集群分佈式模型及選主與腦裂問題
分散式特性
Elasticsearch 的分散式架構帶來以下優點:
可以水平擴展儲存空間,支援 PB 等級的資料儲存
可以根據 request & data 增加的需求進行 scale out;資料分散儲存,因此在 storage 的部份同樣也是可以 scale out 的
提供系統高可用性(HA),當某些節點停止服務時,整個 cluster 的服務不會受影響
- Service HA:若有 node 停止服務,整個 cluster 還是可以提供服務
- Data HA:若有 node 掛掉,資料不會遺失
關於設定 Elasticsearch cluster:
不同的 cluster 透過不同的名字區分,預設為
elasticsearchcluster name 可以透過設定檔修改,也可以在啟動指令中指定
-E cluster.name=[CLUSTER_NAME]進行設定
Node
Node 就是一個 Elasticsearch 的 Java process;基本上一台機器上可以同時運行多個 Elasticsearch process,但 production 使用建議還是只要一個就好
每個 node 都有名稱,可透過設定檔配置,也可以在啟動時透過
-E node.name=[NODE_NAME]進行設定每個 node 啟動之後都會分配一個 UID,並儲存在
/usr/share/elasticsearch/data目錄下若是要查詢 cluster 中的 node 狀態,可以使用 GET /_cat/nodes API
Node Types
Master Node
master node 用來處理以下工作:
處理建立/刪除 index 的 request,並實際執行
決定每個 shard 要被分配到哪個 data node 上
維護 & 更新 cluster state
master node 配置的 best practice:
master node 很重要,佈署上要考慮避免單點故障的狀況發生
為 cluster 設置多個 master node,且必須是 dedicated master node
Master Eligible Node & 選舉流程
cluster 中可以設定多個 master eligible node,當 master node 發生問題時,這些 master eligible node 就會開始選舉流程,選出下一個 master node
這些 node 會互相 ping 對方,而 Node Id 低的會成為被選舉的 node
一旦發現被選中的 master node 出現問題,就會選出新的 master node
每個 node 啟動時就預設是一個 master eligible node,可以透過設定
node.master: false取消此預設設定當 cluster 中的第一個 master eligible node 啟動時,就會把自己選舉為 master node
Coordinating Node
