Monitoring System Overview
當企業 IT 從傳統的 bare metal(實體機),轉移到 virtual machine(虛擬機) 甚至是 container(容器) 的過程中,對 monitoring 的需求只會越來越高
監控的對象也比起原本多很多,例如:container, distributed system/storage, SDN network, 各種 application,規劃時都需要考量進來
相對應 monitoring 所需要的儲存空間也相對龐大,同時也衍生了可以對這些龐大資料進行更進一步的分析、告警、預警…等工作
monitoring system 同時也可以作為輔助決策的重要角色,因為不僅可以提供 real-time 的狀態呈現,同時也可以顯示歷史資料,藉以協助進行故障回溯 & 風險預測…等工作
從程式開發的角度,可以將監控分為
基礎資源(Infrastructure)、中間層(Middleware)、應用程式監控(Applications)三層,每一層都有不同的監控指標
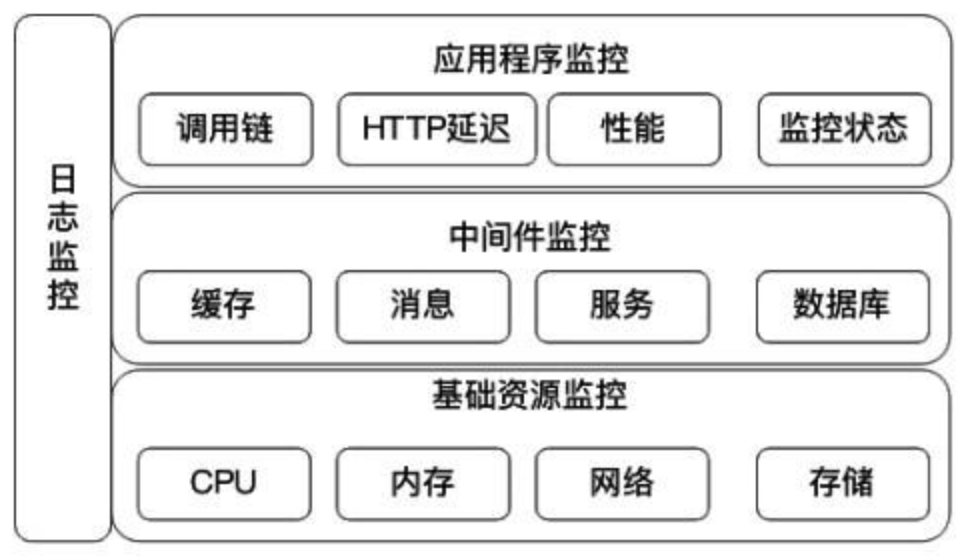
- 針對需求決定要收集的監控目標,不需要全部都收
Infrastructure Monitoring
這部份包含了 Networking、Storage、Computing 三種主要資源的監控
Networking
這部份包含了以下的監控項目:
Datacenter 內網路流量的監控
Networking Topology & Devices 的監控
Network Performance 的監控
網路攻擊的探測
Datacenter 中的網路設備監控,一般都是透過 port mirror 的方式來達成;若是 virtual device 則是可以透過 tcpdump 或是其他工具來完成
透過匯總網路封包的 source IP & destination IP 可以用來產生 networking topology
網路設備的監控通常會使用 SNMP v3 協定
Storage
目前 storage 主要分為 cloud storage & distributed storage 兩種
cloud storage 是透過儲存設備建立 storage pool,並提供其他的機器統一的 storage interface,例如:iSCSI, NFS
distributed storag 則是與機器上的 OS 共存,藉以提供分佈式集群的儲存服務,例如:HDFS
cloud storage 的監控可分為以下三種:
storage performance:block storage 會著重在 IOPS, Read/Write Latency, Disk Usage;object storage 則是著重在 Inode, Read/Write Speed, Folder permission … 等
storage system:不同的系統有不同的指標,例如 Ceph 則需要監控 OSD, MON, PG … 等資訊
storage device:這部份則是以監控 x86 server 上的儲存相關資源為主
Computing
包含 bare metal, VM, container 的監控
可兼容來自於不同廠商的 server
