深入探討 Lambda
Serverless 的重點
不需要佈署 or 管理 server
會根據需求自動的 scale out/in
不需要為 idle 資源支付費用
天生就具備的 HA & fault tolerance 等特性
Serverless != Lambda
首先需要了解的是,serverless 僅是個概念,並不等同於 Lambda;serverless 是對於使用者來說,可以免去管理 server 的負擔,但對於 AWS 來說,其實 server 本身還是存在的,只是底層這些 resource 都是由 AWS 幫你管理好了,使用者只要專注在開發 & 佈署應用即可。
目前 AWS 提供的 serverless service 其實很多,下圖是目前比較常見的幾個:
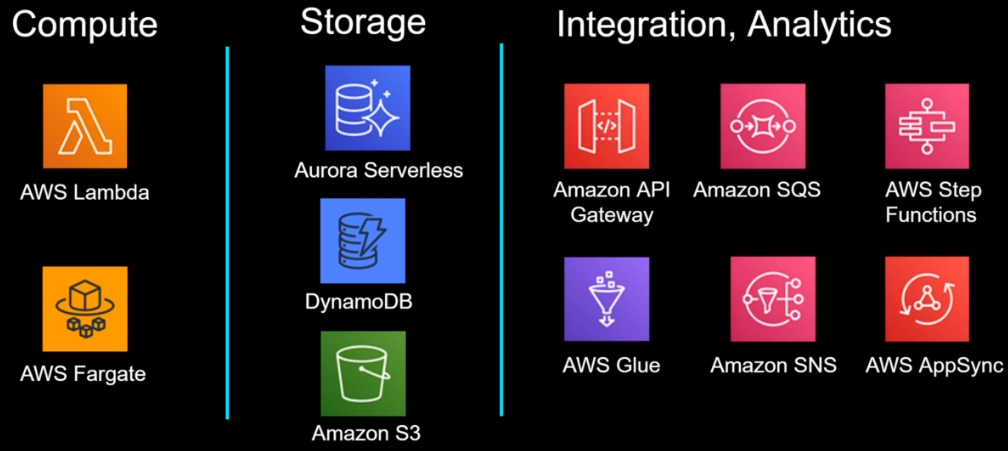
但要如何判斷 AWS service 是否為 serverless? 只要評估一下上一個 section 提到的四個原則,如果都滿足,表示這個服務屬於 serverless(例如:Lambda、SNS、SQS),只要有一項不滿足,則該服務不屬於 serverless(例如:EC2、Kinesis)
關於 Lambda 運行時可選用的資源量
文件中提到可設定 Lambda Function 執行時使用的記憶體範圍在 128MB ~ 10,240MB(10GB) 之間(一開始只有 3GB,後來加大了,詳情可參考 AWS 官網新聞)
比較需要注意的是,Lambda function 執行時 的vCPU core 的數量是根據 memory 的設定大小來決定,如果在設定最大 10GB memory 的情況下,可以取得最大 6 vCPU core;簡單來說,就是記憶體設定越大,執行速度會越快,當然費用也會越高
實際上就是只有
memory&timeout設定可以調整而已
可觸發 Lambda 的情境
Lambda 可以被應用的場景其實相當的多,以下圖為例:
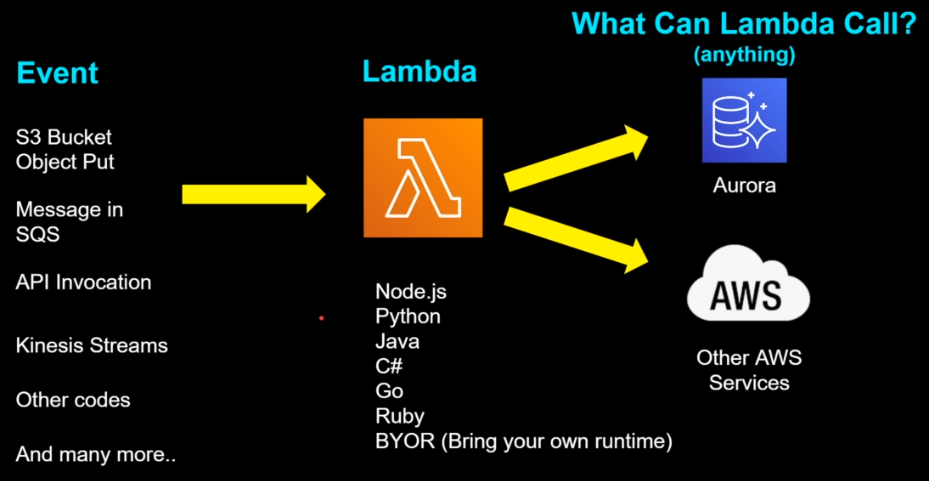
最左邊是一系列可以用來作為 event source 來觸發 Lambda Function 執行一段特定的程式
中間則是開發 Lambda Function 時可選用的 runtime;其實除了常見幾個之外,甚至可以使用自己的 runtime(例如:COBOL)
右邊則是 Lambda Function 可以對外互動的對象,除了資料庫之外,當然對眾多的 AWS service 也沒問題(這部份就需要有對應的 IAM permission 才行)
結論
- Lambda 並非適用於解決所有問題,但多了解一個工具,有助於在處理各式不同問題時,更有機會選擇到正確的工具來完成
Lambda 使用費用高嗎?
