高性能 DB cluster:讀寫分離
大部分情況下做架構設計主要都是基於已有的成熟模式,結合業務和團隊的具體情況,進行一定的優化或者調整
即使少部分情況需要進行較大的創新,前提也是需要對已有的各種架構模式和技術非常熟悉
不管是為了滿足業務發展的需要,還是為了提升自己的競爭力,RDBMS 廠商(Oracle、DB2、MySQL … 等)在優化和提升單一 DB server 的性能方面也做了非常多的技術優化和改進
但業務發展速度和數據增長速度,遠遠超出 DB 廠商的優化速度
互聯網業務興起之後,海量用戶加上海量數據的特點,單個 DB server 已經難以滿足業務需要,必須考慮 DB cluster 的方式來提升性能
讀寫分離原理
- 讀寫分離的基本原理是將 DB 讀寫操作分散到不同的 node 上
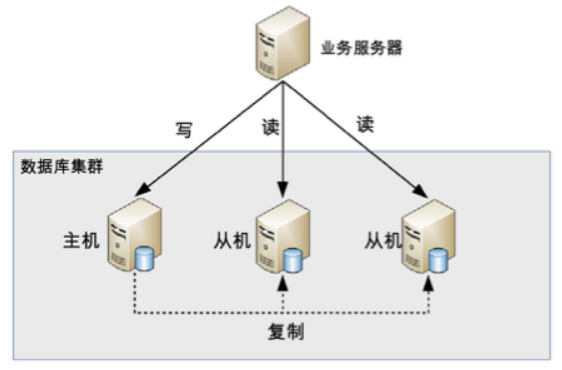
讀寫分離的基本實現是:
- DB server 搭建 master/slave cluster ,one master/one slave、one master/multiple slave 都可以
- DB master 負責 read/write 作業,slave 只負責 read 作業
- DB master 通過複製將數據同步到 slave,每台 DB server 都儲存了所有的業務相關資料
- 線上服務將 write 作業發給 DB master,將 read 作業發給 DB slave
需要注意的是,這裡用的是
master/slave cluster,而不是 `primary/backup cluster”slave需要提供讀數據的功能的;而backup一般被認為僅僅提供備份功能,不提供存取功能讀寫分離的實現邏輯並不複雜,但是會引入兩個複雜度:
主從複製延遲&分配機制
主從複製延遲
以 MySQL 為例,主從複製延遲可能達到 1 秒,如果有大量數據同步,延遲 1 分鐘也是有可能的
解決主從複製延遲有幾種常見的方法:
- write 操作後的 read 操作指定發給 DB master server:和業務強綁定,對業務的侵入和影響較大
- 讀 slave 失敗後再讀一次 master:如果有很多二次讀取,將大大增加主機的 read 操作壓力
- 關鍵業務 read/write 操作全部指向 master,非關鍵業務採用讀寫分離
分配機制
將 read/write 操作區分開來,然後訪問不同的 DB server ,一般有兩種方式:程序程式封裝和 middleware 封裝
程式封裝
程式封裝指在程式中抽象出一個數據訪問層(or 中間層封裝),實現讀寫操作分離和 DB server 連接的管理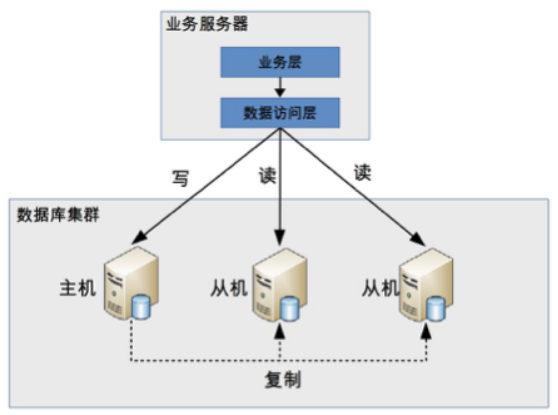
