AWS 提供的 DB 相關服務
RDBMS 關聯式資料庫基本概念
RDBMS 的基本概念(例如:Database、Table、Row、Field )這邊就略過了….
Data Warehousing
包含大量資料
搭配 business intelligence 的工具(例如:Cognos, Jspersoft, SQL Server Reporing Service, Oracle Hyperion … 等等),從大量的資料中取得有效益的數據
這類的運用通常都與管理決策有關
OLTP 與 OLAP
兩者的不同在於查詢類型的不同
OLTP 查詢的只是一般事務類型的資料,例如:訂單編號 123 對應到的日期、訂購者姓名、住址 … 等資料,頂多是幾筆資料的查詢
OLAP 則會涵蓋大量資料的存取 & 分析,例如:數位產品在 EMEA 地區的淨利資訊
因此與 OLAP 相對應的 data warehousing 的技術,在本質上(資料庫 & infra 層面),就與 OLTP 對應的一般 DB 是不一樣的
AWS 提供了
Redshift作為提供 data warehousing 的工具,可用來進行 OLAP 的工作
Elasticache
Elasticacahe 提供 memory cache 的全託管服務
由於資料存取只會從記憶體,所以速度比起磁碟機快上很多
目前支援
Redis&Memcached兩種
各類 DB 服務與合適的應用
RDS (for OLTP)
- SQL Server
- MySQL
- PostgreSQL
- Oracle
- Aurora
- MariaDB
Redshift (for OLAP, 與 Business Intelligence & Data Warehousing 應用搭配使用)
DynamoDB (NoSQL, 類似 MongoDB)
Elasticacahe (memory cache,用來加速存取)
- Memcached
- Redis
考試重點
RDS 是運行在 VM 上的
承上,但無法登入系統中執行任何動作
更新 RDS 是 AWS 的工作,跟使用者無關
RDS 並非 serverless (Aurora serverless 則是 serverless)
若是需要更高的 storage 性能,RDS 還提供了 provisioned IOPS storage 選項可用;最大可以達到 10,000 IOPS & 16TB 空間
RDS
核心概念
RDS 是個全託管的資料庫服務
使用者無法存取底層的 OS,完全由 AWS 負責管理
使用者可以用連到原本資料庫(例如:MySQL)的方式連到 RDS
可以隨時根據需求調整 RDS instance 的大小
可以佈署為 Multi-AZ,藉此達成備份 & HA 的目的
搭配 read replica,讓 application 的 read workload 轉到 read replica,可以有效降低 primary DB 的讀取負載
優點
minor 版本的自動更新
透過 point-in-time snapshot 的方式,進行自動備份 (因此可以還原到指定的時間點)
使用者完全不用擔心底層的 OS
Multi-AZ 的佈署只需要非常簡單的步驟就可以完成
Automatic AZ-failover 可以在 RDS instance 出問題時,自動恢復
RDS 服務提供的備份 / Multi-AZ / Read Replicas 功能
備份
RDS 提供兩種備份類型:
Automatic Backup
DB snapshot
Automatic Backup
Automatic Backup 每天會執行一個完整的 full snapshot,資料保存週期可以設定 1~35 天,這個週期稱為
retention period每五分鐘會自動備份 transaction log,而這備份也提供了還原到任何時間點的能力 (從最後一個五分鐘備份)
進行復原程序時,AWS 會自動選擇最近時間點的 backup 來還原;使用者可以決定恢復到 retention period 中的任何一個時間點
Automatic Backup 是預設啟用的,資料會存到 S3 (若是要停用 backup,則將 retention period 設定為 0)
