Load Balancer
AWS 提供三種 Load Balancer 類型,分別是:
Application Load Balancer
Network Load Balancer
Classic Load Balancer
Application Load Balancer
分流 HTTP & HTTPS 流量的最佳選擇
Application aware,可以讓源端的服務獲得額外的資訊(例如:使用者所在位置、使用的語系…等等)
可以根據使用者資訊 & 條件設定 request routing policy,將流量導向特定的服務
可以透過設定
target group,讓 traffic 根據不同的規則進到不同 target group 中的 instance支援很多進階功能,例如:ECS、HTTPS、HTTP2、WebSockets、Access Logs、Sticky Sessions、AWS WAF(Web Application Firewall) … 等功能
Network Load Balancer
分流 TCP traffic(Layer 4) 的最佳選擇
效能非常好,可以輕鬆處理每秒百萬級別的 request,且保持低延遲的狀態
Classic Load Balancer
其實前身就是 ELB(Elastic Load Balancer)
可以同時處理 Layer 7 & Layer 4 的流量
支援 Layer 7 特性,例如:X-Forwarded-For & sticky session
但其他更進階的設定則是沒有支援,必須改用 ALB or NLB
源端服務若是有問題,會回應 504 Error(Gateway Timeout)
只能將 traffic 平均分散在後方所有的 EC2 instance 上
其他
ELB 應該與 Auto Scaling Group 搭配使用,藉此達到 HA、fault tolerance、automatic scale out/in … 等目的
ELB 也可以作為內部流量(private subnet)的 load balancer 之用
若有設定好 health check,ELB 就不會將 traffic 導向當下狀態是故障的 instance
若希望服務可以掛上 TLS(HTTPS),ELB 可以協助做 SSL offloading 的工作,可以節省 EC2 instance 的計算資源
