Overview
What is Pod ?
Pod 是在 k8s 最基本的組成單位(也是最小的可佈署單位),實際在 k8s 上運行的很多 resource object 都是以 pod 型式存在,因此了解 pod 運作的機制會讓我們對 k8s 有更深入的了解。
Pod 雖然是最基本的組成單位,但其實在設計上隱藏的相當多的細節,它封裝了許多不同的資源,也因此每個 pod 都有以下特性:
包含一到多個 container
同一個 pod 都 container 都共享相同的檔案系統 & volume … 等資源
container 共享相同的 network namespace(container 之間可以透過
localhost+port number互相通訊),且有獨一無二的 IP addresscontainer 之間也可以透過進程間通信,例如:SystemV or POSIX shared memory
container 共享 pod 中的 volume resource
pod 中的 container 總是被同時調度 & 有共同的運行環境
Pod 中共同的運行環境包含 Linux 的namespace,cgroup 和其他可能的隔絕環境,這部份跟 Docker container 是一樣的。不過在 pod 的環境中,每個 container 中可能還會因為 application 的管理策略會有不同的隔離方式
Pod 在 k8s 中有兩種主要的使用方式:
只運行一個 container: 這就類似在一個 container 外再包一個 wrapper
運行多個需要協同合作的 container: 這些 container 除了協同合作外,還共享相同的 network & storage 資源,其它與 application 相關的資源可能會另外由一個 sidecar container 來負責處理
讓多個 container 同時運行在同一個 pod 裏面,算是比較進階的應用,除非確定有多個容器之間緊密合作的需求才考慮使用這樣的模式
以下就是一個類似的應用範例:(一個 container 提供 web 服務,另一個則是負責 container management,從外面取得特定資料回來,並存到共享的 volume 中)
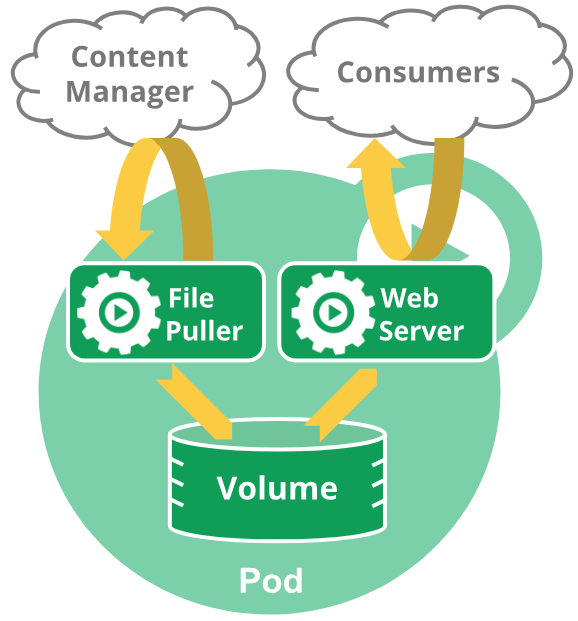
單獨使用 Pod 需注意的事項
在 k8s 中直接使用獨立的 pod 是沒問題的,但並不建議這麼做,理由大概有以下幾個:
獨立的 pod 若是發生問題時(例如: node failure),k8s 不會協助恢復其正常的狀態
若 pod 所在的 worker node 因為資源不足或是進入維護狀態時,pod 不會被自動移到其他正常的 node 並重新啟動
因此在 k8s 中,提供了一個更 high level 的抽象概念 controller 來處理上面的問題,而使用者在使用上也是應該透過這些 controller 來管理 pod。
Pod & Controller
Controller 可以協助使用者完成以下的工作:
建立 & 管理多個 pod
replication 管理
rolling upgrade/rollback
self healing
而在 k8s 中,屬於 controller 的 resource object 很多,詳細的清單可以參考此篇文章。
基本上,controller 使用的是稱為 Pod Template 的資訊來管理 pod 相關的資源,而 pod template 其實就是整個 pod 的 spec 資訊,其中可能還包含了其他 resource object 的資訊,例如:ReplicationController, Jobs, DaemonSet … 等等。
設計 Pod 的原因
可能會有人想要知道,為什麼在 k8s 中不直接使用 Container 為單位而是用 Pod 呢? 主要有兩個原因:
方便管理
Pod 是由 multiple cooperating processes 這個 pattern 所產生出來的一種模型,將多個原本各自獨立的元素變成了一個緊密結合的服務單位,這種設計方式簡化了佈署佈署 & 管理工作,並提供了一個 high level 的抽象概念來管理這些各自獨立的元素。