S3 會提供與 RDS storage 容量相同的免費額度,假設啟動 5GB 容量的 RDS,S3 就會相對應提供免費的 5GB 備份空間,超過才需要收費
備份工作會在使用者預先定義好的 backup window 進行
備份工作進行時,會需要耗費一定量的 storage I/O,因此備份工作當下存取資料會稍微有延遲
當 RDS instance 被移除後,相對應的備份資料也會一併被移除(但刪除前可以先做 snapshot 來保留資料)
若使用的是 MySQL,建議 DB engine 選用 InnoDB 來確保備份的可靠性
DB snapshot
需要使用者手動執行,會衝擊到 RDS instance 運行時的 I/O 效能
若是啟用 multi-AZ,那 snapshot 就會對 standby DB 執行,則不會影響 master DB 效能
snapshot 保存時間的長短可以自行決定
即使 RDS instance 被移除,snapshot 依然會繼續存在
還原
不論是透過 Automatic Backup 或是 snapshot 還原,都會產生一個全新的 RDS instance & DNS endpoint

加密
加密功能目前支援 MySQL, Oracle, SQL Server, PostgreSQL, MariaDB, Aurora
需要搭配 AWS KMS(Key Management Service) 使用 (AES-256)
DB 資料進資料庫後會以加密後的形式存在
連同 automatic backup, read replicas, snapshot … 這幾個部份都是以加密的方式存在
若是 master 沒有加密,那 read replica 也無法加密
Multi-AZ
架構中會有兩台 RDS instance 分別位於不同的 AZ 中,預設是第一個 AZ 中的 instance 被存取
資料一旦寫入 RDS instance,就會立刻被同步到位於另外一個 AZ 作為備援用的 RDS instance 中
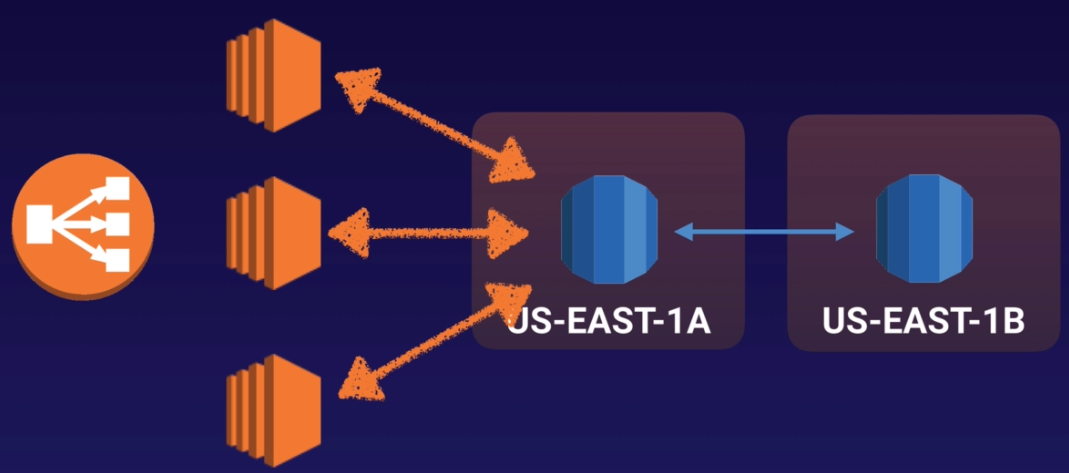
- 當進行計畫中的 DB 維護、DB 故障、或是某個 AZ 掛掉了,原本 RDS domain 的指向會立即自動切到備援在另一個 AZ 的 RDS instance 中
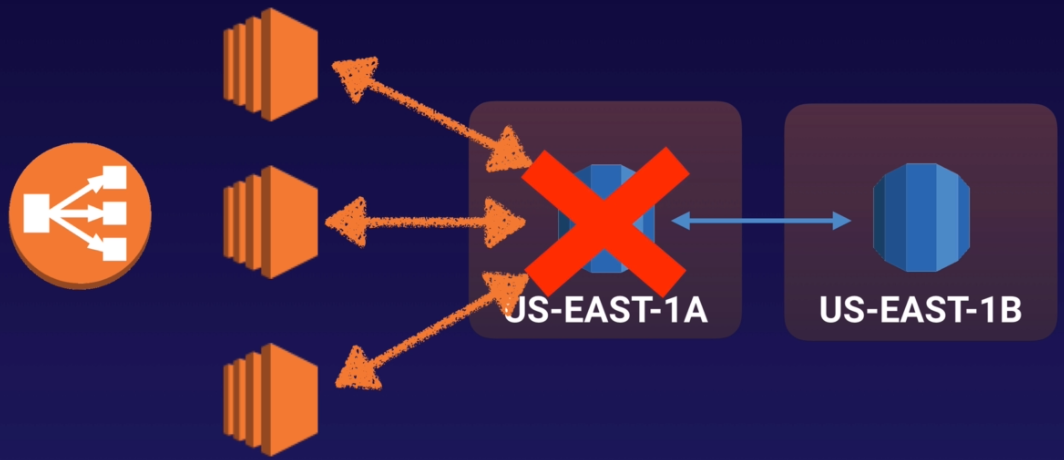
此功能是用在災難還原中,並非用於提昇 DB 效能
要提昇 DB 效能則是需要使用 read replicas 的功能
如果直接 reboot RDS instance,就會強制觸發 failover 的動作,DB DNS 的指向就會切換到另一個 AZ 的 RDS instance
目前支援 Multi-AZ 的資料庫類型有 SQL server、Oracle、MySQL、PostgreSQL、MariaDB
建議在 production 環境,
Multi-AZ Automatic Failover的功能一定要開啟從 single-AZ 轉換為 multi-AZ 的過程是個不會影響線上服務的操作(zero downtime),只要在 console 直接啟用 multi-AZ 功能即可
Read Replicas
Read Replicas 可以讓生產環境中的 DB,產生出 read-only 的複本用的功能(但只能接收 read connection)
在有設定 read replicas 的 RDS 架構中,所有的 write 會集中在某一台 DB 上,資料則會以非同步的方式複製到其他 replica DB 中
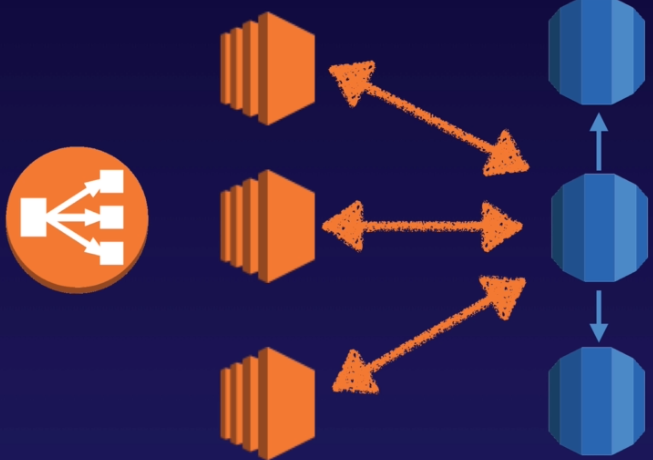
- 但前面存取 RDS instance 的程式就必須要跟著調整,讓讀取的行為可以分散落在不同的 DB 上
若 primary DB 無法正常連線時,AWS 提供的 domain 不會自動協助切換到 secondary DB,程式中必須調整成連線 secondary DB domain
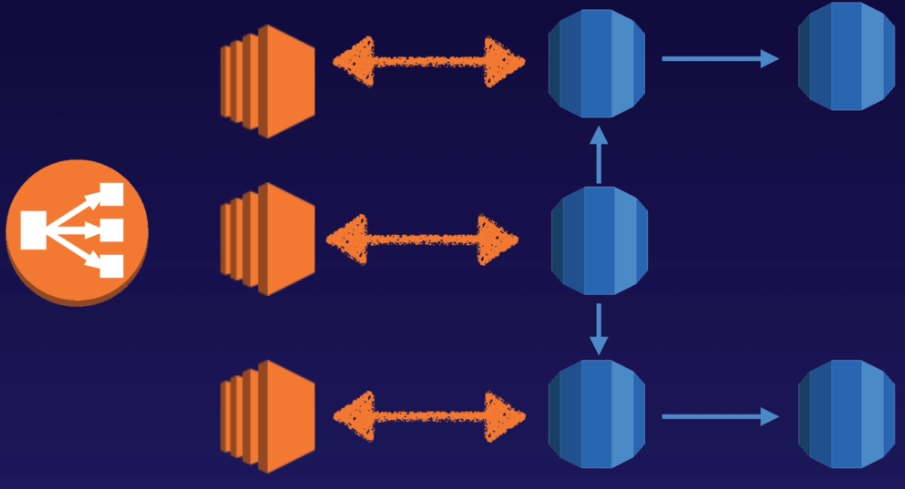
Read Replicas 功能通常會用在讀取繁重的業務場景下,用以提昇效能;但也可以考慮使用 Elasticache
