單一 server 高效能模式:PPC 與 TPC
OS 、CPU、 Memory、Disk 、cache 、network 、程式語言、架構等,每個都有可能影響系統達到高效能
站在架構師的角度,當然需要特別關注高效能架構的設計。高效能架構設計主要集中在兩方面:
- 儘量提升單一 server 的效能,將單一 server 的效能發揮到極致
- 如果單一 server 無法支撐效能,設計 server cluster 方案
架構設計是高效能的基礎,架構設計決定了系統效能的上限,實作細節決定了系統效能的下限
單一 server 高效能的關鍵之一就是 server 採取的並發模型,並發模型有如下兩個關鍵設計點:
- server 如何管理 connection
- server 如何處理 request
以上兩個設計點最後都和 OS 的 I/O Model 及 process Model 相關。
- I/O Model:blocking、non-blocking、blocking、synchronous、asynchronous
- process Model:sinle process、multiple process、multiple thread
PPC(Process Per Connection)
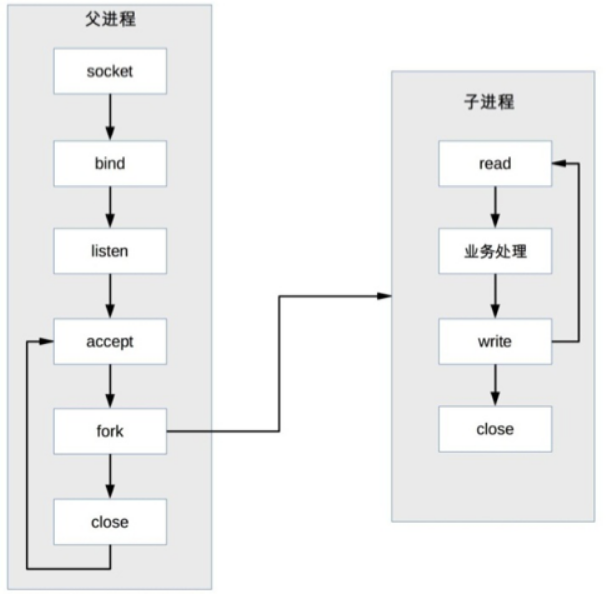
每次有新的連接就新建一個 process 去專門處理這個連接的請求,這是傳統的 UNIX network server 所採用的模型:
parent process 接受連接 (圖中 accept)
parent process “fork” child process (圖中 fork)
child process 處理連接的讀寫請求(圖中 child process read、業務處理、write)。
child process 關閉連接 (圖中 child process 中的 close)
PPC 模式實現簡單,比較適合 server 的連接數沒那麼多的情況,例如 DB server
此模式有以下幾個問題:
fork 代價高:站在 OS 的角度,創建一個 process 的代價是很高的,需要分配很多 kernel 資源,需要將 memory image 從 parent process 複製到 child process
即使現在的 OS 在複製 memory image 時用到了 Copy on Write 技術,總體來說創建 process 的代價還是很大的。
parent/child process 通信複雜:parent process “fork” child process 時,文件描述符可以通過 memory image 複製從 parent process 傳到 child process,但 “fork” 完成後,parent/child process 之間的通信就比較麻煩了,需要採用 IPC(Interprocess Communication) 之類的 process 通信方案。
例如, child process 需要在 close 之前告訴 parent process 自己處理了多少個請求以支撐 parent process 進行全域的統計,那麼 child process 和 parent process 必須採用 IPC 方案來傳遞信息
支持的並發連接數量有限:如果每個連接存活時間比較長,而且新的連接又源源不斷的進來,則 process 數量會越來越多,OS process 調度和切換的頻率也越來越高,系統的壓力也會越來越大。因此,一般情況下,PPC 方案能處理的並發連接數量最大也就幾百
prefork
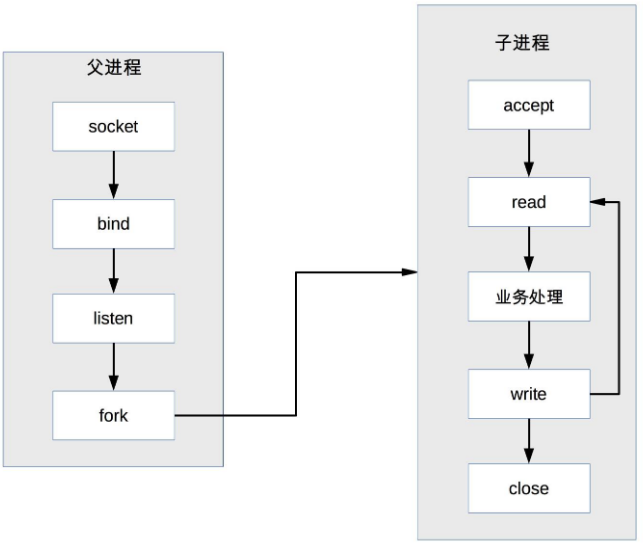
PPC 模式中,當連接進來時才 fork new process 來處理連接請求,由於 fork process 代價高,用戶訪問時可能感覺比較慢,prefork 模式的出現就是為了解決這個問題
prefork 就是提前創建 process (pre-fork)