若是 Load Balancer 回應 504 Error(Gateway Timeout),就是源端的服務出問題,超過 idle timeout 的設定
此時就需要去檢查 web server or DB service … 等等
當網路流量經過 load balancer 進入終端 server,且需要在終端 server 取得來源使用者的 IP,就需要查看
X-Forwarded-ForheaderLoad Balancer 都會提供一個 DNS name,不會給 IP address
考試前請認真讀一下 Elastic Load Balancing FAQs,會出不少關於三種不同 LB 差異的考題
當要考慮到
HA&fault tolerance,就必須至少要有 ELB + ASG(cross AZ + 最少兩個 instance) 這樣的組合Classic Load Balancer 不支援
Server Name Indication(SNI)(可在同一個 load balancer 上設定支援多個 HTTPS domain),目前僅有 ALB/NLB/CloudFront 支援 SNI
Health Check
從 Load Balancer 角度來監控 target(Instance, IP or Labmda),會有
InService&OutofService兩種狀態Health check 的機制是透過不斷的詢問 target 實現的
Advanced Load Balancer 須知
Sticky Session
sticky session 可以讓使用者使用固定的 EC2 instance(透過將 user session 與固定的 instance 綁定)
若是在某些應用會將使用者相關資訊存在本機上時特別有用
若開啟 sticky session,當某位使用者的流量被導向到特定的 instance 後,他就會一直被導向同樣的 instance
ALB 也支援 sticky session,但流量僅能導向 target group level
Cross-Zone Load Balancing
簡單來說,Cross Zone Load Balancing 可以讓 Load Balancer 將流量分散到不同的 AZ 上,細節的部份可用以下三張圖說明,在那之前有幾個假設狀況:
使用者存取某個在 Route 53 設定好的 domain name
domain name 指定兩筆記錄,分別指到不同 AZ 的兩個 Load Balancer