Read Replicas 目前支援 MySQL、PostgreSQL、MariaDB、Oracle、Aurora 等資料庫
目前只有 SQL server 不支援 read replicas
主要是用在 scaling 以增加讀取效能,非災難還原
要使用 read replicas 的功能,必須開啟 automatic backup
最多可以有五個 DB 複本
可以為複本 RDS instance 再設定 read replica 副本(但要考慮延遲問題)
每個 read replica 都會有自己的 DNS endpoint
read replica 可以跨 AZ,也可以跨 region
設定 Multi-AZ 的 RDS instance 也可以設定 read replicas
read replica 本身可以將自己提昇為 primary DB,但這樣一來同步複本的功能就會消失
在同一個 region 中,data replication 過程中產生的資料傳輸是免費的 (即使是 cross AZ 也是免費的)
cross region 的 data replication 就會有傳輸費用的產生
其他考試重點
任何 DB engine 的升級,primary & standy DB 會同時升級(若是 multi-AZ),此時就會有 downtime 的發生
若要增加安全性,不要使用帳號密碼連接 RDS,可以啟用
IAM DB authentication,如此一來就會改成用 authentication token 來進行身份驗證;而 RDS 存取權限也可以完全透過 IAM 來管理RDS 的基本監控可以提供
CPU Utilization、Database Connections、Freeable Memory… 等資訊,如開啟 enhanced monitoring metrics,就可以額外看到OS process&RDS child process… 等資訊
Aurora
Aurora 是什麼?
首先來看看 AWS 對 Aurora 的定義:
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud, that combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open source databases.
Amazon Aurora is up to five times faster than standard MySQL databases and three times faster than standard PostgreSQL databases. It provides the security, availability, and reliability of commercial databases at 1/10th the cost. Amazon Aurora is fully managed by Amazon Relational Database Service (RDS), which automates time-consuming administration tasks like hardware provisioning, database setup, patching, and backups.
Amazon Aurora features a distributed, fault-tolerant, self-healing storage system that auto-scales up to 64TB per database instance. It delivers high performance and availability with up to 15 low-latency read replicas, point-in-time recovery, continuous backup to Amazon S3, and replication across three Availability Zones (AZs).
從上面的敘述可以看出 Aurora 服務的特性:
提供相容於 MySQL & PostgreSQL 的關聯式資料庫服務
對於傳統關聯式資料庫的服務的需求,Aurora 提供了另一個高效能(號稱 5 倍的 RDS MySQL 效能 & 3 倍的 RDS PostgreSQL 效能)、高可用、簡單、使用成本低的選擇
使用者可省下許多處理管理工作的時間,例如:佈建硬體、資料庫設定、更新、備份…等工作
提供許多進階管理功能,例如:分散式、容錯、self-healing、資料復原、持續備份、跨 AZ 的複本設定
Aurora 服務的特色
資料庫開始的容量為 10GB,最大可到 64TB;儲存空間可以自動擴展 (以 10GB 為單位遞增)
每個 AZ 會有兩份資料備份,搭配最低三個 AZ 的設定,資料一共會有 6 份的備份
Aurora 可自動將資料複製為兩份,且不會影響 write availability;最多可將資料複製成三份,且不會影響 read availability
Aurora 透過不斷的掃描 data block & 磁碟,自動修復錯誤,藉以提供 storage self-healing 功能
Aurora 會自動開啟備份機制,也可以直接對 Aurora DB instance 進行 snapshot,甚至還可以將 snapshot 分享給 AWS 的其他帳號
不論是備份 or snapshot 都不會影響 Aurora 的運作效能
透過
Backtrack的機制,不需要使用備份就可以還原到任何一個時間點的資料若是服務初期階段,workload 很低且無法預測,可以使用 Aurora Serverless 來將費用降到最低;此服務也可以在服務需求變大時,自動的 scale up
對比 RDS,成本會多 20% 左右,但效能會更好
RDS Replica Types
RDS 提供三種複本(replica)類型:
Aurora Replicas (目前只有此版本支援 Automated Failover)
MySQL Read Replicas
PostgreSQL Read Replica
以下是 Aurora replica & MySQL replica 的簡單比較:
| 功能 | Aurora Replicas | MySQL Replicas |
|---|---|---|
| 複本數量 | 最大可到 15 | 最大可到 5 |
| 複製類型 | 非同步(延遲以毫秒計) | 非同步(延遲以秒計) |
| 對 Primary Instance 效能影響 | 低 | 高 |
| 複製地點 | In-region(也可以 Cross-region) | Cross-region |
| Failover 功能 | Yes(資料不會掉) | Yes(有可能掉數分鐘的資料) |
| 自動 Failover | Yes | No |
| 支援使用者自訂的 replication delay | No | Yes |
| 支援複本與 primary 不同的 data or schema | No | Yes |
Aurora replication 的速度更快,延遲更低,可達到 10ms 以下的 replica lag
啟動 Aurora 服務需要提供的資訊
要選擇 MySQL or PostgreSQL與對應的版本
資料庫要存在 Region(primary AZ + replica AZ) 中或是 Global(primary region + replica region),目前僅支援 MySQL
若是穩定的 workload,選擇
One Write and multiple readers;若屬於剛開始起步或是無法預測的 workload,選擇Serverless資料庫名稱、帳號、密碼
DB instance class
是否進行 Multi-AZ 佈署 (Aurora 可提供 HA & 自動 failover 的功能)
所使用的 VPC 網路
其他考試重點
如果 Aurora primary DB 掛了,若有多個 read replica,那優先選擇的條件會是以
priority+容量來評估;舉例來說:priority tier-1 > tier-10 > tier-15,容量 32TB > 16TB以上面的例子來說,若有五個 read replica 分別是 tier-1(16TB)**、tier-1(32TB)、tier-10(16TB)、tier-15(16TB)、tier-15(32TB)**,那會被優先選中提昇為 primary DB 的就會是
