業務高可用的保障:Multi-Site HA(異地多活)
由於備份系統平時不對外提供服務,可能會存在很多隱藏的問題沒有發現
如果業務期望達到即使在災難性故障發生的情況下,業務也不受影響,或是在短時間內很快恢復,那麼就需要設計 Multi-Site HA 架構
應用場景
Multi-Site HA 架構的關鍵點就是
Multi-Site(地理位置上不同的地方)、High Availability(HA)(不同地理位置上的系統都能夠提供業務服務)判斷一個系統是否符合 Multi-Site HA ,需要滿足兩個標準:
- 正常情況下,用戶無論訪問哪一個地點的業務系統,都能夠得到正確的業務服務
- 某個地方業務異常的時候,用戶訪問其他地方正常的業務系統,能夠得到正確的業務服務
實現 Multi-Site HA 架構不是沒有代價的,相反其代價很高:
- 系統複雜度會發生質的變化
- 成本會上升
不是每個業務都要上 Multi-Site HA
- 如果無法承受 Multi-Site HA 帶來的複雜度和成本,是可以不做 Multi-Site HA 的,只需要做 Multi-Site backup 即可
- 某些業務系統即使中斷,對用戶的影響並不會很大(例如:新聞網站、企業內部的 IT 系統)
如果業務規模很大,能夠做 Multi-Site HA 的情況下還是儘量完成
- 能夠在異常的場景下給用戶提供更好的體驗
- Multi-Site HA 能夠減少異常發生時所帶來的收入損失
架構模式
根據地理位置上的距離來劃分,可以分成以下三種架構:
同城異區
同城異區指的是將業務部署在同一個城市不同區的多個機房
同城的兩個機房,距離上一般大約就是幾十公里,通過搭建高速的網路,同城異區的兩個機房能夠實現和同一個機房內幾乎一樣的網路傳輸速度(邏輯上可視為同一個機房,類似 AWS AZ)
對於極端場景(例如:大地震)無能為力;但對於機房火災、機房停電、機房空調故障這類問題可以很容易解決(兩種狀況都會讓機房出問題造成業務停擺)
結合複雜度、成本、故障發生機率來綜合考慮,同城異區是應對機房級別故障的最優架構
跨城異地
跨城異地指的是業務部署在不同城市的多個機房,而且距離最好要遠一些
距離上比較遠,才能有效應對極端災難事件
距離增加帶來的最主要問題是兩個機房的網路傳輸速度會降低
除了距離上的限制,中間傳輸各種不可控的因素也非常多(例如:挖掘機把光纖挖斷、中美海底電纜被拖船扯斷、骨幹網故障 … etc)
跨城異區距離太遠,搭建或者使用多通道的成本會高不少
如果要做到真正意義上的多活,業務系統需要考慮部署在不同地點的兩個機房,在資料短時間不一致的情況下,還能夠正常提供業務
矛盾點:資料不一致業務肯定不會正常,但跨城異地肯定會導致資料不一致
支付寶等金融相關的系統,對餘額這類資料,一般不會做跨城異地的多活架構,而只能採用同城異區這種架構
對資料一致性要求不那麼高,或者資料不怎麼改變,或者即使資料丟失影響也不大的業務,跨城級別的 Multi-Site HA 就能夠很好地應對極端災難的場景
跨國異地
跨國異地指的是業務部署在不同國家的多個機房
跨國 Multi-Site HA 的主要應用場景一般有這幾種情況:
- 為不同地區用戶提供服務
- 為 read-only 類型的業務做 HA
討論整理精華
備份系統平常沒有流量,如果直接上線可能觸發平常測試不到的故障
再即時的系統也會有資料延時,如果涉及到金融這種系統,仍然是不敢直接切換的。
系統運行過程中會有很多中間資料,緩存資料等。系統不經過預熱直接把流量倒過來,大流量會直接把系統拖垮
餘額資料同城異區對比跨城異地在資料一致性上同樣存在時間差,只是時間窗口更小而己,如果兩地都支持寫的話,存在被雙花攻擊的可能,風險還是很大 => 餘額和庫存一般不做雙寫
同城異區也是有延遲的,但是延遲小,故障切換時快,但總是有可能有用戶資料不一致,這種數量小就可以容忍,人工修復和事後補償的代價都可以接受,不存在所有用戶都沒任何問題的方案
Multi-Site HA 設計 4 大技巧
- 核心理念:採用多種手段,保證絕大部分用戶的核心業務 Multi-Site HA
技巧 1:保證核心業務的 Multi-Site HA
很多架構師在考慮”業務”時,會不自覺地陷入一個思維誤區:
我要保證所有業務都能 Multi-Site HA(但這是不可能的)修改核心業務規則的代價非常大,幾乎所有的業務都要重新設計,為了架構設計去改變業務規則是得不償失的
優先實現核心業務的 Multi-Site HA 架構(例如:業務中的”登錄”功能)
技巧 2:保證核心資料最終一致性
資料同步是Multi-Site HA 架構設計的核心;但大部分架構師在考慮資料同步方案時,會不知不覺地陷入完美主義誤區:
所有資料都即時同步業務上要求資料快速同步,物理上正好做不到資料快速同步,因此所有資料都即時同步,實際上是一個無法達到的目標
如何減少資料無法快速同步的影響?