也因為設計 pod 作為 deployment unit,使得像是 Horizontal Scaling、Replication、Coordinated Replication、Resource Sharing、Dependency Management 這些功能在 k8s 中都可以自動被處理。
資源共享 & 通訊
如上面所提到的,透過 pod 的設計,讓同一個 pod 中的 container 可以很方便的共享 network & volume 等 application 使用時相當重要的資源。
終止 Pod
在 k8s 中,當一個 pod 被指定要終止時,k8s 會儘量確保 container 可以優雅地按照正常的流程停止,沒必要不會直接送 SIGKILL 去清除對應的 process,以下是一個 pod 終止時的流程範例:
使用者送出指令要刪除 pod,預設的寬限期(grace period)是 30 秒
超過寬限期後,pod 狀態在 API server 會被更新為 dead
接著同步執行以下工作:
3.1 此時若是在 CLI 中列出 pod,狀態會顯示 terminating
3.2 當 kubelet 發現 pod 被標記為 terminating 狀態時(目前尚在寬限期內),開始停止 pod 的流程:
3.2.1 如果在pod中 定義了 [preStop hook](https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/#hook-details),此時會被呼叫;如果 preStop hook 在超過寬限期過後依然在運行,第二步會再增加 2 秒的寬限期 3.2.2 向 Pod 中的 process 發送 **TERM** 信號;3.3 該 Pod 會從 service 的 endpoint list 中移除,replication controller 不會再進行管理;此時若是有終止比較慢的 pod,也不會繼續處理 load balancer 轉發過來的流量
過了寬限期後,將會向 Pod 中還在運作的 process 發送 SIGKILL 來清除 process。
kublete 會在 API server 中設定 grace period 為 0,表示完成 pod 的刪工作已經完成。此時 Pod 已經在 在 API server 中消失,CLI 也無法看見
預設的 grace period 為 30 秒,而使用 kubectl delete 指令可以直接透過 --grace-period=<seconds> 參數來改變這個預設值,若設定為 0 則是強制刪除 pod。
在 v1.5 之後,若要使用
--grace-period=0就必須要搭配--force參數一起使用
另外,強制刪除 pod 會讓 API server 直接清除該 pod 的所有資訊,不會等待 kubelet 將 resource 清理完成,在使用上會有潛在的風險;這個功能若是要應用在 StatefulSet 中的 pod,建議參考官網文章 deleting Pods from a StatefulSet 來處理。
Privileged Mode
k8s v1.1 之後開始可以透過 pod spec 中的 SecurityContext 中的 privileged 屬性,讓 pod 以 privileged mode 的狀態下運行,如果使用者要透過 pod 操作 network stack or 存取特定裝置時相當好用;讓 container 中的 process 幾乎可以跟 container 外部的 process 有著幾乎相同的存取權限。
Pod Lifecycle
Volume 跟 pod 有相同的生命週期(以 pod UID 為準)。當 Pod 因為某種原因被刪除或者被新創建但相同的 Pod 取代(UID 已經變更),它相關的資源(例如:volume)也會被銷毀和再創建一個新的。
Pod Phase
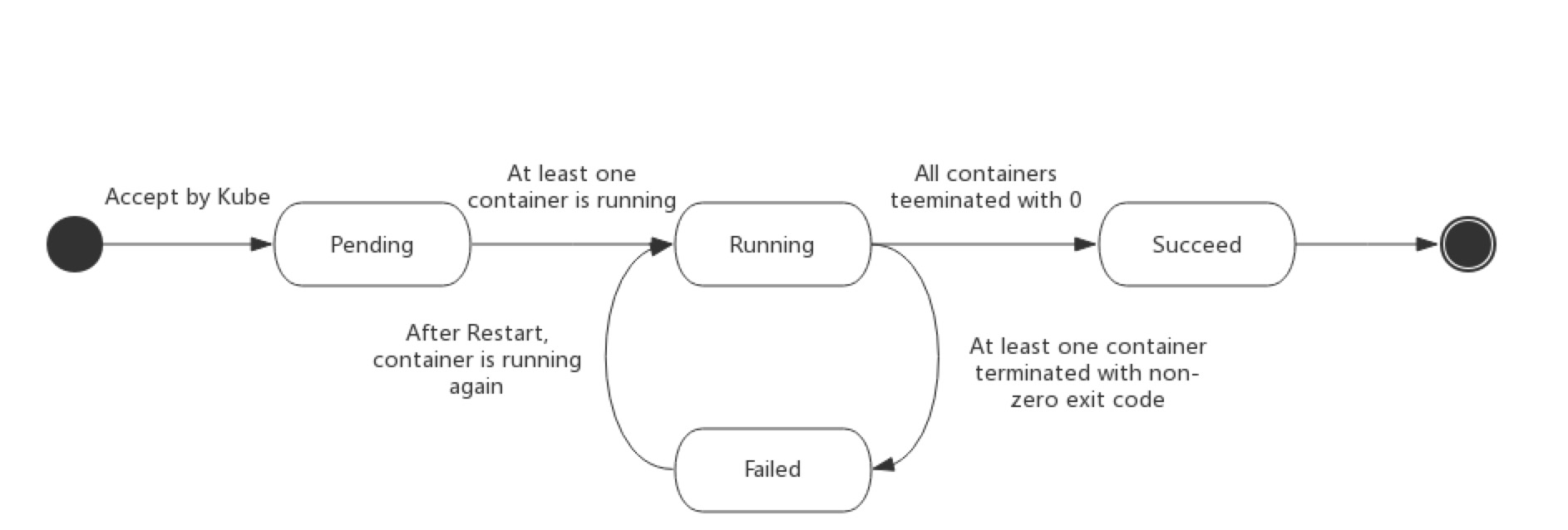
當使用 kubectl get pod 命令嘗試取得目前 namespace 中的 pod 列表,可以看到列表中有個欄位為 STATUS,顯示著目前 pod 的狀態,而這個狀態資訊其實是一個名稱為 PodStatus 的物件中的 phase 欄位所提供,根據 pod 狀況不同會有以下的值:
| Value | Description |
|---|---|
| Pending | Pod 已被 Kubernetes 系統接受,但有一個或者多個 container image 尚未被建立完成。這一段時間包含了調度 Pod 的時間和通過網絡下載 image 的時間,需要一段時間來處理 |
| Running | Pod 已經綁定到某個 node 上,相關的 container 都已經建立完成;且至少有個 container 正在運行 or 正處於 starting or restarting 的狀態下 |
| Succeeded | Pod 中的所有 container 都被成功終止,並且不會再重啟 |
| Failed | Pod 中的所有 container 都被終止,但至少有一個因為任務失敗而終止(表示退出時的狀態碼不為 0 or 被系統終止) |
| Unknown | 因為某些原因無法取得 Pod 的狀態,通常是因為與 Pod 所在 node 通訊失敗 |
Pod Condition
接著來看看 pod condition,以下透過 kubectl describe pod/kubernetes-dashboard-xyz -n kube-system 指令細部檢視 kubernetes-dashboard-xyz 這個 pod 的資訊可以看到類似一下內容:
1 | Name: kubernetes-dashboard-xyz |
仔細看看在 Conditions 的部份,系統提供了我們上面這些資訊,代表的意義是:
Initialized: 所有的 init container 是否都有成功啟動Ready: 是否已經可接受 service request 或是可加入到 load balancer 中ContainersReady: 在 pod 中的所有 container 是否都已經 readyPodScheduled: pod 是否已經被 schedule 到特定的 node
診斷 Container 有無正常運行 - Probe
What is Probe?
probe(探針)的設計目的在於定期診斷 container 是否持續正常運作中,由 kubelet 執行。而執行方式就是 kubelet 呼叫實作在 container 中的特定 handler 來取得狀態資訊,目前 handler 可分為以下三類:
ExecAction: 在 container 內執行特定命令。如果命令結束時 exit code 為 0 則視為診斷成功
TCPSocketAction: 對 pod 上的特定 port 進行 TCP check,若是 port 是 open 的狀態,則視為診斷成功
HTTPGetAction: 對指定的 pod IP+Port 執行 HTTP Get 請求。如果 HTTP response status code 大於等於200 且小於 400,則視為診斷成功
當每個 probe 完成後,會有三種結果,分別是 Success(通過診斷)、Failure(未通過診斷) & Unknown(診斷失敗 & 不採取任何行動)
Probe 種類
目前 kubelet 可以根據使用者的設定,來執行以下兩種的 probe 並根據結果做出反應:
livenessProbe: 診斷 pod 是否處於 running 狀態。若診斷沒有通過,kueblet 就會殺掉 pod 並根據 restart policy 進行後續動作。此外,如果 pod spec 中沒有提供 livenessProbe 的設定,則預設為診斷成功。
以下是一個 livenessProbe 的設定範例
1 | apiVersion: v1 |
readinessProbe: 診斷 pod 是否可以接受 service request。若診斷沒有通過,與這個 pod 相關的 service endpoint 資訊都會被 controller 移除。在 initial delay 之前 readiness 狀態會被預設為 failure。此外,如果 pod spec 中沒有提供 readinessProbe 的設定,則預設為診斷成功。
何時使用這些 Probe?