tier-1(32TB)可透過
custom endpoint的機制,可以設計專門處理 DDL & DML 的 endpoint,或是僅用來做查詢的 endpoint若是有多個 read replica,將資料查詢的流量送往 Aurora read endpoint,就會被自動分散到不同的 read replica 去,使用者不需要自己去處理 load balancing 的部份
DynamoDB
DynamoDB 是什麼?
首先來看看 AWS 對 DynamoDB 的定義:
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It’s a fully managed, multiregion, multimaster, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and can support peaks of more than 20 million requests per second.
從上面的敘述可以看出 DynamoDB 服務的特性:
儲存 key/value & document 類型的資料庫 (schemaless)
即使資料量很大,也不太會影響到存取的速度
還可以啟用 memory cache 來取得更快的速度
可以跨 region, 同時也包含了備份 & 還原的功能
DynamoDB 基礎知識
是由 AWS 自行開發的全託管 NoSQL DB,類似於 MongoDB;使用者只要確認需要多少容量,其他就通通由 AWS 負責
資料儲存在 SSD 中
會自動將存入 DynamoDB 的資料分散同一個 region 中的多個不同的 AZ 中,且會根據使用需求自動進行 scale
可以輕易的與其他 AWS 資料處理服務進行整合,例如:Elastic MapReducee
由於資料寫入後需要同步在 cluster 中的不同機器上,因此需要一點時間,才可以取得最新的資料
若資料寫入 DynamoDB 不需要在一秒內存取到最新的資料,那可以選擇
Eventually Consistent Read若資料寫入 DynamoDB 後需要在一秒內可以存取到最新的資料,則選擇
Strongly Consistent Read可以儲存較大的 text & binary 物件,但上限是 400KB
常見的適用場景
IOT:儲存 meta
Gaming:儲存 session, leaderboard
Mobile:儲存 user profile,個人化資訊
其他考試重點
DynamoDB Accelerator(DAX) 除了可以提供 DynamoDB 的優點外,還增加了 in-memory cache 的功能,可以大幅提昇外部讀取的能力(號稱可以提昇 10 倍的效能,並將延遲從 ms 降低到 µs 等級)
透過 AWS CLI 產生的 DynamoDB table,預設是沒有啟用 Auto Scaling 的功能的
若是流量很大,希望可以進一步提高 DynamoDB throughput capacity,可以開啟 DynamoDB Auto Scaling
Redshift
Redshift 是 AWS 提供的資料倉儲服務,可以用來儲存大量的傳統資料,進行 OLAP or big-data analytics 相關工作,作為 business intelligence 之用。
而服務本身包含以下幾點特色:
使用設定
若是設定 single node,可用容量為 160GB
若是設定為 multi node,則包含
Leader node&Compute nodeLeader node:管理 client 連線 & 接收 requestCompute node:儲存資料,執行查詢 & 相關計算,最多可以有 128 個 compute node
可以很容易與其他工具整合,例如:Jaspersoft、Microstrategy、Pentaho、Tableau、Business Objects、Cognos … 等等
進階功能