程式封裝的方式具備幾個特點:
- 實現簡單,而且可以根據業務做較多定製化的功能。
- 每個程式語言都需要自己實現一次,無法通用,如果一個業務包含多個程式語言寫的多個子系統,則重複開發的工作量比較大。
- 故障情況下,如果主從發生切換,則可能需要所有系統都修改設定 & 重啟。
middleware 封裝
middleware 封裝指的是獨立一套系統出來,實現讀寫操作分離和 DB server 連接的管理
middleware 對服務提供 SQL 兼容的協議,服務本身無須自己進行讀寫分離
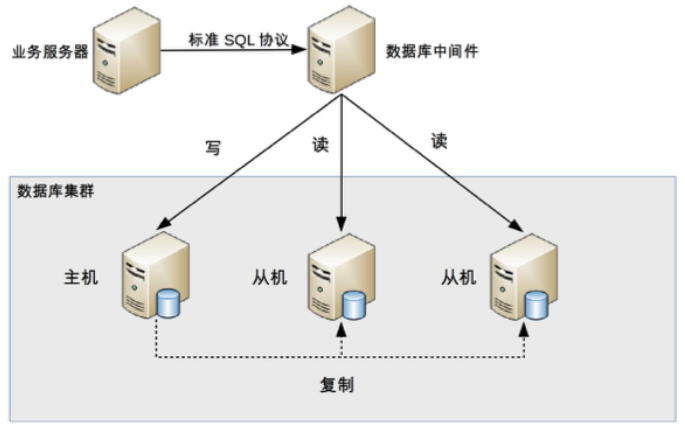
DB middleware 的方式具備的特點是:
- 能夠支持多種程式語言,因為 DB middleware 對服務提供的是標準 SQL 接口
- DB middleware 要支持完整的 SQL 語法和 DB server 的協議(例如:MySQL client 與 server 的連接通訊協定),實現比較複雜,細節特別多,很容易出現 bug,需要較長的時間才能穩定
- DB middleware 自己不執行真正的讀寫操作,但所有的 DB 操作請求都要經過 middleware,因此對於 middleware 的性能要求也會需要很高
- DB master/slave 切換對服務來說是無感的,DB middleware 可以偵測 DB server 的主從狀態(例如:向某個測試 table 寫入一筆資料,成功的就是 master,失敗的就是 slave)
由於 DB middleware 的複雜度要比程式封裝高出許多,一般情況下建議採用程序語言封裝的方式,或者使用成熟的開源 DB middleware(例如:MySQL Router, Apache ShardingSphere, Mycat)
討論整理精華
不需要有性能問題就馬上進行讀寫分離,而是應該先優化(例如:優化 slow query,調整不合理的業務邏輯,引入 cache 等,只有確定系統沒有優化空間後,才考慮讀寫分離或者 cluster
在單機 DB 情況下,table 加上 index 一般對查詢有優化作用卻影響寫入速度,讀寫分離後可以單獨對 read DB 進行優化,write DB 上減少 index,對讀寫的能力都有提升,且讀的提升更多一些
如果並發寫入特別高,單機寫入無法支撐,就不適合加入 index 的方式解決(加入 index 只會加重寫入負擔)
可改用 cache 技術或者程序優化的方式滿足要求
因為業務查詢的關係,multiple table 之間的關聯,聚合,很難避免,但是查詢的條件太多,很動態,設計 cache 的方式:
- 按照 80/20 原則,選出佔訪問量 80% 的前 20% 的請求條件進行 cache