預設情況下,Route 53 會引導各 50% 的流量到不同 AZ 上的 Load Balancer
Cross Zone Load Balancing 在 ALB 預設是開啟的,但在 NLB 預設是關閉的
未開啟 Cross-Zone Load Balancing
首先是一般情況下沒有開啟 Cross Zone Load Balancing 功能的情況下:
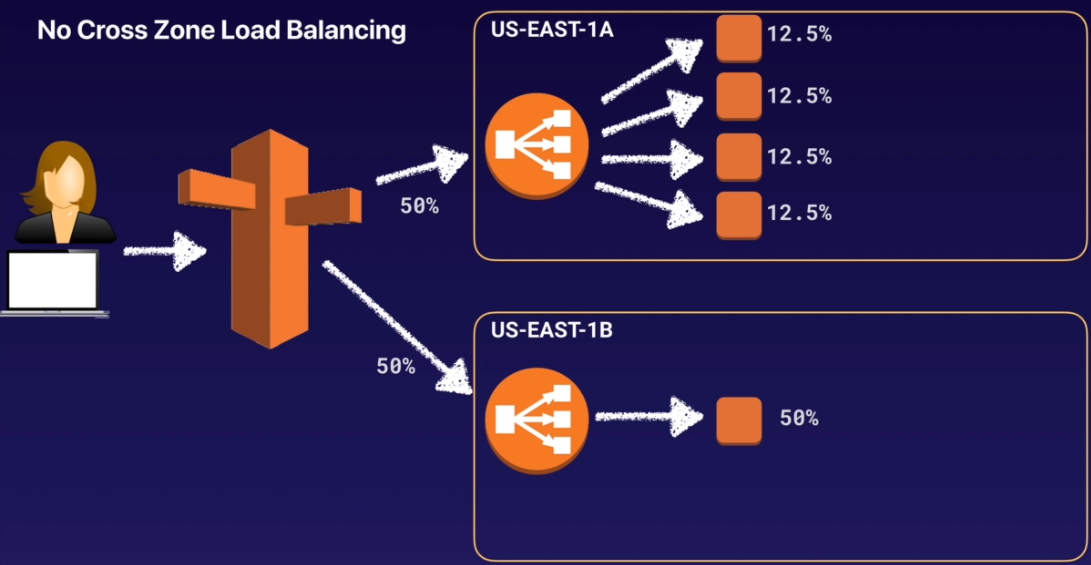
上面的 AZ 有四個 instance,下方的 AZ 僅有一個 instance
每個 AZ 都得到 50% 的流量
上方的四個 instance 共同分攤了 50% 的流量,但下方單獨的 instance 一台就扛了該 AZ 所有的流量
開啟 Cross-Zone Load Balancing
很明顯上面的流量分配是有問題,還是有優化空間的,這時候就可以透過開啟 Cross-Zone Load Balancing 功能來處理,當開啟了 Cross-Zone Load Balancing,流量的分配就會變成如下:
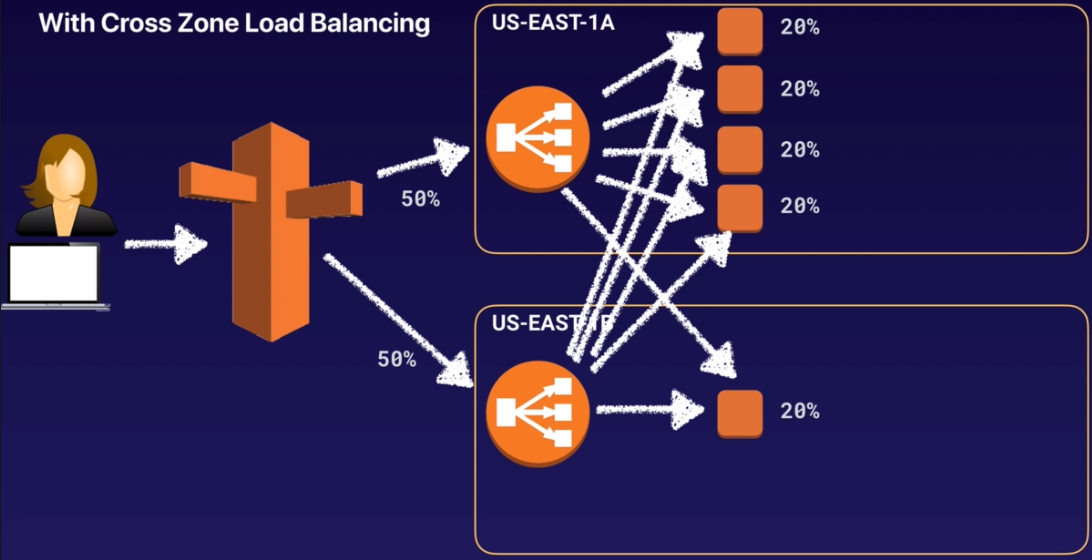
負載平均是以整體來計算,而非單一 AZ
下方 AZ 可以知道上方 AZ 中的 instance 所得到的流量相對少,因此就會有一部份流量會轉回上方 AZ 中
透過 ELB 將流量導向另外一個 AZ,藉此平均分散流量到 instance 上
ALB 預設開啟 Cross-Zone Load Balancing,inter-AZ 的傳輸費用是免費的;而 NLB 預設是關閉的,inter-AZ 的傳輸費用是要收費的
單一 AZ ELB + 開啟 Cross Zone Load Balancing
如果只有一個 AZ 有 ELB 的設定,加上開啟了 開啟 Cross Zone Load Balancing,會是怎麼樣呢? 結果會變成下圖:
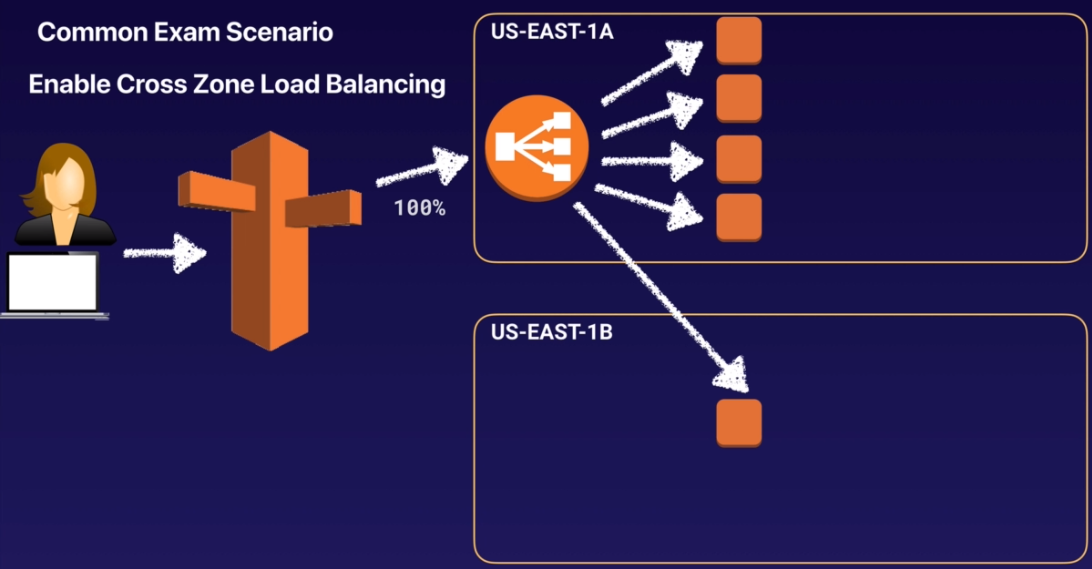
流量 100% 發到上方 AZ 的 ELB 上
但有 20% 的流量會跨 AZ 轉發到下方 AZ 的 instance 中
Path Patterns
簡單來說,path pattern 的功能是可以讓管理者根據 request url 來決定將流量導向不同的 EC2 instance 上,那實際上這是如何實現的呢?