Redshift 可以將傳入的資料進行高效率的壓縮,節省儲存空間
在資料寫入的過程中,可以自動選取最有效率的壓縮方式
Redshift 不需要 Index & materialized view,因此比起傳統 RDBMS,需要的儲存空間就相對低很多
MPP(Massively Parallel Processing) 功能可以將資料 & 查詢需求平均分散在不同的 compute node 上
資訊安全
資料傳輸的過程會以 SSL 加密
任何 REST 相關的工作都會以 AES-256 加密進行
可整合 HSM or AWS KMS 作為金鑰管理方式
備份
預設資料保存一天,最多存放 35 天
Redshift 會將存入的資料保存三份(原本的、在另外一台 compute node 的複本、在 S3 的備份)
Redshift 可以非同步的將 snapshot 傳到 S3 中進行儲存
Elasticache
Elasticache 是什麼?
首先來看看 AWS 對 Elasticache 的定義:
Amazon ElastiCache allows you to seamlessly set up, run, and scale popular open-Source compatible in-memory data stores in the cloud. Build data-intensive apps or boost the performance of your existing databases by retrieving data from high throughput and low latency in-memory data stores. Amazon ElastiCache is a popular choice for real-time use cases like Caching, Session Stores, Gaming, Geospatial Services, Real-Time Analytics, and Queuing.
從上面的敘述可以看出 Elasticache 服務的特性:
用來儲存應用中常被存取的資料,具有高速低延遲的特性
資料儲存在記憶體中,速度非常的快
常被用來作為快取、session 儲存、即時資料分析 … 等用途
Elasticache Engine Type
Elasticache 提供兩種 Engine Type,分別是 Redis & Memcached,以下是兩者的比較表:
| 需求 | Memcached | Redis |
|---|---|---|
| 加速 DB 存取的快取功能 | Yes | Yes |
| 可水平擴展 | Yes | Yes |
| 多執行緒效能 | Yes | No |
| 可存放進階的資料結構 | No | Yes |
| 資料集合排序功能(Ranking/Sorting) | No | Yes |
| 訂閱/通知(Pub/Sub)功能 | No | Yes |
| 可持久性(Persistence) | No | Yes |
| Backup & Restore | No | Yes |
簡單來說:
若是要簡單且立即可用的快取功能,那就選 Memcached
若是希望功能強大一點,那就選 Redis
應考重點
Elasicache 主要用來增加 DB & web application 的效能 (資料讀取密集的相關操作可以轉到 Elasticache 處理,可以大幅降低 DB 負擔)
搭配 Elasticache,可以避免查詢行為一直打進 DB,直接透過 cache 回應,可以大幅降低 request response time,同時也可以降低 DB 的負載
協助 application 成為 stateless 的關鍵
Redis 支援 Multi-AZ
Redis 可使用 Backup & Restore 功能
若使用 MySQL DB,甚至可以搭配 Memcached plugin,讓 application 在查詢 DB 時,享受到 cache(Elasticache) 的優勢
Elasticache Redis 是 HIPAA eligible service,因此可以用來與醫療相關需求進行配合