- 大部分人的查詢不會每次都非常多條件,以手機為例,查詢蘋果加華為的可能佔很大一部分
交易型業務 cache 應用不多, cache 一般都會用在查詢類業務上 (事實上大部分業務場景可能並不需要讀寫分離)
讀寫分離適用於單一 server 無法滿足所有請求的場景,從請求類型的角度對 server 進行拆分;在要求硬體資源能夠支撐的同時,對程式效能也會有更高的要求
一次刪除大量資料可能造成 master/slave 不同步 => 線上 delete 每次不能超過 1000 筆資料,超過就定時循環操作
middleware 並不是性能上有優勢,而是可以跨語言誇系統重複使用,大公司才有實力做(否則就選擇現有的成熟開源方案)
同步速度主要受網路延遲影響,和硬體關係不大
如果 cache 能承受業務請求,其實一般不用做讀寫分離,例如論壇的帖子瀏覽場景
高性能 DB cluster:分庫分表
讀寫分離分散了 DB 讀寫操作的壓力,但沒有分散儲存壓力,當數據量達到千萬甚至上億條的時候,單台 DB server 的儲存能力會成為系統的瓶頸;這樣的狀況會造成以下問題:
數據量太大,讀寫的性能會下降,即使有 index,index 也會變得很大,性能同樣會下降。
數據文件會變得很大, DB backup & restore 需要耗費很長時間
數據文件越大,極端情況下丟失數據的風險越高(例如,機房火災導致 DB master/slave 都發生故障)
分庫
業務分庫指的是按照業務模組將數據分散到不同的 DB server
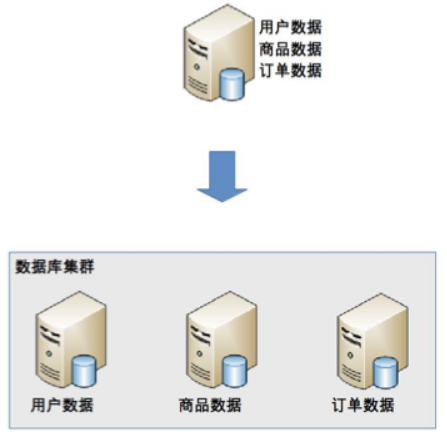
雖然業務分庫能夠分散儲存和訪問壓力,但同時也帶來了新的問題:
- join 操作問題:原本在同一個 DB 中的 table 分散到不同 DB 中,導致無法使用 SQL 的 join 查詢
- 事務問題:業務分庫後,table 分散到不同的 DB 中,無法通過事務統一修改
- 成本問題:業務分庫同時也帶來了成本的代價,本來 1 台 server 可以搞定的事情,現在要 3 台,如果考慮備份,那就是 2 台變成了 6 台
對於小公司初創業務,並不建議一開始就這樣拆分,主要有幾個原因:
- 初創業務存在很大的不確定性,業務不一定能發展起來,業務開始的時候並沒有真正的儲存和訪問壓力,業務分庫並不能為業務帶來價值
- 業務分庫後,表之間的 join 查詢、 DB 事務無法簡單實現了
- 業務分庫後,因為不同的數據要讀寫不同的 DB,程式中需要增加根據數據類型對應到不同 DB 的邏輯,增加了工作量;而業務初創期間最重要的是快速實現、快速驗證,業務分庫會拖慢業務節奏
如果業務真的發展很快,豈不是很快就又要進行業務分庫了? 那為何不一開始就設計好呢?