使用 probe 大概有幾個原則可以遵循:
如果 container 有設計成當遇到問題的時候會自己 crash,不會卡死,那就不用特別設定 livenessProbe,kubelet 會自動根據 restart policy 來進行後續處理
如果希望 pod 可以在 probe 診斷失敗的時候被 kill 並 restart,那就要把
restartPolicy設定為 Always or OnFailure如果希望 pod 進入正常服務狀態的時候才開始接收 service request 的話,那就設定
readinessProbe,只有當診斷成功時,k8s 才會把 service request 送給 pod若 container 啟動時需要處理大量資料 or 設定檔 or 進行 migration 的檢查,此時就需要設定
readinessProbe,當診斷成功後才開始接收 service request如果只是要在 pod 刪除時不接收任何 service request,其實不需要設定任何的 probe
Pod readiness gate
這是在 v1.11 後開始推出一個稱為 Pod ready++ 的功能(在 v1.11 中還是 alpha),目的是要透過開放讓額外的 feedback or signal 放到 Pod Status 中,來強化 Pod readiness 的診斷功能。
有了這個功能後,就可以在 pod spec 中定義要額外診斷的 status.conditions(預設值為 False),而 pod condition 的定義必須是以 key/value 的型式,以下是一個範例:
1 | Kind: Pod |
目前 kubectl patch 命令不支援變更 object status,所以要塞入額外的 pod condition 資訊必須使用 k8s client library 來完成。
因此有了 readinessGates 之後,只有在同時滿足以下兩個條件下,pod 才會被診斷為 ready:
pod 中所有的 container 狀態皆為 Ready
所有在 pod spec 中定義的 ReadinessGates 的狀態皆為 True
若要啟用這個功能,必須要在啟用 k8s 元件時,在 –feature-gates 參數中把 PodReadinessGates 設定為 True。
Restart Policy
關於 restart policy 有幾個重點:
有
Always(預設值),OnFailure,Never三種不同的 restart policyrestart policy 套用的範圍是 pod 中的所有 container,而不是某一個
restart policy 僅會透過使用同一個 node 上的 kubelet 來重起 container
失敗的 container 會由 kubelet 重新啟動,但每次的延遲時間都會加長(10秒,20秒,40秒…),延遲時間上限為 5 分鐘,並在 container 成功執行十分鐘後重置
一旦 pod 被綁定到特定的 node 後,就不會在綁定到另一個 node
Pod Lifetime
一般來說,除非有使用者 or controller 介入,不然 pod 不會消失;而目前有三種手段可以來控制 pod 的存活:
一次性的工作,使用 Job resource object 來處理
務必記得使用 Job 時,restartPolicy 必須設定為
OnFailureorNever若希望 pod 不要被意外終止,使用 ReplicationController, ReplicaSet 或是 Deployment 來確保 desired status 可以被維持
ReplicationController 只有在 restartPolicy 設定為
Always才會正常的運作若在每一台機器中都需要運行的 pod,使用 DaemonSet
總之,透過上面的 resource object 來控制 pod 的存活,不要單獨佈署 pod。
Pod Status + Restart Policy 的情境範例
這部份可以參考官網的 Pod - Example states 文件,有列出相當多的情境範例可參考,了解在不同的情境下,k8s 會做出的反應。
Init Container
What is Init Container ?
Init Container 是用來指定在 app container 開始運行之前(此時 pod network & volume 資源都已經初始化完成)啟動起來完成某些特定的工作之用,因此 Init Container 也可能包含一些 app container image 中所沒有的工具或是 script。
一個 Pod 中能夠包含多個 app container 同時運行,同時也可以有多個 init container 來處理在 app container 開始運行前需要完成的特殊工作,而在 init container 工作執行完成之前,pod 的狀態都會顯示為 Initializing。
init container 跟一般的 container 幾乎相同,除了以下幾點:
init container 總是會執行到結束為止
若定義多個 init container,會依序一個一個執行,且必須等到前一個 init container 執行成功後,才會輪到下一個
如果任何一個 init container 工作執行失敗,k8s 就會重新啟動 pod 並再度啟動所有的 init container 繼續執行工作,除非 restartPolicy 設定為
Never
Init Container 可以做哪些事情 ?