建立 listener,並根據 url path 指定 rule
設定 target group,並與 listener 進行繫結,讓符合 listener rule 的流量導向指定的 target group
以下用一張圖進行範例說明:
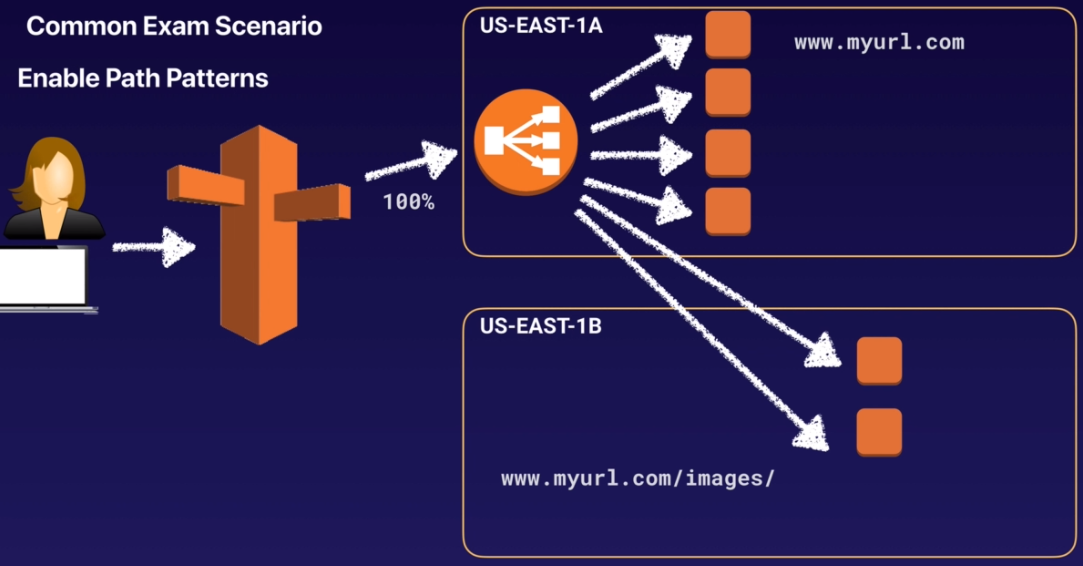
管理者設定兩個 target group,分別是上方 AZ 的四個 instance,與下方 AZ 的一個 instance
設定兩個 listener rules,分別是處理送往
www.myurl.com&www.myurl.com/images的流量將 listener rules 與 target group 繫結,符合第一個存取路徑的流量會導向上方 AZ 的 instance,而 image 相關的流量則會轉發到下方 AZ 中的 instance
Auto Scaling
Auto Scaling 是什麼?
Auto Scaling 是在公有雲上必用的功能之一,可以根據系統負載來自動調整資源佈署,以下是 AWS 官方對 Auto Scaling 這項功能的介紹:
AWS Auto Scaling monitors your applications and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost. Using AWS Auto Scaling, it’s easy to setup application scaling for multiple resources across multiple services in minutes. The service provides a simple, powerful user interface that lets you build scaling plans for resources including Amazon EC2 instances and Spot Fleets, Amazon ECS tasks, Amazon DynamoDB tables and indexes, and Amazon Aurora Replicas. AWS Auto Scaling makes scaling simple with recommendations that allow you to optimize performance, costs, or balance between them. If you’re already using Amazon EC2 Auto Scaling to dynamically scale your Amazon EC2 instances, you can now combine it with AWS Auto Scaling to scale additional resources for other AWS services. With AWS Auto Scaling, your applications always have the right resources at the right time.
看完上述介紹,重點就大概可以理解的差不多了,以下整理歸納一下:
Auto Scaling 的運作基礎在監控,有監控數據,才會有實現 auto scaling 的依據 (至於哪些數據可以被監控,就是比較細節的部份了)
Auto Scaling 並非 EC2 獨有的選項,也可以與 ECS、DynamoDB、Aurora … 等服務搭配
Auto Scaling 提供了一些特性讓整體設定變得簡單(例如:Launch Template、Scaling Option … 等等)
透過 Auto Scaling 可以協助優化資源使用率、降低成本
若要達成最小程度的 HA & Fault Tolerance,就必須使用 ELB + Auto Scaling Group(使用兩個 instance,設定為 cross AZ)
這功能看起來相當好用,誰不希望系統可以自動幫忙些什麼事情呢?