處理 request 的 node 稱為 Coordinating Node,其功能是將 request 轉發到合適的 node 上(例如:建立 index 的 request 要轉發給 master node) & 最後進行結果的匯總
所有的 node 都預設是 Coordinating Node
可以透過將其他 node type 都設定為
false,這樣就可以讓特定的 node 變成 dedicated coordinating nodecoordinating node 可以直接接收 search request 並處理,不需要透過 master node 轉過來
Data Node
可以保存資料的 node,每個 node 啟動後都會預設是 data node,可以透過設定
node.data: false停用 data node 功能用來保存分片資料,實現資料的 scalibility (由 master node 決定如何把分片分發到不同的 data node 上)
透過增加 data node 可以解決資料水平擴展 & 解決單點故障導致資料遺失的問題
同一個 index 的 primary shard & secondary shard 不能放在同一個 data node 上 (增加 data node 就可以解決此問題)
其他類型的 Node Type
Hot & Warm Node:通常 Hot node 會儲存比較新、比較常用的資料,因此通常硬體規格也會比較好;而 Warm Node 則會儲存比較舊 & 較不常用的資料,因此可以用比較低規格的硬體;藉此優化硬體相關的成本開銷Machine Learning Node:專門用來跑 machine learning 的相關工作,可用來搭配異常自動偵測之用
Cluster State (集群狀態)
cluster state 維護了一個 cluster 中必要的訊息,包含以下內容:
所有的 node 資訊
所有的 index & 相對應的 mapping/setting 配置
shard 的路由資訊
每個 node 上都保存了 cluster state
只有 master 才可以修改 cluster state 並負責同步給其他 node (若是每個 node 都可以修改 cluster state,很有可能會導致 cluster state 不一致的狀況發生)
配置不同的 node type
以下是要設定不同的 node type 時所會用到的設定參數:
| Node Type | 配置參數 | 預設值 |
|---|---|---|
| Master Eligible | node.master |
true |
| Data | node.data |
true |
| Ingest | node.ingest |
true |
| Dedicated Coordinating | 無 |
設置上面三個參數皆為 false |
| Machine Learning | node.ml |
true (需要 enable x-pack) |
關於腦裂問題(split brain)
在 ES 7.0 後,已經不需要關心
minimum_master_nodes參數,ES cluster 會自行處理 master 選舉仲裁(quorum)的過程cluster scale out/in 變得更安全 & 容易,資料遺失的機會減少很多