系統在啟動的時候就預先創建好 process,然後才開始接受用戶的請求,當有新的連接進來的時候,就可以省去 fork process 的操作,讓用戶訪問更快、體驗更好
prefork 的實現關鍵就是 multiple child process 都 accept 同一個 socket,當有新的連接進入時, OS 保證只有一個 process 能最後 accept 成功
prefork 模式和 PPC 一樣,還是存在 parent/child process 通信複雜、支持的並發連接數量有限的問題,因此目前實際應用也不多
TPC (Thread Per Connection)
每次有新的連接就新建一個 thread 去專門處理這個連接的請求
與 process 相比,thread 更輕量級,創建 thread 的消耗比 process 要少得多
multiple thread 是共享 process memory 空間的,thread 通信相比 process 通信更簡單
TPC 實際上是解決或者弱化了 PPC fork 代價高的問題和 parent/child process 通信複雜的問題
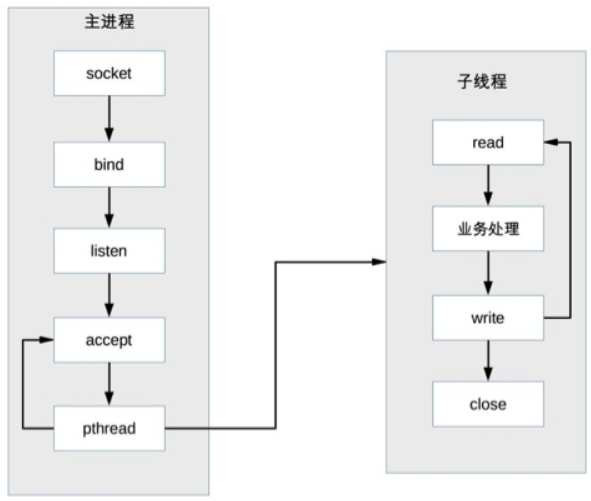
- TPC 基本流程:
- parent process 接受連接 (圖中 accept)
- parent process 創建 child thread (圖中 pthread)
- child thread 處理連接的讀寫請求 (圖中 child thread read、業務處理、write)
- child thread 關閉連接(圖中子 thread 中的 close)。
和 PPC 相比,主 process 不用”close”連接了
TPC 帶來的新問題:
- 創建 thread 雖然比創建 process 代價低,但並不是沒有代價,高並發時(例如每秒上萬連接)還是有效能問題。
- 無須 process 間通信,但是 thread 間的互斥和共享又引入了複雜度,可能一不小心就導致了 dead lock 問題
- multiple thread 會出現互相影響的情況,某個 thread 出現異常時,可能導致整個 process 退出 (例如:memory 越界)
在並發幾百連接的場景下,反而更多地是採用 PPC 的方案,因為 PPC 方案不會有死鎖的風險,也不會多 process 互相影響,穩定性更高
prethread
- 會預先創建 thread,然後才開始接受用戶的請求,當有新的連接進來的時候,就可以省去創建 thread 的操作,讓用戶感覺更快、體驗更好
- parent process accept,然後將連接交給某個 thread 處理。
- child thread 都嘗試去 accept,最終只有一個 thread accept 成功
討論整理精華
TPC 異常時整個 server 就掛了,而 PPC 不會,所以 PPC 適合 DB,middleware 這類的應用
PPC 和 TPC 這2種模式,無論 process 還是 thread 都受 CPU 的限制, process 和 thread 的切換都是有代價的,所以合適小型的系統,所以很多傳統行業選擇的是這 2 種
不同並發模式的選擇,還要考察三個指標,分別是響應時間(Response Time),並發數(Concurrency),吞吐量(TPS)
吞吐量 = 並發數/平均響應時間。不同類型的系統,對這三個指標的要求不一樣:
- 三高系統,比如秒殺、即時通信,不能使用
- 三低系統,比如ToB系統,運營類、管理類系統,一般可以使用
- 高吞吐系統,如果是 memory 計算為主的,一般可以使用;如果是 network I/O 為主的,一般不能使用
高並發需要根據兩個條件劃分:連接數量,請求數量:
- 海量連接(成千上萬)海量請求:例如:搶購,雙十一等
- 常量連接(幾十上百)海量請求:例如:middleware
- 海量連接常量請求:例如:入口網站
- 常量連接常量請求:例如:內部運營系統,管理系統
一個連接就是 TCP 連接,一個連接每秒可以發一個請求,也可以發幾千個請求