- 儘量減少 Multi-Site HA 機房的距離,搭建高速網路
- 儘量減少資料同步,只同步核心業務相關的資料
- 保證最終一致性(Eventually Consistency),不保證即時一致性
最終一致性在具體實現時,還需要根據不同的資料特徵,進行差異化的處理,以滿足業務需要
技巧 3:採用多種手段同步資料
思維誤區:只使用存儲系統(例如:MySQL, Redis, Elasticsearch … etc)的同步功能
在某些比較極端的情況下,存儲系統本身的同步功能可能難以滿足業務需求
異地多機房這種部署,各種各樣的異常情況都可能出現,當我們只考慮存儲系統本身的同步功能時,就會發現無法做到真正的 Multi-Site HA
避免只使用存儲系統的同步功能,可以將多種手段配合存儲系統的同步來使用,甚至可以不採用存儲系統的同步方案,改用自己的同步方案:
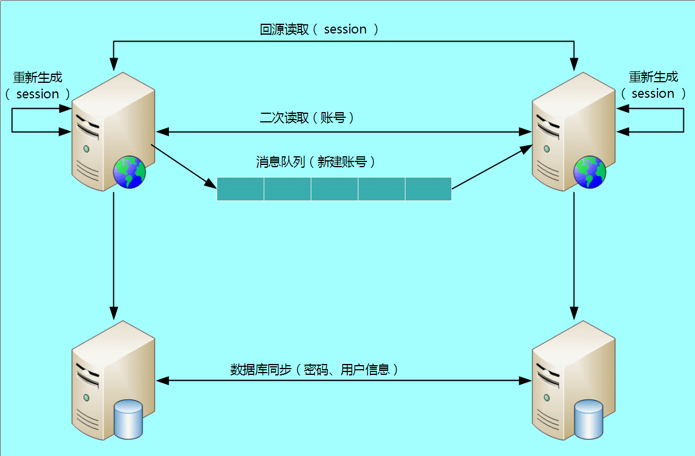
- 消息隊列方式
- 二次讀取方式
- 存儲系統同步方式
- 回源讀取方式
- 重新產生資料方式
以下是資料同步方案架構示意圖:
技巧 4:只保證絕大部分用戶的Multi-Site HA
Multi-Site HA 也無法保證 100% 的業務可用,這是由物理規律決定的,光速和網路的傳播速度、硬盤的讀寫速度、極端異常情況的不可控等,都是無法 100% 解決的
雖然我們無法做到 100% 可用性,但可以採取一些措施進行安撫或者補償:
- 發佈公告
- 事後對用戶進行補償
- 補充體驗 (例如:轉帳完成後的主動通知)
討論整理精華
OceanBase 屬於強一致分佈式資料庫,可以使業務不需要考慮持久層的跨地域資料同步問題
但付出的代價是 request response time 會變大,可用性也有降低,所以對 response time 要求非常高的業務可能不會選擇,其實還是對業務有影響的
如果代價可以承受,業務端還要解決 cache 的一致性問題,流量切到其它可用區的壓力是不是承受的住,可能還是需要部分業務降級
所以分佈式資料庫不能完全做到業務無感知的 Multi-Site HA
根據經濟能力、所需時間及業務要求有先後地選擇 Multi-Site HA 的業務及業務多活的形式
Multi-Site HA 設計 4 步走
Step 1:業務分級
按照一定的標準將業務進行分級,挑選出核心的業務,只為核心業務設計 Multi-Site HA ,降低方案整體複雜度和實現成本
常見的分級標準:
- 訪問量大的業務
- 核心業務
- 產生大量收入的業務
以用戶管理系統為例,”登錄”業務符合”訪問量大的業務”和”核心業務”這兩條標準
Step 2:資料分類
核心業務相關的資料進一步分析,目的在於識別所有的資料及資料特徵,這些資料特徵會影響後面的方案設計
常見的資料特徵分析維度:
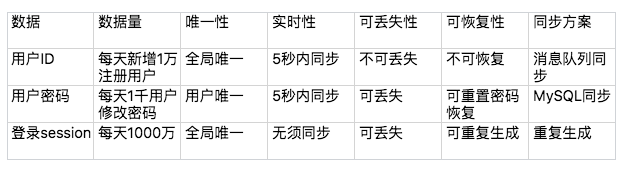
- 資料量:資料量越大,同步延遲的機率越高,同步方案需要考慮相應的解決方案
- 唯一性:是否要求多個異地機房產生的同類資料必須保證唯一(需要設計一個資料唯一生成的算法)
- 即時性:即時性要求越高,對同步的要求越高,方案越複雜
- 可丟失性:資料是否可以丟失
- 可恢復性:資料丟失後,是否可以通過某種手段進行恢復
