 ClusterIP: None 的 service,目的就是讓 cluster 內部的 pod 可以 透過 DNS 找到 StatefulSet pod IP:
1 |
|
將以上設定套用到
1 | # 取得 StatefulSet 的 pod & service 資訊 |
從上面的訊息可以看出上面所定義 nginx service(nginx.default.svc.cluster.local) 所對應到的 IP 都是 pod 本身的 IP。
如何識別 StatefulSet 產生的 Pod?
完成了上面的操作測試後,接著回頭來了解到底在 k8s 中是如何識別 StatefulSet 中的 pod & service。
每一個 StatefulSet Pod 都有一個獨一無二的識別資訊,但這件事情在 k8s 中是如何被達成的? 其實是分別由以下三種資訊所組成:
表示順序的索引值 (Ordinal Index)
穩定的網路識別資訊 (Stable Network ID)
穩定的儲存空間 (Stable Storage)
Ordinal Index
若一個 statefulset 包含了 N 個 replica,那每一個 pod 都會被分配到一個獨一無二的索引,從 0 ~ N-1,即使 pod reschedule 也不會改變。
Stable Network ID
每個在 statefulset 中的 pod 都會有自己獨一無二的 hostname,命名的規則為 $(statefulset name)-$(ordinal index),因此在上面的例子中,3 個 pod 的 hostname 就會分別為 web-0、web-1、web-2。
此外,statefulset 還會透過 Headless Service 來維持 pod domain name 是固定指到 pod IP,並使用以下的標準格式存取 domain name:(以下稱為 governing service domain)
$(service name).$(namespace).svc.cluster.local
其中 cluster.local 是當初安裝 k8s 所設定的 cluster domain,若安裝時有修改的話,上面的 domain name 也必須跟著調整。
因此存取每一個 pod 的完整 domain name 如下:
$(podname).$(governing service domain)
以下是一些範例說明:(假設 cluster domain 為 cluster.local)
| Service (ns/name) | StatefulSet (ns/name) | StatefulSet Domain | Pod Hostname | Pod DNS |
|---|---|---|---|---|
| default/nginx | default/web | nginx.default.svc.cluster.local | web-{0..N-1} | web-{0..N-1}.nginx.default.svc.cluster.local |
| foo/nginx | foo/web | nginx.foo.svc.cluster.local | web-{0..N-1} | web-{0..N-1}.nginx.foo.svc.cluster.local |
以下透過範例來證實:
1 | # 取得 k8s DNS 的 ip address |
Stable Storage
若是 statefulset 中的 replicas 設定為大於 1,為了確保每個 pod 在產生時都會有各自對應的 persistent storage 可用,在 Storage 的部份就要以 volumeClaimTemplates + StorageClass 來設定,使用以下範例說明:(來自於上方完整範例)
1 | # 宣告 volumeClaimTemplates |
透過以上的設定,statefulset 中每個 pod 副本產生時,k8s 會自動執行以下工作:
StorageClass “my-gfs-storageclass“ 會負責對特定的 storage 要求 1GB 的空間
StorageClass “my-gfs-storageclass“ 動態產生 persistent volume(PV),並與上面的空間綁定
透過 volumeClaimTemplates 為每個 pod 產生一個 persistent volume claim(PVC),並與步驟 2 的 PV 綁定
pod 使用 PVC 並掛載到指定的目錄上
透過 StorageClass,可以根據 resource 的需求,產生 persistent volume 並與特定的 storage 綁定
PV 不會因為 pod 被刪除 or reschedule 而消失(只能手動刪除),如此才能達成 statefulset 對 storage 的要求。
接著來檢視一下實際的例子:
1 | # 檢視 PVC |
Pod Name Label