基本上不要濫用,使用合適的資源配置,Lambda 應該是可以省下很多費用的,畢竟使用 Lambda 的一大優勢就是不需要為閒置的資源付費。
關於費用的部份,基本重點如下:
在 free tier 涵蓋的範圍中,AWS 每個月都會提供免費的一百萬次呼叫 & 400,000 GB-seconds 的運算時間,超過才會開始計算費用
計費的時間單位為 1ms(原本為 100ms,後來在 reInvent 2020 時降低到 1ms)
不需要任何的 commitment
再也不需要為閒置資源付費
若是想進一步精算 Lambda 使用的費用,可以使用 AWS Lambda Pricing Calculator 這個工具來完成。
第一次建立 Lambda 就上手
Hello World
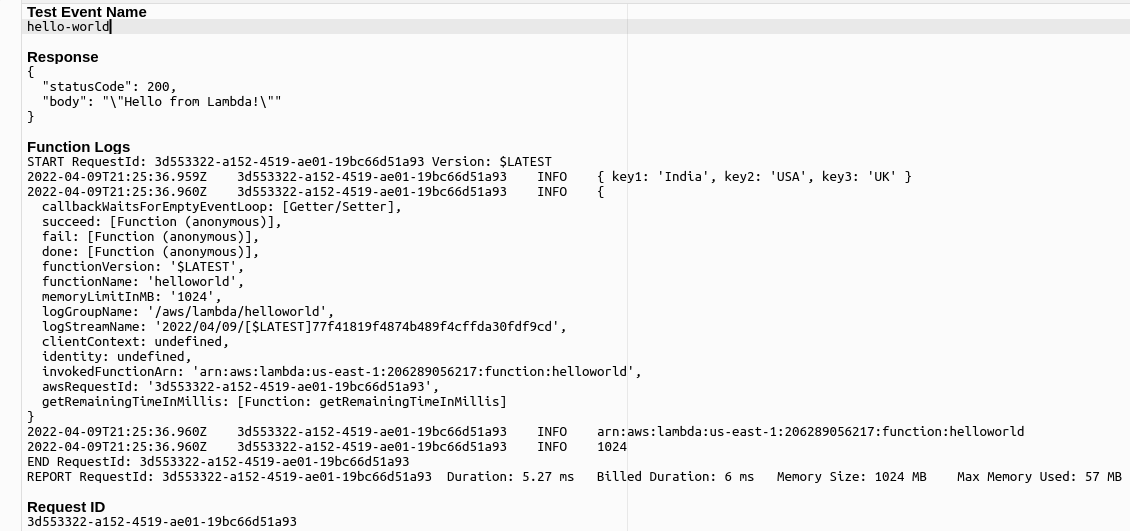
第一次建立 Lambda 當然要先用 Hello World 來開場,以下是建立 Lambda Function 時選擇 Author from scratch 所產生的範例,結果就會是一個 Hello World 的範例,大概會是以下的樣子:
1 | exports.handler = async (event, context) => { |
整個測試的過程有幾個重點:
handler這邊就是程式的起點event會包含 event source 的內容,若是這個 event 來自於 AWS 某個服務,就會有相關的詳細內容出現在這,以 JSON 形式表示context則是此 Lambda Function 呼叫的相關內容(在 nodejs 中這個參數預設不會出現,是我加上去的),包含像是 Lambda Function ARN、記憶體最大用量上限 … 等資訊若是調整了執行的記憶體用量,不用重新 Deploy 就會生效
以下是執行測試結果:
S3 Get Object
第二個建立的範例就改用 Use a blueprint 的方式,選擇 s3-get-object 作為範本來建立,整個測試的細節不描述了,以下僅說明一下整個過程的重點:
由於 Lambda Function 會需要存取 S3 bucket 中的資料,因此就會需要建立一個相對應的 IAM Role,並給予正確的權限後,assign 給 Lamnda 作為 Execution role (不過因為使用 blueprint 的關係,相關權限都會預先設定好)
為了在開發階段可以方便進行測試,AWS 在 Test 中提供了很多 event template 可選,當然也包含範例中的
s3-put,因此在開發階段就可以知道當檔案存放進 S3 後,所產生出來的 event payload 會長什麼模樣,就很方便開發者進行相關程式的開發 & 測試若要檢查 Lambda Function 實際的執行輸出,可以到
Monitor -> View Logs in CloudWatch檢視,預設都會全部輸出到 CloudWatch Log 中這代表若是大量輸出 log,可能就會需要考慮費用的問題,因為 CloudWatch Log 費用其實不低
若是新增另外一個 trigger,以 DynamoDB 為例,就會出現
Please ensure the role can perform the GetRecords, GetShardIterator, DescribeStream, ListShards, and ListStreams Actions on your stream in IAM.的錯誤,原因就是原本的 Execution Role 並沒有足夠的 IAM 權限,因此就需要補上對應的權限才可以順利新增 trigger為了讓開發階段時不會被 trigger 所產生的 event 干擾,可以暫時 disable trigger
需要注意的是,並不是每個 trigger 都可以被 disable (DynamoDB、SQS 可以,但 S3 就不行)
有哪些方式可以建立 Lambda ?
建立 Lambda 的方式有以下幾種:
AWS Console
CloudFormation / SAM(Serverless Application Model) / CDK
AWS CLI
基本上一開始練習測試都是透過 AWS Console,但後續若是要考慮到大量開發 & 佈署的部份,一般都會引入 DevOps 相關的自動化工具來完成,而自動化的部份就會搭配上面的第 2 & 3 的選項來完成。