API 故障
multi-site HA 主要應對系統級的故障,例如,機器當機、機房故障、網路故障等問題,這些系統級的故障雖然影響很大,但發生機率較小
而 API 級別的故障發生機率就相對高了
API 級別故障的典型表現就是系統並沒有當機,網路也沒有中斷,但業務卻出現問題了(例如:業務響應緩慢、大量 request timeout、大量訪問出現異常)
這類問題的主要原因在於系統壓力太大、負載太高,導致無法快速處理業務請求,由此引發更多的後續問題(例如:DB Slow Query 將資料庫的服務器資源耗盡,導致讀寫超時)
導致 API 故障的原因:
- 內部原因:程式 bug 導致死循環,某個 API 導致 DB Slow Query,程式邏輯不完善導致耗盡 memory 等
- 外部原因:Hacker 攻擊、促銷或者搶購引入了超出平常幾倍甚至幾十倍的使用者,第三方系統大量請求,第三方系統響應緩慢等
解決方式
降級
系統將某些業務或者 API 的功能降低,可以是只提供部分功能,也可以是完全停掉所有功能
降級的核心思想就是棄車保帥,優先保證核心業務(例如:對於論壇來說,90% 的流量是看討論串,那我們就優先保證看討論串的功能)
常見的實現降級方式:
系統後門降級
系統預留了後門用於降級操作(通常以 API 的形式呈現)
實作成本低
缺點是如果服務器數量多,需要一台一台去操作,效率比較低,在故障處理爭分奪秒的場景下是比較浪費時間的
獨立降級系統
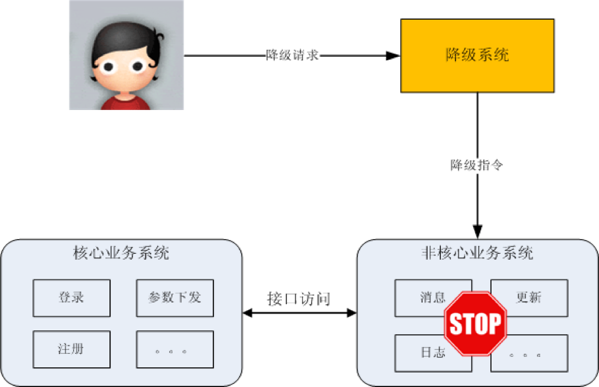
- 將降級操作獨立到一個單獨的系統中,可以實現複雜的權限管理、批次操作等功能
熔斷
降級的目的是應對系統自身的故障,而熔斷的目的是應對依賴的外部系統故障的情況
例如:A 服務的 X 功能依賴 B 服務的某個 API,當 B 服務的 API 響應很慢的時候,A 服務的 X 功能響應肯定也會被拖慢,進一步導致 A 服務的 thread 都被卡在 X 功能處理上,此時 A 服務的其他功能都會被卡住或者響應非常慢。這時就需要熔斷機制了,即:A 服務不再請求 B 服務的這個 API ,A 服務內部只要發現是請求 B 服務的這個 API 就立即返回錯誤,從而避免 A 服務整個被拖垮
熔斷機制實現的關鍵:
- 需要有一個統一的 API 調用層,由 API 調用層來進行採樣或者統計,如果 API 調用散落在程式碼各處就沒法進行統一處理了
- threshold 的設計:一般都是先根據分析確定 threshold,然後上線觀察效果,再進行調整優化
限流
降級是從系統功能優先級的角度考慮如何應對故障,而限流則是從使用者訪問壓力的角度來考慮如何應對故障
限流指只允許系統能夠承受的訪問量進來,超出系統訪問能力的請求將被丟棄
常見的限流方式可以分為兩類:
以”請求”為基礎限流
從外部訪問的請求角度考慮限流:限制總量 & 時間量
限制總量的方式是限制某個指標的累積上限,常見的是限制當前系統服務的用戶總量(例如:某個直播間限制總用戶數上限為 100 萬)
限制時間量指限制一段時間內某個指標的上限(例如:1 分鐘內只允許 10000 個用戶訪問)
實現簡單,但主要問題是比較難以找到合適的 threshold
即使找到了合適的 threshold ,基於請求限流還面臨硬體相關的問題(例如:64 core 的機器比 32 core 的機器,業務處理性能並不是 2 倍的關係,可能是 1.5 倍)
為了找到合理的 threshold ,通常情況下可以採用性能壓測來確定 threshold ,但性能壓測也存在覆蓋場景有限的問題
逐步優化算是比較準確的方式,但需要持續觀察 & 調整
以”資源”基礎限流
基於請求限流是從系統外部考慮的,而基於資源限流是從系統內部考慮的
找到系統內部影響性能的關鍵資源,對其使用上限進行限制(例如:連接數、file handler、 thread count、請求隊列)
基於資源限流相比基於請求限流能夠更加有效地反映當前系統的壓力
實踐中設計也面臨兩個主要的難點:
- 如何確定關鍵資源
- 如何確定關鍵資源的 threshold
同樣也需要逐步優化的過程
排隊
排隊實際上是限流的一個變種,限流是直接拒絕用戶,排隊是讓用戶等待一段時間
排隊雖然沒有直接拒絕用戶,但用戶等了很長時間後進入系統,體驗並不一定比限流好
排隊需要臨時緩存大量的業務請求,單個系統內部無法緩存這麼多數據,需要用獨立的系統(例如:Kafka)去實現
討論整理精華
設計一個整點限量秒殺系統,包括登錄、搶購、支付(依賴支付寶)等功能,你會如何設計 API 級別的故障應對手段呢?
Solution 1
對於用戶服務,在搶購期間可以準備降級策略 => 壓力過大時保證用戶登入的可用,註冊和修改信息可以做降級處理
搶購下單涉及到訂單,庫存,和商品查詢。可通過請求排隊來限流,超出庫存的請求直接返回
為了應對庫存和商品服務可能發生的故障,可以提前對商品數據和庫存數據做緩存,如果對端服務故障,本地也可以提供服務
支付依賴第三方系統,合理設置熔斷策略,如支付平均時長超過限制可提示用戶稍晚做支付
Solution 2
- 訪問的流量在每個環節可能逐步遞減(登入例外)
- 引導部分用戶提前登陸
- 秒殺價系統獨立部署(感覺和其他系統部署在一起才需要降級)
- 搶購使用排隊方式,隊列大小可以預估較大長度,隊列外的拒絕
- 如果要求以支付成功為準,通過隊列和熔斷;如果以下單成功為準,使用熔斷。提醒稍後再付
其他思考
假如降級時優先保證登錄,但是用戶登錄進來後發現搶購不了,其實體驗也不好
已經搶購了的用戶可能無法支付,這樣體驗更不好,甚至會引起投訴,因此搶購類降級是優先降登錄會好些
保留搶購和支付,保證進來的用戶能夠完成業務流程
支付失敗真沒什麼好辦法了,因為這是核心鏈路的核心功能
一般不建議對支付做降級,用戶體驗很不好,還不如登錄和搶購階段限流
這是有心理學理論支撐的,用戶沒搶到前,如果搶不到他會認為自己運氣不好,但如果用戶搶到了卻無法支付,他會覺得自己損失了,會觸發”損失厭惡”心理