PPC 和 TPC 能夠支持的最大連接數差不多,都是幾百個,所以我覺得他們適用的場景也是差不多的
從連接數和請求數來劃分,這兩種方式明顯不支持高連接數的場景,所以只有以下兩種場景適用:
- 常量連接海量請求,例如:資料庫,redis,kafka 等等
- 常量連接常量請求,例如:企業內部網址
BIO(blocking I/O):一個 thread 處理一個請求。缺點:並發量高時,thread 數較多,浪費資源Tomcat7 或以下,在 Linux 系統中預設使用這種方式。可以適用於小到中規模的客戶端並發數場景,無法勝任大規模並發業務。如果程式控制不善,可能造成系統資源耗盡。
NIO(non-blocking I/O):利用多路復用 I/O 技術,可以通過少量的 thread 處理大量的請求Tomcat8 在 Linux 系統中預設使用這種方式;Tomcat7 必須修改 Connector 配置來啟動
NIO 最適用於”高並發”的業務場景,所謂高並發一般是指 1ms 內至少同時有成百上千個連接請求準備就緒,其他情況下 NIO 技術發揮不出它明顯的優勢
BIO/NIO/AIO 說明:
- BIO:PPC 和 TPC 屬於這種
- NIO:多路復用 I/O,Reactor 就是基於這種技術
- AIO:Asynchronous I/O,Proactor 就是基於這種技術
nginx 反向代理可以達到 3 萬以上併發量,具體需要根據業務和場景測試
若要考慮並發連接數來決定是否部署 cluster;FD 不是關鍵,關鍵是 process 或者 thread 數量太多,所佔資源和上下文切換很耗費效能
單一 server 高效能模式:Reactor 與 Proactor
單一 server 高效能的 PPC 和 TPC 模式,它們的優點是實現簡單,缺點是都無法支撐高並發的場景
可以應對高並發場景的單一 server 高效能架構模式:
Reactor和Proactor
解決方法
PPC 模式最主要的問題就是每個連接都要創建 process => 資源復用
不再單獨為每個連接創建 process,而是創建一個 process pool,將連接分配給 process,一個 process 可以處理多個連接的業務
引入 resource pool 的處理方式後,會引出一個新的問題: process 如何才能高效地處理多個連接的業務
只有當連接上有資料的時候 process 才去處理,這就是 I/O 多路復用技術的來源
I/O 多路復用技術有兩個關鍵實現點:
- 當多條連接共用一個 blocking 對象後, process 只需要在一個 blocking 對象上等待,而無須再輪詢所有連接,常見的實現方式有 select、epoll、kqueue 等
- 當某條連接有新的資料可以處理時, OS 會通知 process, process 從阻塞狀態返回,開始進行業務處理
Reactor
I/O 多路復用結合 thread pool,完美地解決了 PPC 和 TPC 的問題
Reactor 是 “事件反應” 的意思,可以通俗地理解為”來了一個事件我就有相應的反應”,這裡的”我”就是 Reactor,具體的反應就是我們寫的代碼,Reactor 會根據事件類型來調用相應的代碼進行處理
I/O 多路復用統一監聽事件,收到事件後分配(Dispatch)給某個 process
Reactor 模式的核心組成部分包括 Reactor 和處理資源池(process/thread pool),其中 Reactor 負責監聽和分配事件,處理資源池負責處理事件
Reactor 模式的具體實現方案靈活多變,主要體現在:
- Reactor 的數量可以變化:可以是一個 Reactor,也可以是多個 Reactor
- resource pool 的數量可以變化:以 process 為例,可以是單個 process,也可以是多個 process(thread 類似)
最終 Reactor 模式有這三種典型的實現方案:
- single Reactor single process/thread
- single Reactor multiple thread