每個 node 都會詳細紀錄本身的狀態資訊,當 cluster 出現問題時有助於協助診斷 & 排除
Shard & Cluster 的故障轉移
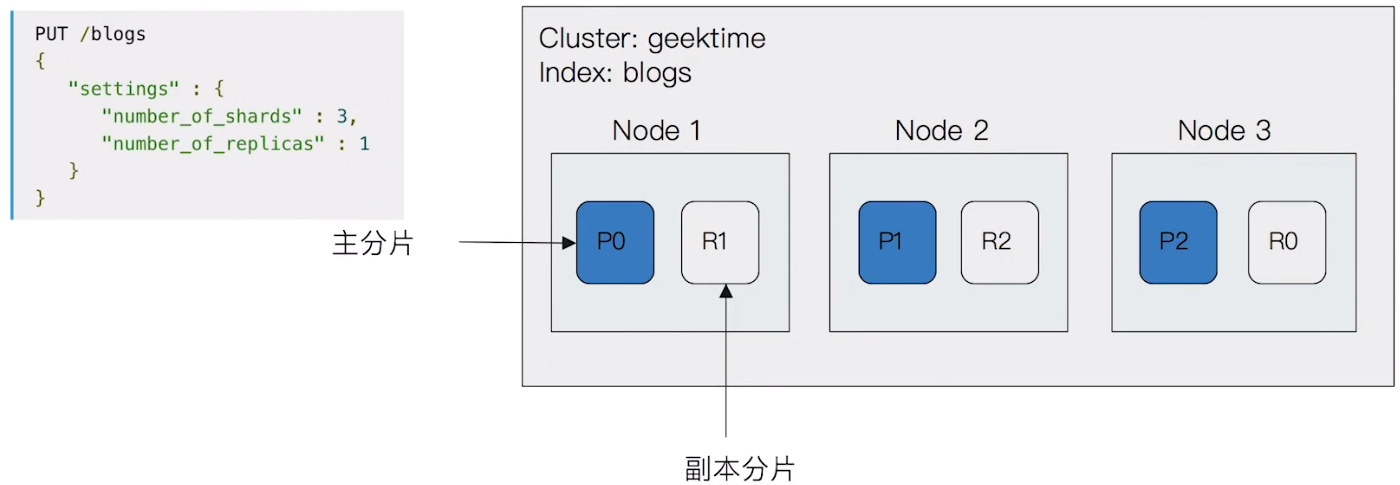
Primary Shard (提昇系統儲存容量)
shard 是 Elasticsearch 分散式儲存的基礎,包含 primary shard & replica shard
每一個 shard 就是一個 Lucene instance
primary shard 功能是將一份被索引後的資料,分散到多個 data node 上存放,實現儲存方面的水平擴展
primary shard 的數量在建立 index 時就會指定,後續是無法修改的,若要修改就必須要進行 reindex
Replica Shard (提高資料可用性)
replica shard 用來提供資料高可用性,當 primary shard 遺失時,replica shard 就可以被 promote 成 primary shard 來保持資料完整性
replica shard 數量可以動態調整,讓每個 data node 上都有完整的資料
replica shard 可以一定程度的提高讀取(查詢)的效能
若不設定 replica shard,一旦有 data node 故障導致 primary shard 遺失,資料可能就無法恢復了
ES 7.0 開始,primary shard 預設為
1,replica shard 預設為0
以下是一個 primary shard=3 + replica shard=1 所會發生的實際資料分佈狀況: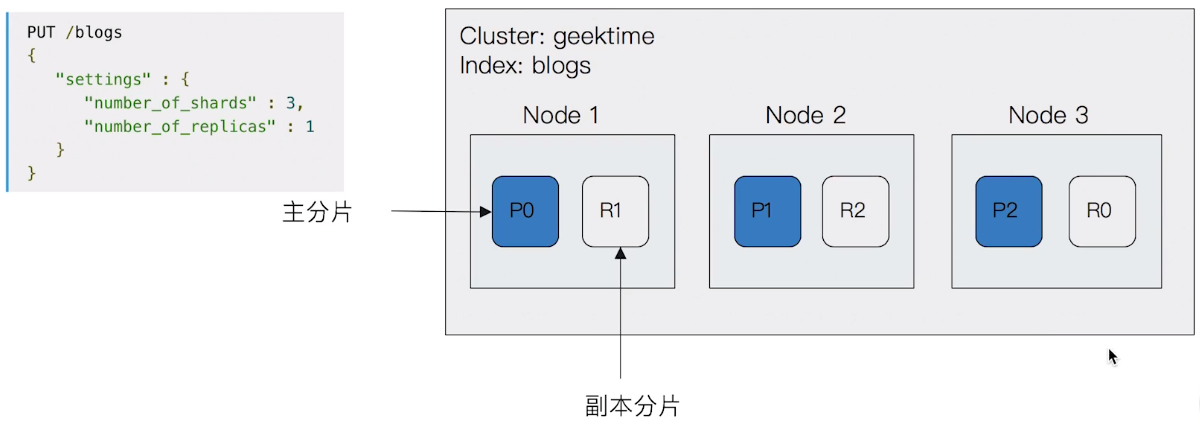
Shard 的規劃 & 設定
primary shard 數量設定太小會遇到以下問題:
- 若 index 資料增加很快時,cluster 無法通過增加 node 數量對 index 進行資料擴展
- 單一 shard 資料太大,導致資料重新分配耗時
primary shard 數量設定太大會遇到以下問題:
- 導致每個 shard 容量很小,讓一個 data node 上有過多 shard 而影響效能
- 影響搜尋時的相關性算分,會讓統計結果失準
replica shard 若設定過多,會降低 cluster 整體的寫入效能
replica shard 必須和 primary shard 被分配在不同的 data node 上;但所有的 primary shard 可以在同一個 data node 上
如何判斷 Cluster 目前的健康狀態?
cluster status
透過 GET _cluster/health/<target> 可以取得目前 cluster 的健康狀態:

Green:表示 primary & replica shard 都可以正常分配Yellow:表示 primary shard 可以正常分配,但 replica shard 分配有問題Red:有 primary shard 無法正常分配例如:當 data node 磁碟空間已經超過 85% 時,此時建立 index 就會出現無法分配 primary shard 的問題