可兼容不同的作業系統 (e.g., Windows, Linux … etc)
可兼容不同的虛擬化技術 (e.g., VMware, Xen, KVM … etc)
監控數據可透過在每個 client 上放 agent 或是從外部透過虛擬化環境的 API 來取得
OS 層級通常會監控 CPU、Memory、Network I/O、Disk I/O … 等資訊
bare metal server 的監控可以透過 IPMI
Middleware Monitoring
常見的 middleware 可分成幾類:Message Queue(RabbitMQ, Kafka),Web Service(Tomcat, Jetty), Buffer(Redis, Memcached), Database(MySQL, PostgreSQL)
很多 application 的性能都會直接與 middleware 有關係
middleware 的監控可用在 application 的優化,也可以用來在高並發 or 大流量環境時的提供正確的 feedback
middleware 的監控會根據不同的軟體有不同的特性資訊需要蒐集,因此沒有統一的標準;比較標準的作法就是分別針對不同的軟體開發不同的 agent,再統一收到監控中心(例如:Prometheus & 眾多的 exporter)
Application Performance Monitoring (APM)
APM 主要是針對 application level 的監控
監控的項目包含了 application 運行狀態、效能、log、調用鏈(call-chain)跟蹤
透過
調用鏈(call-chain)跟蹤可以建構出完整程式運行的 topology,還可以取得每個元件的執行時間,作為調整效能的重要依據
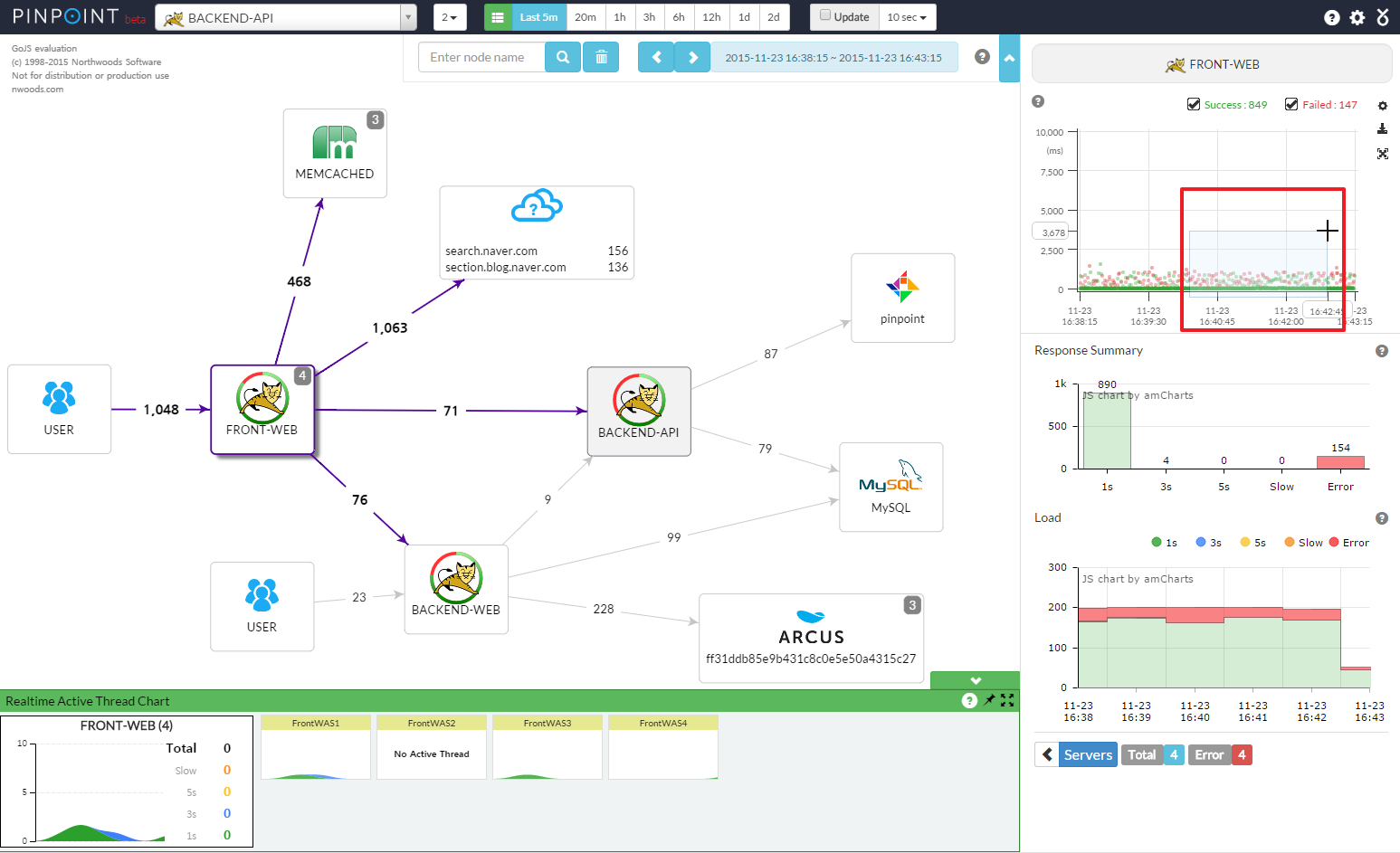
APM 除了可攔截 method call 的資訊外,還可以攔截 TCP & HTTP request,進而取得花最多時間的 method & SQL command,或是延遲最久的 API … 等訊息
商業化的 SaaS APM 甚至可以提供從不同地點發出的模擬請求
由於 application 的監控系統也需要關心 host 的狀態,因此會跟 host monitoring 會有重疊
Log Monitoring
Log monitoring system 蒐集的主要是文字型的資訊,因此儲存的部份就需要具備全文檢索的能力
可用來定位出效能問題,也可以用來做數據統計 & 故障告警等功能
目前比較流行的工具組合是:
fluentd->Kafka->Logstash->Elasticsearch->Kibana
監控系統的實現
- 監控系統通常分為 數據蒐集(收集、過濾、匯總、儲存) & 數據處理(分析、顯示、預警、告警、告警動作觸發) 兩大部份
數據蒐集
數據蒐集有兩種方式:透過 client 端程式 or 通過標準的 protocol(例如:SNMP、IPMI、JMX … 等等)
數據傳輸可以透過 HTTP/Socket 進行傳輸,也可以利用 RabbitMQ/Kafka 等工具作為 buffer 協助傳輸
利用 message queue 可以將整體架構進行 decouple,但系統就會與相關工具具有強大的依賴性,且會有單點故障的疑慮