Auto Scaling 的組成
Auto Scaling 共分為三個部份,分別是:
Groups
這屬於邏輯上服務的群組,例如:一群 web server,一群 DB server
Configuration Templates
用來指示 Auto Scaling 機制,要自動生成的服務的樣貌,以 EC2 為例,就會有 AMI ID、instance type、key pair、security group、storage … 等資訊
Scaling Options
這是進行 Auto Scaling 的依據(or 規則),可能根據負載、或是特定時間;以及可以進行 Auto Scaling 的資源上下限;甚至包含當 auto scaling 發生時所要進行通知操作的 SNS 設定
有哪些 Scaling Option 可用?
Group & Configuration Template 都是相對容易理解的部份,這裡需要注意的是有哪些 scaling option 是可以設定的? 目前共支援五種,以下一一介紹。
Maintain current instance levels at all times
明確告知 ASG,無論何時都一定要有特定數量的 instance 存在
AWS 會定期對 instance 進行健康檢查
若是發現有不健康的 instance,就會把它移除,並重啟一個新的
Scale manually
這是最基礎的 ASG 設定方式
其實就只有指定 maximum, minimum, desired capacity 這三個參數作為 ASG 執行的依據(不一定全部都要設定)
Scale based on a schedule
根據指定的時間 or 日期進行伸縮
適合用在清楚知道 scale out/in 的時機
Scale based on demand
這是進階版的伸縮方式,透過提供 scaling policy 的方式達成
scaling policy 的依據可以來自監控的數據,例如:CPU 使用率
應該可以搭配自訂的監控數據,但要搞清楚如何串接 (這部份待確認)
Use predictive scaling
將 EC2 Auto Scaling 搭配 AWS Auto Scaling,進行多個服務的彈性伸縮
AWS Auto Scaling 可以透過預測的方式,對資源進行動態的伸縮,協助使用者維持最佳的可用性與系統效能
關於 Maximum, Minimum, Desired Capacity
有人可能會有疑問,若是 Desired Capacity 跟 Maximum or Minimum 設定衝突時怎辦? 原則大概如下:
Desired Capacity 是實際上使用者告訴 ASG 希望可以達到的目標
其他可能會造成這數字自動改變的行為,可能來自於 CloudWatch alarm,自動觸發的 instace scale out/in 的行為
當自動 scale out/in 行為被觸發,要一直維持 Desired Capacity 就會沒有辦法,因此就會需要 Maximum & Minimum 來規範上下限範圍
Auto Scaling 實作須知
設定 Auto Scaling Group 之前,必須先設定
Launch ConfigurationsorLaunch TemplateLaunch Configurations 只能有一組設定;而 Launch Template 可以設定不同 instance type(on-demand & spot) 的混搭
Group size 若是與 subnet 數量一致,佈署的時候就會被平均分散放置
可作為自動 scale group size 的 metric type 有四種,分別是:
Application Load Balancer Request Per Target
Average CPU Utilization
Avergae Network In (Bytes)
Average Network Out (Bytes)
可設定新增的 instance 開始提供服務時間之前的 warm up 週期
若是設定 300 秒,那該 instance 有五分鐘可以 warm up 的時間(根據需求自行處理此部份),然後前端的 ELB 才會將流量送過來
可以搭配 Auto Scaling Group Lifecycle hook,在 instance 啟動或中止時,預先執行指定的 custom script(例如:安裝特定軟體、將特定的 log 複製到 S3 留存 … etc),此時 instance 會處於 wait 狀態,若是前方有 ELB,ELB 也還不會將 traffic 分流過來
當 ASG 設定被移除,與其相關的 instance 也會一併被移除
若要針對 scale out 所新產生的做進行客製化的驗證,可以搭配 ASG lifecycle hook 將 instance 先設定為 wait state,並執行客製化的驗證
ASG 中 cooldown 階段的時間預設為 300 秒
預設可以拿來與 CloudWatch 搭配作為 ASG scale up/down 依據的 metric 包含有