由於 init container 跟 app container 使用的是不同的 container image,因此在使用上會有一些優點,例如:
可以打包一些特殊的工具並執行,而這些工具 & 工作內容可能因為安全性的關係而沒有放進 app container 中
也可以包含一些常用的工具(例如:sed, awk, python, dig … 等等),而為了這些簡單工具再包一個 container image 很沒必要
將 application image 的 builder & deployer 分開,bulder 可以根據 init & app container 的需要建立不同的 image,而不是將所有東西都打包在同一個 image 中,因此 deployer 的工作就會相對單純點
由於同一個 pod 的 container 中,mount namespace 還是分開的,因此 init container 可以設計用來存取 app container 不能存取的 secret
可提供一些簡單的方式來阻止 or 延緩 app container 啟動,直到某些條件達成為止
以下是一些使用情境的介紹:
1 | # 執行某個 shell command 直到 service 啟動為止 |
範例說明
接著是一個簡單的使用範例參考:
1 | apiVersion: v1 |
看到上述的範例可能有點模糊,不曉得要等待什麼 service,因此要搭配下面的 service 定義來看:
1 | kind: Service |
如此一來就很清楚了,只要當 service 設定完成,nslookup 可以找到對應的 IP 後,在 init container 中的回圈就會跳出 & 結束工作
更多的使用範例可以參考以下網址:
使用上需注意的地方
若要修改 init container 的設定,只能針對 image 的欄位進行修改,而且修改後會等同於 restart pod
因為 init container 可能會 restart, retired 或是 re-execute,因此在 init container 中的執行程式要確保達成 idempotent 的特性(重複執行會得到相同結果)
不支援 readiness probe
可透過 activeDeadlineSeconds & livenessProbe 兩個方式來確保 init container 不會永遠的掛掉
init container 與 app container 不能設定相同的 name
Resource 管理
若是使用者有設定 resource quota,init container 同樣也會受到影響,而資源限制的規則大概如下:
init container 最上層的 resource request 就是有效的 init request/limit
若 pod 的層級有設定有效的 request/limit,則優先權大於 app container request/limit 的總和 & 有效的 init request/limit
scheduling 是根據有效的 request/limit 進行的,這表示 init container 可以用到所有 request/limit 所定義的資源 (因為此時 pod 還用不到任何資源)
pod 的 QoS tier 跟 init/app container 的 QoS tier 是相同的
Pod Preset
What is PodPreset ?
PodPreset 是個很有意思的 resource object,主要是用來在 pod 建立的時候,放入一些使用者自行額外定義的資訊,這些資訊可以是 secret, volume, volume mount 或是 環境變數 …. 等等。
在什麼情況下需要使用 PodPreset 呢? 當你有一批透過相同 template 產生出來的 pod,但卻希望他們可以根據特定的資訊(例如:環境變數)來產生不一樣的行為時,就可以透過 PodPreset 搭配 label selector 將特定的資訊放到帶有特殊 key/value 的 label 的 pod 中。
PodPreset 是如何運作的?
首先要知道,PodPreset 是 k8s admission controller 所提供的功能,因此要使用必須要在 kube-apiserver 啟動時把這個功能選項(--enable-admission-plugins=PodPreset)加入才會有,當此功能啟動後,k8s 就會在收到 pod creation request,運行以下流程:
取得目前 namespace 中已經存在的 PodPreset
檢查是否有符合任何 PodPreset 中 label selector 的定義
若有符合的 PodPreset,就將 PodPreset 中定義的資訊合併到 pod 中
若是合併 PodPreset 資訊時發生錯誤,會拋出一個 merge error 並記錄,但並不影響 pod 的建立過程(只是沒包含 PodPreset 定義的資訊)
若成功,PodPreset 就會在 pod spec 中增加一筆 annotation 資訊,內容如下:
podpreset.admission.kubernetes.io/podpreset-<pod-preset name>: “<resource version>”
由於 PodPreset 這個機制是搭配 label selector 完成的,因此 PodPreset 中定義的資訊可以同時套用到 0 個或多個 pod;反之多個 pod 也可以因為含有多個 label 而被多個 PodPreset 套用,因此兩者是多對多的關係。
最後還需要注意的是,若 PodPreset 中定義的資訊類型屬於 Env, EnvFrom 或是 VolumeMounts,則會被修改的是 container spec;但若是 Volume,則是 pod spec 被修改。
PodPreset 對 init container 無效
如何啟用 PodPreset ?
要在 k8s cluster 啟動 PodPreset 的功能,需要在 kube-apiserver 啟動的參數中,額外加入兩組設定:()
--runtime-config=xxx=true,yyy=true,zzz=true,settings.k8s.io/v1alpha1=true--enable-admission-plugins=xxx,yyy,zzz,PodPreset
接著就可以在需要使用此功能的 namespace 定義 PodPreset resource object 來使用了!