- 這裡的”如果”事實上發生的概率比較低
- 如果業務真的發展很快,後面進行業務分庫也不遲
- 單台 DB server 的性能其實也沒有想像的那麼弱
對於業界成熟的大公司來說,由於已經有了業務分庫的成熟解決方案,並且即使是嘗試性的新業務,用戶規模也是海量的,這與前面提到的初創業務的小公司有本質區別,因此最好在業務開始設計時就考慮業務分庫
分表
如果業務繼續發展,同一業務的單一 table 數據也會達到單台 DB server 的處理瓶頸
單一 table 數據拆分有兩種方式:
- 垂直分表:對應到表的切分就是表記錄數相同但包含不同的 colume
- 水平分表:對應到表的切分就是表的 colume 相同但包含不同的 row data
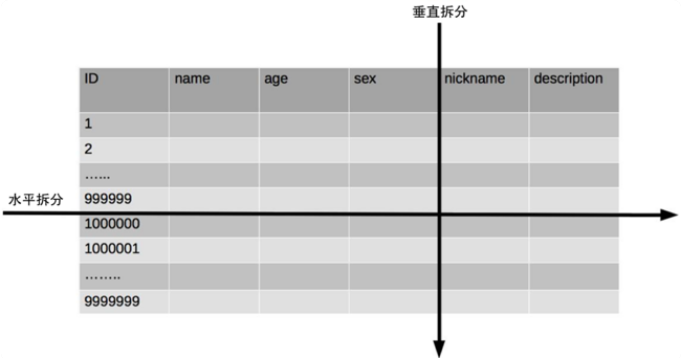
實際架構設計過程中並不侷限切分的次數,可以切兩次,也可以切很多次
單一 table 進行切分後,是否要將切分後的多個 table 分散在不同的 DB server 中,可以根據實際的切分效果來確定
單一 table 切分為多個 table 後,新的 table 即使在同一個 DB server 中,也可能帶來可觀的性能提升
如果單一 table 拆分為多個 table 後,單台 server 依然無法滿足性能要求,那就不得不再次進行業務分庫的設計了
垂直分表引入的複雜性
垂直分表適合將表中某些不常用且佔了大量空間的 colume 拆分出去
垂直分表引入的複雜性主要體現在 table 操作的數量要增加
水平分表引入的複雜性
路由
常見的路由算法:
範圍路由:選取有序的 data colume (例如:integer、timestamp … 等等)作為路由的條件,不同分段分散到不同的 DB table 中
- 複雜點:主要體現在分段大小的選取上,分段太小會導致切分後子表數量過多,增加維護複雜度
- 優點:可以隨著數據的增加平滑地擴充新的表
- 缺點:分佈不均勻
Hash 路由:選取某個 colume(或者某幾個 colume 組合也可以)的值進行 Hash 運算,然後根據 Hash 結果分散到不同的 DB table 中
- 複雜點:主要體現在初始 table 數量的選取上,table 數量太多維護比較麻煩,table 數量太少又可能導致單一 table 性能存在問題
- 優點:table 分佈比較均勻
- 缺點:擴充新的 table 很麻煩,所有數據都要重分佈
配置路由:配置路由就是路由表,用一張獨立的 table 來記錄路由信息
- 優點:設計簡單,使用起來非常靈活
- 缺點:必須多查詢一次,會影響整體性能;而且路由表本身如果太大(例如:幾億條數據),性能同樣可能成為瓶頸
join 操作
平分 table 後,數據分散在多個 table 中,如果需要與其他 table 進行 join 查詢,需要在業務程式或者 DB middleware 中進行多次 join 查詢,然後將結果合併
count() 操作
水平分表後,雖然物理上數據分散到多個表中,但某些業務邏輯上還是會將這些 table 當作單一 table 表來處理
常見的處理方式有下面兩種:
count() 相加:實現簡單,缺點就是性能比較低
count 資料表
- 性能要大大優於 count() 相加的方式
- 也增加了 DB 的寫壓力
- 複雜度增加不少,對子表的操作要同步操作”記錄數表”,如果有一個業務邏輯遺漏了,數據就會不一致
對於一些不要求 count 數據即時保持精確的業務,也可以通過後台定時更新 count 資料表
order by 操作
水平分表後,數據分散到多個子表中,排序操作無法在 DB 中完成,只能由業務程式或者 DB middleware 分別查詢每個子表中的數據,然後彙總進行排序
實現方法歸納
和 DB 讀寫分離類似,分庫分表具體的實現方式也是
程式封裝和middleware 封裝,但實現會更複雜讀寫分離實現時只要識別 SQL 操作是 read 作業還是 write 作業,通過簡單的判斷 SELECT、UPDATE、INSERT、DELETE 幾個關鍵字就可以做到
分庫分表的實現除了要判斷操作類型外,還要判斷 SQL 中具體需要操作的 table、操作函數(例如:count)、order by、group by 操作等,然後再根據不同的操作進行不同的處理
討論整理精華
DB 優化的方向順序建議:
- 進行硬體優化,例如:將 HDD 換成 SSD、增加 CPU core
- 先做 DB server 的優化(例如:增加 index, 優化 slow query)
- 引入 cache 技術(例如:redis)減少 DB 壓力
- 服務與 DB table 優化,重構(例如:根據業務邏輯對程序邏輯做優化,減少不必要的查詢)
- 在這些操作都不能大幅度優化性能的情況下,不能滿足將來的發展,再考慮分庫分表,但也要有預估性
針對 Mysql,發現如果 colume 是 blob 型態,select 時有無包含此欄位,效率差異很大啊,這個是什麼原因?