CPU utilization,Network utilization,Disk performance、Disk Reads/Writes(注意!! 沒有memory utilization&disk space utilization!!)若是希望以
memory utilizationordisk space utilization作為 ASG scale up/down 的依據,那需要將 CloudWatch monitoring script 或是把 ClouwWatch agent 放進 EC2 instance 來達成透過
step scaling,可以設定好幾個階層的 threshold,並指定到達哪個 threashold 會對應增加 or 減少多少 EC2 instance
HA Architechture
此部份是記錄設計 HA(高可用) 架構時需要注意的重點
重點觀念
硬體一定會故障,基礎設施一定會有問題,因此必須 always design for failure
multiple AZ 的設計是必須的;如果是非常關鍵的應用,multiple region 的設計也可以考慮進來
搞清楚 RDS multi-AZ(避免故障導致無法服務) & read-replica(提昇效能) 的差異
設計高可用架構,成本支出必然提昇,因此了解成本結構,如何有效節省支出是一件很重要的事情
S3 storage tier 的差異需要了解(standard, standard-IA, Glacier …. etc)
實作課程中的重點整理
在 AWS Certified Solutions Architect: Associate Certification Exam | Udemy 課程中,有針對 HA 架構實作了一個 WordPress 的網站,過程中有一些值得記錄的重點:
EC2 instance 中有設定 policy 可以存取 S3,因此可以將靜態資源上傳到 S3 上,但缺乏持續同步靜態資源的部份,因此持續同步的部份還是要另外處理
將靜態圖片從 EC2 instance 指向 CloudFront,是透過 url rewrite 功能達成的;這功能一般在 web server 都會有,可以善用
範例中 S3 是設定可以 public read;但基於安全性需求,可以搭配 OAI(Origin Access Identity) 設定改成只有 CloudFront 可以 read …
設定 ALB 時要指定到後方的 Target Group;而 Target Group 則是指到後方已經設定好 WP 的 EC2 instance
若要在二級域名(例如範例中的
acloudguru2019.com)直接指到 ALB,則是在 Route 53 中設定Aliasrecord二級域名並非使用 CName,而是要用 Alias
其他
CloudFormation
CloudFormation 跟之前研究 OpenStack 時學到的 HEAT 看起來幾乎是一模一樣概念的東西;基本上概念是這樣:
是種 Infrastructure as Code 的工具
透過預先定義好的 template 快速產生環境(稱為
stack)的一種工具AWS 已經預先定義好非常多 template 了,甚至還有很多廠商也提供了不少現成的 template 可以直接套用
如果你的環境很固定是要跑特定的應用,那倒是可以試試看
基本上這套工具並不吸引我,我個人是會選擇泛用性更高的工具,例如:Terraform or pulumi 來做一樣的事情,避免被特定平台綁死。
Elastic Beanstalk
這服務就是很簡單很快的給使用者一個特定的環境(例如:PHP),然後後續的調整在自己慢慢來,基本上概念是這樣:
AWS 快速產生一個可運行的特定環境給使用者
AWS 幫忙處理掉像是 provisioning、Load Balancing, scaling, application health monitoring 這些複雜瑣碎的事情了
使用者再根據需求自己慢慢調整
可以後續設定比較進階的功能來搭配,例如:Auto Scaling Group
但其實很多東西在本地環境就可以測試了,尤其現在 Docker 這麼方便…..相信這服務會慢慢式微的….XD
References
Introducing Application Load Balancer – Unlocking and Optimizing Architectures | AWS DevOps Blog
Configure Sticky Sessions for Your Classic Load Balancer - Elastic Load Balancing
Configure Cross-Zone Load Balancing for Your Classic Load Balancer - Elastic Load Balancing
Listeners for Your Application Load Balancers - Elastic Load Balancing
Scaling the Size of Your Auto Scaling Group - Amazon EC2 Auto Scaling