- multiple Reactor multiple process/thread
single Reactor single process/thread
- select、accept、read、send 是標準的網路程式設計 API,dispatch 和”業務處理”是需要完成的操作
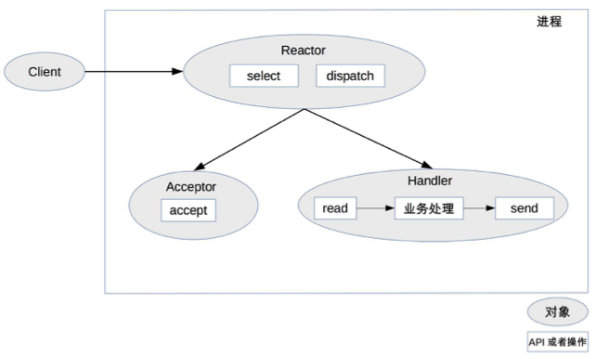
作法說明:
- Reactor 對象通過 select 監控連接事件,收到事件後通過 dispatch 進行分發。
- 如果是連接建立的事件,則由 Acceptor 處理,Acceptor 通過 accept 接受連接,並創建一個 Handler 來處理連接後續的各種事件
- 如果不是連接建立事件,則 Reactor 會調用連接對應的 Handler (上一個步驟中創建的 Handler)來進行回應
- Handler 會完成 read -> 業務處理 -> send 的完整業務流程。
優點:很簡單,沒有 process 間通信,沒有 process 競爭,全部都在同一個 process 內完成
缺點:
- 只有一個 process,無法發揮多核 CPU 的效能;只能採取部署多個系統來利用多核 CPU
- Handler 在處理某個連接上的業務時,整個 process 無法處理其他連接的事件,很容易導致效能瓶頸
實踐中應用場景不多,只適用於業務處理非常快速的場景 (例如:Redis)
C 語言編寫系統的一般使用
single Reactor single process,因為沒有必要在 process 中再創建 thread ;而 Java 語言編寫的一般使用single Reactor single thread,因為 Java 虛擬機是一個 process ,虛擬機中有很多 thread ,業務 thread 只是其中的一個 thread 而已
single Reactor multiple thread
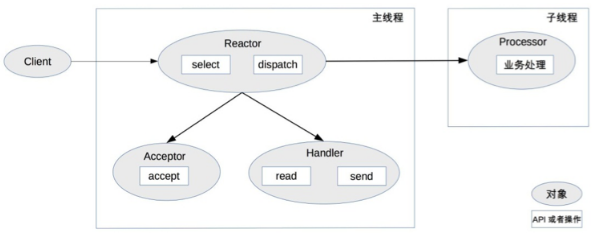
作法說明:
- 主 thread 中,Reactor 對象通過 select 監控連接事件,收到事件後通過 dispatch 進行分發。
- 如果是連接建立的事件,則由 Acceptor 處理,Acceptor 通過 accept 接受連接,並創建一個 Handler 來處理連接後續的各種事件。
- 如果不是連接建立事件,則 Reactor 會調用連接對應的 Handler(第 2 步中創建的 Handler)來進行響應。
- Handler 只負責響應事件,不進行業務處理;Handler 通過 read 讀取到資料後,會發給 Processor 進行業務處理。
- Processor 會在獨立的子 thread 中完成真正的業務處理,然後將響應結果發給主 process 的 Handler 處理;Handler 收到響應後通過 send 將響應結果返回給 client。
優點:單 Reator 多 thread 方案能夠充分利用多核多 CPU 的處理能力
缺點:
- 多 thread 資料共享和訪問比較複雜
- Reactor 承擔所有事件的監聽和響應,只在主 thread 中運行,瞬間高並發時會成為效能瓶頸
multiple Reactor multiple process/thread
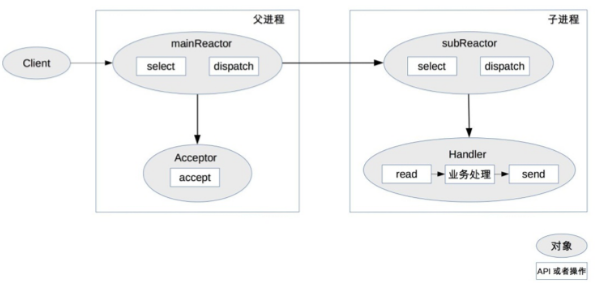
作法說明:
- parent process 中 mainReactor 對象通過 select 監控連接建立事件,收到事件後通過 Acceptor 接收,將新的連接分配給某個 child process
- child process 的 subReactor 將 mainReactor 分配的連接加入連接隊列進行監聽,並創建一個 Handler 用於處理連接的各種事件
- 當有新的事件發生時,subReactor 會調用連接對應的 Handler(即第 2 步中創建的 Handler)來進行響應
- Handler 完成 read→業務處理→send 的完整業務流程