blob 的欄位是和 row data 分開儲存的,而且 disk 上並不是連續的,因此 select blob 欄位會讓 disk 進入 random I/O 模式
分庫分表的實施前提:
- DB 存在性能問題,且用加索引、 slow query 優化、 cache 和讀寫分離都無法徹底解決問題的時候
- 複雜查詢對應的單一 table 數據量級一般超過千萬以上,或簡單查詢的單一 table 數據量級一般超過 5000 萬以上
- 對一致性要求不是特別高,只要求最終一致性
- 用 Hadoop 等大數據技術,因為業務需求、技術成本、時間成本無法解決該問題
分表評估:
- 業務對數據的操作主要集中在某些 colume 上,比較適合垂直分表
- 業務對數據的操作在整個表層面較均勻分佈,適合水平分表
分庫使用時機:
- 業務不複雜,但整體數據量已影響了 DB 的性能
- 業務複雜,需要分模組由不同開發團隊負責開發,這個時候使用分庫可以減少團隊間交流
分表時機:單一 table 數據量太大,拖慢了 SQL 操作性能
並不是 DB 性能不夠的時候就分庫分表,提升 DB 性能方式很多,若有其他能在單一 DB 操作的方式則毫不猶豫使用,因為使用分表有固有的複雜性(join操作,事務,order by … 等)
通常 DB 剛表現出壓力的時候,大部分原因不是因為業務真的發展到 DB 撐不住了,而是很多 slow query 導致的
高性能 NoSQL

RDBMS 存在如下缺點:
- 儲存的是 colume data,無法儲存數據結構
- schema 擴展很不方便(修改時可能會長時間鎖表)
- 在大數據場景下 I/O 較高(做統計)
- 全文搜尋功能比較弱(全文搜尋只能使用 like 進行整表掃瞄匹配,性能非常低)
NoSQL 方案帶來的優勢,本質上是犧牲 ACID 中的某個或者某幾個特性
不能盲目地迷信 NoSQL 是銀彈,而應該將 NoSQL 作為 SQL 的一個加強方式
常見的 NoSQL 方案分為 4 類:
- Key/Value store:解決 RDBMS 無法儲存數據結構的問題,以 redis 為代表。
- Document DB:解決 RDBMS 強 schema 約束的問題,以 MongoDB 為代表。
- Colume-Based DB:解決 RDBMS 大數據場景下的 I/O 問題,以 HBase 為代表。
- 全文搜尋引擎:解決 RDBMS 的全文搜尋性能問題,以 Elasticsearch 為代表。
Key/Value store
redis 是 Key/Value store 的典型代表,它是一款 open source 的高性能 Key/value cache 和儲存系統
RDBMS 實現 Key/Value 的功能很麻煩,而且需要進行多次 SQL 操作,性能很低
redis 的缺點主要體現在並不支持完整的 ACID 事務
redis 的事務只能保證隔離性(isolation)和一致性(consistency),無法保證原子性(atomic)和持久性(durability)
雖然 redis 並沒有嚴格遵循 ACID 原則,但實際上大部分業務也不需要嚴格遵循 ACID 原則
在設計方案時,需要根據業務特性和要求來確定是否可以用 redis,而不能因為 redis 不遵循 ACID 原則就直接放棄
Document DB
Document DB 最大的特點就是 no-schema,可以儲存和讀取任意的數據
目前絕大部分 Document DB 儲存的數據格式是 JSON(or BSON)
Document DB的 no-schema 特性,給業務開發帶來了幾個明顯的優勢:
- 新增欄位簡單
- 歷史數據不會出錯
- 可以很容易儲存複雜數據
Document DB 的這個特點,特別適合電商和遊戲這類的業務場景:
- 以電商為例,不同商品的屬性差異很大
- 即使是同類商品也有不同的屬性
上述的業務場景如果使用 RDBMS 來儲存數據,就會很麻煩,而使用 Document DB,會簡單、方便許多,擴展新的屬性也更加容易
缺點:
- 不支持事務,因此某些對事務要求嚴格的業務場景是不能使用 Document DB的
- 無法實現 RDBMS 的 join 操作,須多次查詢
Colume-Based DB
傳統 RDBMS 被稱為 Row-Based DB,優勢在於:
- 業務同時讀取 multiple row 時效率高
- 能夠一次性完成對 row 中的多個 colume 的寫操作,保證了針對 row data 寫操作的原子性和一致性
Colume-Based DB 的優勢是在特定的業務場景(海量數據進行統計)下才能體現,如果不存在這樣的業務場景,那麼 Colume-Based DB 的優勢也將不復存在,甚至成為劣勢
Colume-Based DB
- 優點:
- 節省 I/O
- 具備更高的儲存壓縮比
- 缺點:
- 若需要頻繁地更新多個 colume => 將不同 colume 儲存在 disk 上不連續的空間,導致更新多個 colume 時 disk 是 random write 操作(效率極差)
- 高壓縮率在更新場景下也會成為劣勢,因為更新時需要將儲存數據解壓後更新,然後再壓縮,最後寫入 disk
- 優點:
一般將 Colume-Based DB 應用在離線的大數據分析和統計場景中,因為這種場景主要是針對部份 row 的單一 colume 進行操作,且數據寫入後就無須再更新刪除
全文搜尋引擎
傳統的 RDBMS 通過 index 來達到快速查詢的目的,但是在全文搜尋的業務場景下,index 也無能為力,主要體現在:
全文搜尋的條件可以隨意排列組合,如果通過 index 來滿足,則 index 的數量會非常多。
全文搜尋的模糊匹配方式,索引無法滿足,只能用 like 查詢,而 like 查詢是 full table scan,效率非常低。
基本原理
全文搜尋引擎的技術原理被稱為
"倒排索引"(Inverted index),也常被稱為反向索引、置入檔案或反向檔案,是一種索引方法,其基本原理是建立單詞到文件的索引正排索引適用於根據文件名稱來查詢文件內容
倒排索引適用於根據 keyword 來查詢文件內容
使用方式
全文搜尋引擎的索引對象是
單詞和文件,而 RDBMS 的索引對象是key和row,兩者的術語差異很大,不能簡單地等同起來為了讓全文搜尋引擎支持關係型數據的全文搜尋,需要做一些轉換操作,即將關係型數據轉換為文件數據
目前常用的轉換方式是將關係型數據按照對象的形式轉換為 JSON 文件,然後將 JSON 文件輸入全文搜尋引擎進行索引
Elastcisearch 是分散式的文件儲存方式。它能儲存和檢索複雜的數據結構 - 以即時的方式序列化成為 JSON 文件
在 Elasticsearch 中,每個 field 的所有數據都是預設被索引的。即每個字段都有為了快速檢索設置的專用倒排索引
不像其他多數的 DB,Elasticsearch 能在相同的查詢中使用所有倒排索引,並以驚人的速度返回結果
討論整理精華
RDBMS 和 NoSQL DB 的選型。考慮幾個指標:
數據量、並發量、即時性、一致性要求、讀寫分佈和類型、安全性、運維性等;根據這些指標,軟體系統可分成幾類。- 管理型系統(例如:運營類系統),首選 RDBMS
- 大流量系統(例如:電商單品頁的某個服務),後台選 RDBMS,前台選內存型(Key/Value store)
- 日誌型系統(例如:原始數據)選 Colume-Based DB,日誌搜尋選倒排索引
- 搜尋型系統(例如:站內搜尋,非通用搜尋,如商品搜尋),後台選 RDBMS,前台選倒排索引。
- 事務型系統(例如:庫存、交易、記賬),選