儲存數據之前,還需要對資料進行去重複(重複上報數據) & 過濾(並非所有資料都需要)的步驟
監控數據的儲存通常使用 TSDB(Time-Series Database)
TSDB 具有以下特點:
- 寫入一次,多次讀取,通常不會有修改 or 更新的動作
- 數據流量相對穩定,不會有突然性爆炸流量的發生
- 查詢方式通常是以最近的為主,很少需要查詢到太久之前的資訊(例如:一週以前)
- 通常以 LSM tree 來設計(跟 DB 的 B+ tree 是完全不同的),資料壓縮比高
- 需要大容量的資料儲存能力
數據處理
為了提昇查詢歷史資料的速度,必須對資料進行彙整
目前比較常用的視覺化查詢工具為 Grafana & Kibana
數據分析:指的是對監控數據進行
效能分析、關聯分析、趨勢分析效能分析:可按照資源的消耗類型來分類,可能是 high CPU usage 或是 high DISK I/O,不將消耗相同類型資源的 workload 放在一起
關聯分析:可透過 source/destination IP 繪製出 network topology;或是在 APM 監控中透過 TraceId 的關聯取得 call chain 的資訊,藉此分析出不同 component 的效能並優化系統
趨勢分析:將數據結合各種數學方法,分析數據的週期性,並預測出未來的變化趨勢,並用於資源調度 & 預分配資源上
規則告警則是根據監控數據,定義多為度的告警規則
規則告警的例子像是:一段時間內觸發告警特定次數就停止、設計告警抑制,假設由 root issue 觸發很多 sub issue 的告警,只要針對 root issue 發告警即可
告警動作可以是送訊息 or EMail 通知,也可以是發送 webhook
監控系統的發展趨勢
分散式系統越來越普及,單一指標無法很精確的反應實際系統運行 & 程序當下的狀況
傳統監控提供效能、健康狀態、Application … 等監控能力
監控系統現在開始朝著自動化 & 智慧化的方向發展,開始會具備機器學習 & 自動化的維運能力
智慧監控需要有以下幾種能力:
- 根據多種維度的指標分析定位實際問題
- 故障 & 風險預測
- 智慧處理:告警發生後的問題處理,由智慧系統判斷後自行決定處理方法
Prometheus
網路上有很多介紹了,簡單介紹可以參考以下文章:
以下是其他重點資訊節錄:
Prometheus 以 pull 的方式取得 metric,提供 metric 的 client 不需要知道 Prometheus 在那,因此可完全獨立於監控系統之外
一般監控系統以 push 的方式蒐集資料,相對不彈性,也可能因為 push 失敗導致監控系統癱瘓
支援靜態設定,也可搭配 ZooKeeper, Consul, Kubernetes … 等方式進行動態的 service discovery
本地儲存建議採用 SSD
若需要以 push 模式取得資料,可搭配 Pushgateawy 來處理
AlertManager 獨立於 Prometheus 之外,當 metric 有觸發了預設在 Prometheus 中的規則時,就會將訊息送到 AlertManager 做後續處理
AlertManager 支援多種通知方式,同時也支援 HA 並有 Gossip 的機制在(預防重送)