multiple Reactor multiple process/thread 的方案看起來比單 Reactor 多 thread 要複雜,但實際實現時反而更加簡單:
- parent process 和 child process 的職責非常明確,parent process 只負責接收新連接,child process 負責完成後續的業務處理
- parent process 和 child process 的交互很簡單,parent process 只需要把新連接傳給 child process,child process 無須返回資料
- child process 之間是互相獨立的,無須同步共享之類的處理
Nginx 採用的是
multiple Reactor multiple process,採用multiple Reactor multiple thread的實現有 Memcache 和 Netty
Proactor
如果把 I/O 操作改為 asynchronous 就能夠進一步提升效能,這就是 asynchronous 網路模型 Proactor
Reactor 可以理解為”來了事件我通知你,你來處理”,而 Proactor 可以理解為”來了事件我來處理,處理完了我通知你”
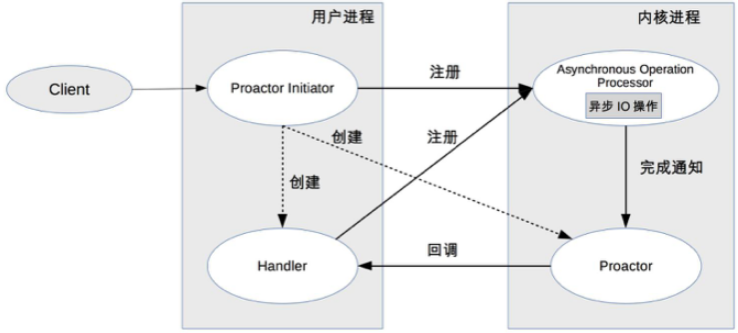
作法說明:
- Proactor Initiator 負責創建 Proactor 和 Handler,並將 Proactor 和 Handler 都通過 Asynchronous Operation Processor 註冊到 kernel
- Asynchronous Operation Processor 負責處理註冊請求,並完成 I/O 操作
- Asynchronous Operation Processor 完成 I/O 操作後通知 Proactor
- Proactor 根據不同的事件類型回調不同的 Handler 進行業務處理
- Handler 完成業務處理,Handler 也可以註冊新的 Handler 到 kernel process
理論上 Proactor 比 Reactor 效率要高一些,asynchronous I/O 能夠充分利用 DMA 特性,讓 I/O 操作與計算重疊
但要實現真正的 asynchronous I/O,OS 需要做大量的工作
目前 Windows 下通過 IOCP 實現了真正的 asynchronous I/O,而在 Linux 系統下的 AIO 並不完善,因此在 Linux 下實現高並發網路編程時都是以 Reactor 模式為主
討論整理精華
message queue 系統屬於 middleware,連接數相對固定,長連接為主,所以把 accept 分離出來的意義是不大的
message queue 要保證資料持久性,所以入庫操作應該是耗時最大的操作;綜合起來
single Reactor multiple thread的方式比較合適IO操作分兩個階段
- 等待資料準備好(讀到 kernel cache)
- 將資料從 kernel 讀到 user space(process 空間)
承上,一般來說 1 花費的時間遠遠大於 2
- 1 上阻塞 2 上也阻塞的是 synchronous blocking I/O
- 1 上非阻塞 2 阻塞的是 synchronous non-blocking I/O =>
Reactor - 1 上非阻塞 2 上非阻塞是 asynchronous non-blocking I/O =>
Proactor
以生活中的範例來描述 Reactor 與 Proactor:
- 假如我們去飯店點餐,飯店人很多,如果我們付了錢後站在收銀台等著飯端上來我們才離開,這就成了 synchronous blocking 了
- 如果我們付了錢後給你一個號碼後就可以離開,飯好了老闆會叫號,你過來取 => Reactor
- 如果我們付了錢後給我一個號碼後就可以坐到坐位上該幹啥幹啥,飯好了老闆會把飯端上來送給你 => Proactor