S3 CORS(Cross-Origin Resource Sharing)
原理說明
CORS(Cross-Origin Resource Sharing) 的議題很多時候總是會讓很多人搞不清楚如何正確的處理,而這個問題卻時常在 S3 發生,原因是因為 S3 常被用來存放靜態資源,而主站域名通常與靜態資源存放的域名並不相同,因此往往就會需要處理 CORS 的問題,若是過一層 CDN 那這件事情又會再變得複雜一點;但無論如何,搞清楚運作原理,會讓處理 CORS 的問題更有明確的方向。
以下透過一張圖來解釋一下 CORS 的狀況是怎麼發生的:

(圖中 1) 在上面這張圖上,首先要先搞清楚
Origin是什麼,在圖中的 Web Browser 一開始存取的是http://www.example.com,因此Ogitin = http://www.example.com(圖中 2 & 3) 但在上一個步驟取到的網頁中,裡面卻要 Web Browser 再向另一個域名
http://www.other.com取得其他資源,此時因為資源所在的域名跟 Origin 不同,所以變成了 Cross Origin 的存取,因此Cross Origin = http://www.other.com;這時候 Web Browser 就需要送一個 preflight request(OPTION) 給 Cross Origin 的域名,詢問是否可以進行 cross origin 的存取(圖中 4) 域名
http://www.other.com的主機對於 preflight check 的回應會包含Access-Control-Allow-Origin&Access-Control-Allow-Methods,Web Browser 拿到之後就會知道有沒有被允許繼續往下取得資源(圖中 5 & 6) Web Browser 確認域名
http://www.other.com的主機是允許 CORS 的,因此就按照一般取得資源的流程繼續往下走(但在 request header 中會多帶上ORIGIN的資訊);而上個步驟的與 CORS 相關的 header 資訊也都會一併帶在這個域名的 request response 中
案例
以下同樣用一張圖來介紹一個 CORS 的實際案例:
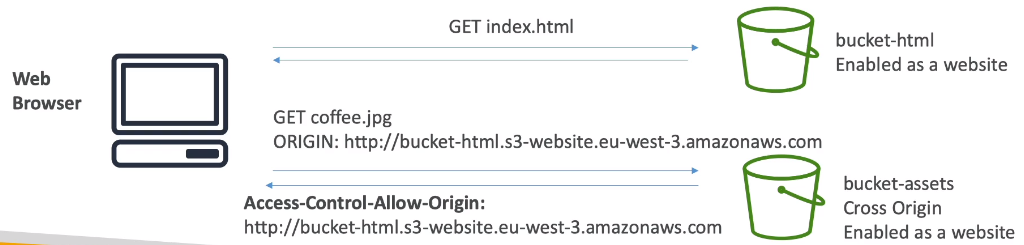
Web Browser 一開始向
http://bucket-html.s3-website.eu-west-3.amazonaws.com取得 index.htmlindex.html 中包含了要求去取得另一個域名的資源(此時就變成了一個 CORS 的存取),因此在取得此資源時,除了 resource URI 之外,還會帶上
ORIGIN的資訊 (圖中略過了 preflight check)另一個域名的主機若是有允許 request header
ORIGIN的域名,那就會回應正確的內容,並帶上Access-Control-Allow-Originheader
如何預設將檔案加密
若要強化資料安全性,將檔案加密是一個常見的手段,但在 S3 的檔案要怎麼強制上傳的檔案被加密呢? 基本上有兩種方式:(這裡提的是 server-side encryption)
使用 Bucket Policy
由於上傳檔案時要指定檔案需要加密,需要傳入特定的 header x-amz-server-side-encryption,因此可以透過設定以下 bucket policy 來限定檔案上傳時必須要加密:(參考資料來源)
1 | { |
Default Encryption
這個可以直接在 bucket level 設定,設定完成後,所有上傳到 bucket 的檔案都會預設以指定的加密形式進行加密。
注意事項
需要注意的是,Bucket Policy 的規則檢查的優先順序在於 Default Encryption 之前,因此若是兩者設定上有衝突,那可能會有非預期的結果發生。
Pre-signed URL
S3 pre-signed URL 可以為沒有開啟存取權限的 S3 bucket 提供臨時的 download/upload 權限,常用的情況可能像是:
僅允許登入後的使用者從 S3 bucket 下載特定影片
動態的開放使用者可存取特定檔案的權限
僅允許使用者暫時可上傳檔案到特定的位置
而這功能有以下幾個特點:
download URL 可透過 SDK or CLI 產生,但 upload URL 僅能透過 SDK 產生
預設有效時間為 3600 秒,可透過
--expires-in [TIME_BY_SECONDS]參數來進行調整pre-signed URL 所擁有的權限繼承自建立 URL 的使用者的權限
最後,透過 CLI 產生 pre-signed url 的方式可以參考官網文件。
S3 Inventory
S3 Inventory 的功能可以列出在 bucket 的所有 object & 對應的 metadata 作為後續分析之用,而此功能可能運用的場景有:
提供稽核相關的報表用
定期取得 S3 bucket 中檔案的數量 & 使用量
而此功能有以下幾個特色:
可以根據查詢需求,產生日報表 or 週報表;同時也有 filter 的功能
輸出的形式有 CSV、ORC or Apache Parquet …. 等格式
可透過 AWS Athena、Redshift、Presto、Hive、Spark … 等工具進行查詢
Lifecycle Rules
S3 Lifecycle Rule 中可以設定的 action 分成兩個部份,分別是 Transition & Expiration。
transition action 是用來定義什麼情況下 object 要在不同的 storage class 移動,例如:
將建立超過 60 天的 object 移動到 Standard IA
將建立超過 6 個月的 object 移動到 Glacier
而 expiration action 則是用來定義什麼情況下 object 會過期(or 刪除),例如:
access log 相關檔案在建立的 365 天後移除
自動移除舊版本的檔案 (必須啟用 versioning 功能)
自動移除未上傳完整的 multi-part object
另外一個需要注意的是,上述的規則可以套用在特定的 prefix(例如:s3://mybucket/test_path/*),也可以套用在包含指定 tag(例如:department: finance) 的 object 上。
S3 Analytics
這是可以用來協助使用者分析目前 S3 bucket 中 object 的狀況,並提供相關報告建議使用者可以何時將 object 從
STANDARD轉移到STANDARD_IA的功能。無法用在
ONEZONE_IAorGLACIER上報告每天會更新一次,第一次啟動需要 24~48 小時的時間
若是不曉得如何制定合適的 lifecycle rule,是可以考慮使用的一個服務
S3 Performance
若是想要提昇存取 S3 時的效能,了解關於此議題的相關設計是很重要的,而以下列舉與 S3 存取效能有關的議題
Baseline Performance
S3 是一個可以自動擴展以提供更高的存取性能的服務,而存取性能的單位上限來自於 prefix;每個 prefix 可以達到以下存取效能:
3,500 PUT/COPY/POST/DELETE
5,500 GET/HEAD
因此要提高 S3 存取效能,很直觀的方式就是增加 prefix 數量,舉例來說:
若是將所有 object 放在同一個 prefix(例如:
bucket/folder1/files[1-9999], prefix =/folder1/),那這樣存取效能就會很普通若是將 object 分散在多個 prefix(例如:
bucket/folder[1-9999]/files[1-9999]),在存取不同 prefix 時,存取的限制都是分開計算的,在大量資料的取用下,效能就會有顯著提昇
S3 KMS 存取限制
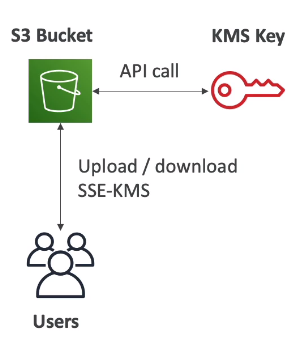
若是 S3 使用 KMS 加密(SSE-KMS),那在大量存取 object 時可能會碰到 KMS 的存取額度上限,因此在 object 的上下傳行為中,會進行兩次 KMS API call,分別是:
upload:
GenerateDataKeydownload:
Decrypt
而目前 KMS quota 根據所在 region 的不同分別是 5500 ~ 30000 request/sec 不等,若是真的有大量存取需求,可能需要注意會不會碰到這個存取限制。
若是真的會超過,可以開 ticket 申請增加 service quota
Multi-Part upload
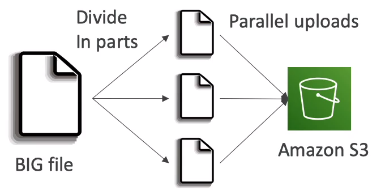
可以將大檔案分成多個部份以平行的方式上傳,藉此提高傳輸效率;建議檔案大小超過 100MB 時使用,而若是檔案超過 5GB 就一定得使用 multi-part upload,否則會上傳失敗
沒有上傳順序問題,最大可以分成 10,000 個 part
Byte-Range Fetch
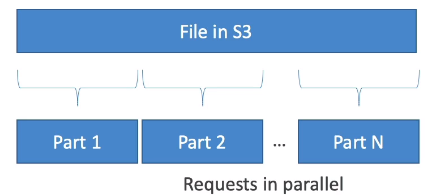
有分段平行上傳的功能,自然也有對應的下載功能,而分段平行下載的功能稱為 Byte-Range Fetch,實現原理是將檔案分成多個部份,以平行的方式下載以提昇傳輸效率。
而若是只要取得檔案中的某一段內容,也可以使用此功能來達成,例如以下是取得檔案前段內容的範例:

S3 Transfer Acceleration
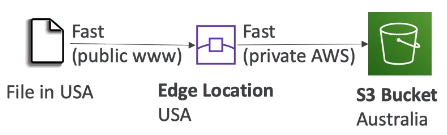
其實現原理是的利用 AWS 佈署在全球的 edge 節點,並搭配 AWS 自己的骨幹網路,讓使用者就近傳到 edge 節點後,走骨幹網路快速的將資料送回給指定的 bucket。
S3/Glacier Select
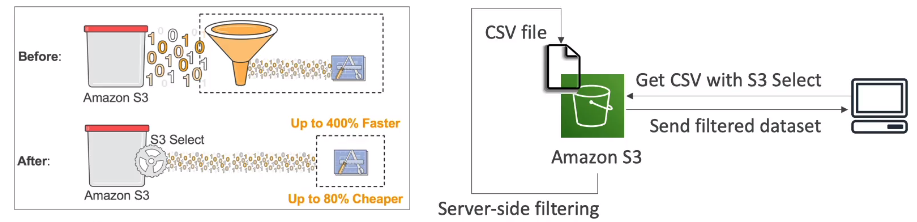
這功能只能用於 CSV & JSON 格式存放的 object
可以指定取得檔案中符合查詢結果的內容,而非所有內容;因此有機會可以大幅減少需要傳輸的檔案內容來提昇傳輸效率
S3 Glacier
之前的文章中有提到過 Glacier 的特色,這邊繼續進行一些更深入的探討:
每個存放在 Glacier 的 object 稱為
Archive,最大的容量是 40TBArchive 統一存放在稱為
Vault中
Glacier Operations
相關的操作可以從 Glacier & Vault 兩個角度來看:
Glacier 相關操作:
- Upload:指的是上傳 archive
- Download:這裡要分為幾個步驟,分別是:
- 首先要向 Archive initiate 一個 retrieve job
- Glacier 需要花點時間準備
- 準備完成後,使用者會需要在限定的時間內下載指定的檔案(from staging server)
- Delete:這需要透過 API or SDK 指定特定的 Archive ID 來完成
Vault 相關操作:
- Create/Delete:只能在已經沒有任何 Archive 在 Vault 裡面時才可以執行
- Retrieve Metadata:用來取得 creation date、archive 數量、archive 使用空間 … 等資訊
- Download Inventory: 列出存在於 Vault 中的 archive 資訊
Restore Link 是會過期的;這在建立 restore job 時可以指定
Vault Policy/Lock
每個 Vault 只能有一個 access policy & lock policy
Access Policy 跟 bucket policy 是一樣的;Lock Policy 則是通常用來進行合規相關的制定(例如:幾年內資料不能刪除)
S3 Access Points
S3 本身就提供了資料存取的功能,而 Access Point 通常是為了管理上的需求,或是降低存取管理上的複雜度,提出的一個將存取管理再包裝一層的作法,使用上有些需要注意的地方:
每個 Access Point 都有自己專屬的 DNS
在 Account + Region 的條件下,名稱是唯一的 (不像是 S3 bucket name 需要 global unique),且連結到特定的 bucket
可針對每個 access point 設定對應的 policy 進行存取限制