關係型 + cache + 一致性協議,或新型 RDBMS - 離線計算(例如:大量數據分析),首選 Colume-Based DB,RDBMS 也可以
- 即時計算(例如:即時監控),可以選 time-series DB ,或 colume-based DB
將商品/訂單/庫存等相關基本信息放在 RDBMS 中(如MySQL,業務操作上支持事務,保證邏輯正確性),cache 可以用 redis(減少 DB 壓力),搜尋可以用 Elasticsearch(提升搜尋性能,可通過定時任務定期將 DB 中的資料同步到 ES 中)
多種方案搭配混用必然會增加應用的複雜性與增加運維成本,但同時也帶來了系統更多的靈活性
RDBMS 使用 index 加快查詢速度;Key/Value store 使用 memory 加快查詢速度;Elasticsearch 使用倒排索引加快查詢速度;Colume-Based DB 使用將 colume 單獨儲存來加快查詢速度
高性能 cache 架構
在某些複雜的業務場景下,單純依靠儲存系統的性能提升不夠的,典型的場景有:
- 需要經過複雜運算後得出的數據,儲存系統無能為力
- read-many, write less(讀多寫少)的數據,儲存系統有心無力
cache 就是為了彌補儲存系統在這些複雜業務場景下的不足,基本原理就是將可能重複使用的數據放到 memory 中,一次生成、多次使用,避免每次使用都去存取速度相較 memory 慢很多的儲存系統
cache 能夠帶來性能的大幅提升
單台 Memcache server 簡單的 key-value 查詢能夠達到 TPS 50,000 以上
cache 雖然能夠大大減輕儲存系統的壓力,但同時也給架構引入了更多複雜性
Cache penetration
cache penetration 是指 cache 沒有發揮作用,業務系統雖然去 cache 查詢數據,但 cache 中沒有數據,業務系統需要再次去儲存系統查詢數據。
通常情況下有兩種情況:
儲存數據不存在
在 cache 中找不到對應的數據,每次都要去儲存系統中再查詢一遍,然後返回數據不存在
cache 在這個場景中並沒有起到分擔儲存系統訪問壓力的作用
出現一些異常情況(例如:被 hacker 攻擊),故意大量訪問某些讀取不存在數據的業務,有可能會將儲存系統拖垮
可能解決方案:
如果查詢儲存系統的數據沒有找到,則直接設置一個預設值(可以是空值,也可以是具體的值)存到 cache 中,這樣第二次讀取 cache 時就會獲取到預設值,而不會繼續訪問儲存系統
使用 Bloom filter
實際應用上可能難以將所有 key 列出(例如:在分散式環境下很難完成這件事情)
cache 數據生成耗費大量時間或者資源
儲存系統中存在數據,但生成 cache 數據需要耗費較長時間或者耗費大量資源
剛好在業務訪問的時候 cache 失效了,那麼也會出現 cache 沒有發揮作用,訪問壓力全部集中在儲存系統上的情況
爬蟲來遍歷的時候,系統性能就可能出現問題
由於很多分頁都沒有 cache 數據,從 DB 中生成 cache 數據又非常耗費性能(order by limit 操作),因此爬蟲會將整個 DB 全部拖慢
爬蟲問題處理:(爬蟲並非攻擊)
- 識別爬蟲然後禁止訪問,但這可能會影響 SEO 和推廣
- 做好監控,發現問題後及時處理
Cache avalanche
當 cache 失效(過期)後引起系統性能急劇下降的情況
舊的 cache 已經被清除,新的 cache 還未生成,並且處理這些請求的 thread 都不知道另外有一個 thread 正在生成 cache ,因此所有的請求都會去重新生成 cache,都會去訪問儲存系統,從而對儲存系統造成巨大的性能壓力
常見解決方法有兩種:
更新鎖:
- 對 cache 更新操作進行加鎖保護,保證只有一個 thread 能夠進行 cache 更新,未能獲取更新鎖的 thread 要嘛等待鎖釋放後重新讀取 cache ,要嘛就返回空值或者預設值
- 分散式 cluster 的業務系統要實現更新鎖機制,則需要用到分散式鎖,如 ZooKeeper
後台更新:由後台 thread 來更新 cache ,而不是由業務 thread 來更新 cache
- 業務 thread 發現 cache 失效後,通過 message queue 發送一條消息通知後台 thread 更新 cache
- 後台更新既適應單機多 thread 的場景,也適合分散式 cluster 的場景,相比更新鎖機制要簡單一些
- 後台更新機制還適合業務剛上線的時候進行 cache 預熱
Hotspot cache
雖然 cache 系統本身的性能比較高,但對於一些特別熱點的數據,如果大部分甚至所有的業務請求都命中同一份 cache 數據,則這份數據所在的 cache server 的壓力也很大
cache 熱點的解決方案就是複製多份 cache 副本,將請求分散到多個 cache server 上,減輕 hotspot cache 導致的單台 cache server 壓力
不同的 cache 副本不要設置統一的過期時間,否則就會出現所有 cache 副本同時生成同時失效的情況,從而引發 cache 雪崩效應
討論整理精華
不要只從技術的角度考慮問題,結合業務考慮技術
將查詢條件組合成字符串再計算 md5,作為 cache key,優點是簡單靈活,缺點是浪費一部分 cache
DB 壓力大就可以考慮 cache 了
需要監控 cache 是否很快就滿了 or cache 命中率降低 … 等狀況,搭配告警進行處理
一般分頁 cache , cache id 列表,不要 cache 所有數據
系統不是達到一定的系統查詢性能瓶頸,別一開始就用 cache
就算是 cache 修改頻率是一分鐘, cache 在這一分鐘也是有很大作用的,因為一分鐘可能就是幾千上萬次讀操作了,所以不要認為一天都不修改的數據才能用 cache
MySQL cache & cache server 的比較:
- MySQL 第一種 cache 叫 sql 語句結果 cache ,但條件比較苛刻,程式設計師無法控制,一般 dba 都會關閉這個功能
- MySQL 第二種 cache 是 innodb buffer pool,cache 的是 disk 上的分頁數據,不是 sql 的查詢結果,sql 的執行過程省不了
- memcached、redis 這些實際上都是 cache sql 的結果,兩種 cache 方式,性能差異是很大的
因此,可控性,性能是 DB cache 和獨立 cache 的主要區別
一個好的 cache 設計方案應該從這幾個方面入手設計:
- 什麼數據應該 cache
- 什麼時機觸發 cache 和以及觸發方式是什麼
- cache 的層次和粒度(網關 cache 如 nginx,本地 cache 如單機文件,分散式 cache 如 redis cluster,process 內 cache 如 global variables)
- cache 的命名規則和失效規則
- cache 的監控指標和故障應對方案
- 可視化 cache 數據(例如:redis 具體 key 內容和大小)
監控爬蟲,發現問題後及時處理
監控 DB 的各項指標,發現逐步變慢後看看是不是爬蟲,只要系統還撐得住就讓它爬,撐不住就不讓它爬
分頁數據有很多排序規則,而且可能在某個時間點要上架新商品,就會有即時性的要求,請問這樣使用分頁 cache 真的合適嗎?
cache 是為瞭解決性能問題,實時性要求很高就不能用 cache 了,或者要做 cache 及時更新機制