以用戶管理系統的登錄業務為例的分析範例:
Step 3:資料同步
常見的資料同步方案有以下幾種:
存儲系統同步
優點是使用簡單,因為幾乎主流的存儲系統都會有自己的同步方案
缺點是這類同步方案都是通用的,無法針對業務資料特點做定製化的控制
例如:無論需要同步的資料量有多大,MySQL 都只有一個同步通道。因為要保證事務性,一旦資料量比較大,或者網路有延遲,則同步延遲就會比較嚴重
消息隊列同步
- 適合無事務性或者無時序性要求的資料
重複生成
資料不同步到異地機房,每個機房都可以生成資料,這個方案適合於可以重複生成的資料
登錄產生的 cookie、session 資料、緩存資料適合此方案
以用戶管理系統的登錄業務為例的分析範例:
Step 4:異常處理
無論資料同步方案如何設計,一旦出現極端異常的情況,總是會有部分資料出現異常的
異常處理就是假設在出現這些問題時,系統將採取什麼措施來應對
異常處理主要有以下幾個目的:
- 問題發生時,避免少量資料異常導致整體業務不可用。
- 問題恢復後,將異常的資料進行修正。
- 對用戶進行安撫,彌補用戶損失
常見的異常處理措施:
多通道同步
採取多種方式來進行資料同步,其中某條通道故障的情況下,系統可以通過其他方式來進行同步
設計的方案關鍵點:
- 一般情況下,採取兩通道即可,採取更多通道理論上能夠降低風險,但付出的成本也會增加很多
- 資料庫同步通道和消息隊列同步通道不能採用相同的網路連接
- 需要資料是可以重複覆蓋的,這表示無論那個通道的資料先到,或是那個通道的資料後到,最終結果是一樣的
同步和訪問結合
指異地機房通過系統開放的接口來進行資料訪問
設計關鍵點:
- 接口訪問通道和資料庫同步通道不能採用相同的網路連接
- 資料有路由規則,可以根據資料來推斷應該訪問哪個機房的接口來讀取資料
- 由於有同步通道,優先讀取本地資料,本地資料無法讀取到再通過接口去訪問,這樣可以大大降低跨機房的異地接口訪問數量,適合於即時性要求非常高的資料
日誌記錄
用於用戶故障恢復後對資料進行恢復
每個關鍵操作前後都記錄相關一條日誌,然後將日誌保存在一個獨立的地方,當故障恢復後,拿出日誌跟資料進行對比,對資料進行修復
應對不同級別的故障,日誌保存的要求也不一樣
常見的日誌保存方式:
- 服務器上保存日誌,資料庫中保存資料
- 本地獨立系統保存日誌
- 日誌異地保存
用戶補償
無論採用什麼樣的異常處理措施,都只能最大限度地降低受到影響的範圍和程度,無法完全做到沒有任何影響
可以採用人工的方式對用戶進行補償,彌補用戶損失,培養用戶的忠誠度
討論整理精華
可通過預期貨幣價值分析,進行業務分級;大致維度如下:風險發生概率、風險損耗成本、技術改造成本、技術改造時長(月)、改造後成本節省(月)
通常來說 to C 的應用,影響用戶使用的應該是比較靠前的,尤其是產品還處於搶市場的階段
to B 的應用客戶買的是專業性,相對來說用戶體驗可以往後排,用戶能使用和公司收入還是比較重要的;而客戶相對固定,可以通過客服主動聯繫客戶的方式來做部分挽回
不同類型的公司,對於業務重要性分類是不一樣的,公司階段的不同也不一樣(例如:新聞的初創公司,第一步就是積累用戶,體驗第二,最後是收入)
公司新推出了一個業務,目的是提高用戶的粘性,這類用戶體驗首先解決,然後投訴,最後收入
轉賬收費類業務,那優先保證的就是收入了,其次就是投訴,最後是體驗