statefulset 產生每個 pod 時,都會自動幫 pod 加上名稱為 statefulset.kubernetes.io/pod-name 的 label,而 label value 就是上面提到的 pod name。
看看實際操作產生出來的結果:
1 | $ kubectl describe pod/web-0 |
透過這個特別的 label,就可以讓使用者根據需求,額外定義 service 並附加到指定的 pod 上(透過 label selector)。
Deployment & Scaling 流程說明
佈署 & Scale out
當佈署一個 replica 數量為 N(大於 1) 的 StatefulSet 時,不會像 Deployment 一樣,pod 會同步的產生,而是會有順序的逐一產生,整個流程發生的過程如下:
佈署的順序會是 **{0 –> N-1}**,以上面的例子來說則是 web-0 >> web-1 >> web-2 (可想而知,web-2 不會在 web-0 & web-1 都 Ready 之前就開始產生)
當要對 pod 進行 scale 時,predecessor 的狀態必須是 Running & Ready
例如當一個 pod(web-0) 要 scale out 成 2 個 pod(web-0 + web-1) 時,web-0 的狀態一定要是 Running & Ready 才會開始
當 StatefulSet 進行 scale out 時,整個過程也會遵守上面的規則。
刪除 & Scale in
但若是要刪除 pod,或是進行 scale in 的時候,整個流程發生的過程如下:
以反向 {N-1 –> 0} 的順序逐一刪除,以上面的例子來說則是 web-2 >> web-1 >> web-0 (可想而知,web-1 不會在 web-2 完成刪除之前就被刪除)
當要終止一個 pod 時,所有的 successor 都必須完成 shutdown 才行
例如要終止三份 replica(web-0 + web-1 + web-2) 中的 web-1 時,web-2 必須要完全終止才行
此外,若是把 pod.Spec.TerminationGracePeriodSeconds 設定為 0,pod 的刪除就會強制進行,而不會一個一個慢慢來。(不建議這麼做)
Pod Management Policy
上述所說的是 StatefulSet 的預設行為,但在 v1.7 版之後,就可以透過修改 .spec.podManagementPolicy 欄位來改變佈署 & scale 的行為:
OrderedReady:此為預設值
Parallel:整體的行為會跟 Deployment 相同,同時產生(or 刪除) pod,不考慮順序問題
更新(update)要如何進行?
預設情況下,k8s 自有一套進行 update 的準則(預設為 rolling update),而 update 的過程會把 pod 中的 container, label, resource request/limit, annotation … 等資訊進行變更;而在 v1.7 版之後,就可以透過 .spec.updateStrategy 的設定,停止上面那些自動化的行為。
目前 .spec.updateStrategy 支援兩種設定:
On Delete
這其實是 v1.6 版之前的預設行為,只是在 v1.7 版後實作成 OnDelete;當設定 .spec.updateStrategy.type: "OnDelete" 時,對於 sprc template 的變更不會有任何反應,除非使用者手動刪除 pod,讓 replication controller 重新產生 pod,才會套用新的 spec template 設定。
Rolling Update
這就屬於預設行為(.spec.updateStrategy.type: "RollingUpdate"),當 spec template 發生變更時,舊的 pod 會逐一的刪除並逐一產生新的 pod。(依然是會有順序性的)
Partition
若是在 StatefulSet 中有 5 個 replica,但只想要更新其中兩個怎麼辦? 在 k8s 中就提供了 partition 的機制來完成這件事情,透過設定 .spec.updateStrategy.rollingUpdate.partition 為一個特定的整數(int)值,當 spec template 變更時,index 大於(or 等於)此整數值的 pod 就會被更新,而小於此整數值的 pod 就不會被更新。
以上面的例子為例,假設有 5 個 replica,分別為:
- web-0
- web-1
- web-2
- web-3
- web-4
而 .spec.updateStrategy.rollingUpdate.partition 設定為 3,當 spec template 變更時,就只會有以下的 pod 會變更新:
- web-3
- web-4
因此,若是有分階段更新/發佈 or canary deployment 的需求時,就可以透過 partition 的功能來完成。