shard status
透過 GET /_cat/shards/<target> 可以取得目前的 shard 狀態:
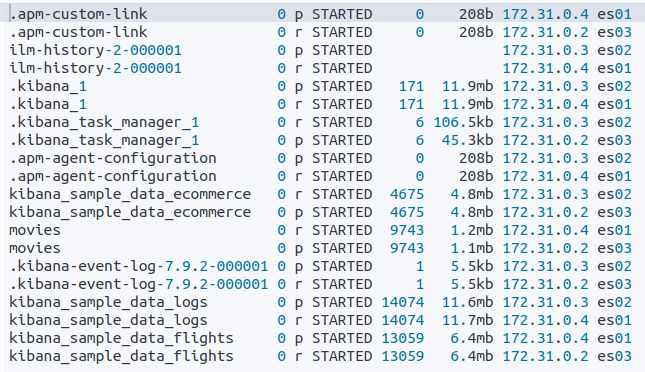
從上圖可以看到以下訊息:
那些 shard 是 primary(
p),那些是 replica(r)shard 的分佈情況 (位於那一個 ndoe 上)
每個 shard 包含的 document 數量 & 佔用的空間
cluster & shard 設定情境 & 範例
single node cluster

由於 cluster 中只有單一個 node,因此全部都會被 primary shard 佔據
replica shard 無法被分配,因此 cluster 健康狀態為黃色
增加第二個 node
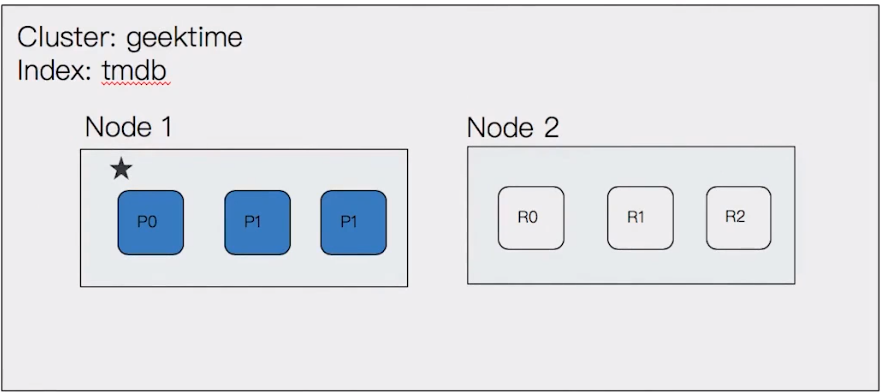
增加第二個 node,因此 replica shard 就可以被正常分配
cluster 健康狀態就會轉為綠色
目前 cluster 已經具備 failover 的能力了
增加第三個 node
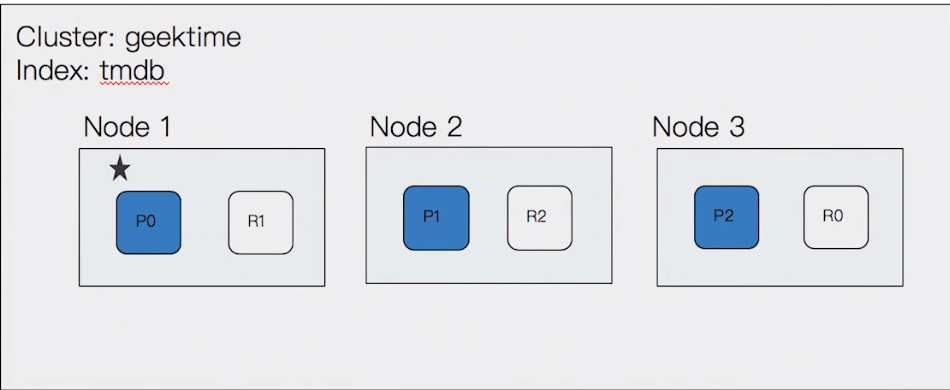
此時 primary shard & replica shard 都會再重新分配,力求資料可以平均分散
由 master node 決定每個 shard 會被分配到那一個 data node
透過持續增加 node,可以提高 cluster 的計算能力
Failover
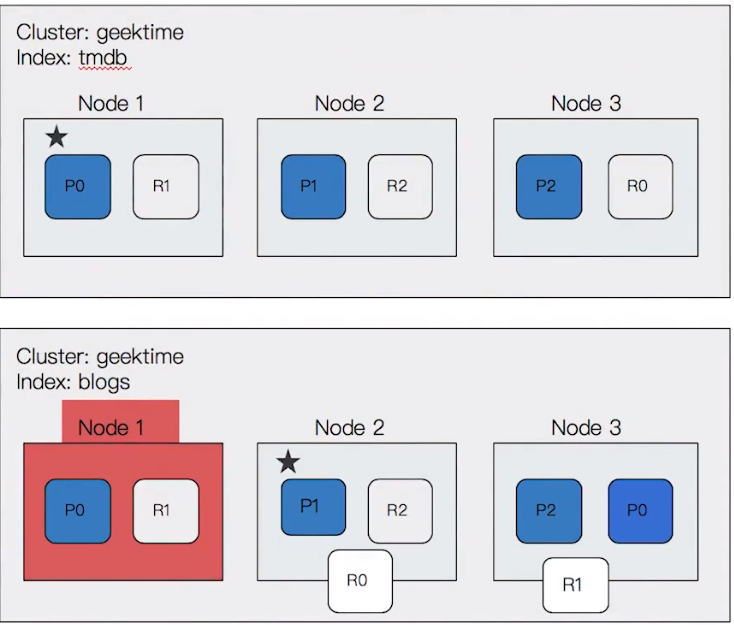
1 index, 3 primary shard, 1 replica shard
上面的部份是正常的時候,下面是表示 node 1(master node) 發生故障
node 2 透過選舉的過程變成了 master node
node 1 上的 P0 跟 R1 已經不可用
node 3 上的 R0 會提昇 P0 成用來取代 Node 1 上的 P0
為了要滿足 replica shard 的設定,node 2(目前的 master) 重新將 R0 & R1 分配到剩餘的 data node 上
cluster 狀態重新變成綠色
若是擔心 reboot 機器造成 failover 動作開始執行,可以設定將 replication 延遲一段時間後再執行(透過調整 settings 中的
index.unassigned.node_left.delayed_timeout參數),避免無謂的 data copy 動作 (此功能稱為 delay allocation)
值得一看的 Q&A 資料
1、選舉 master node 的過程中可能存在問題的場景?
選舉 master node 的過程應該很短,這個期間,如果有創建 index 或者分片 reallocation 有可能會出錯。
2、故障轉移期間可能會出現問題的場景?
故障轉移期間,如果只是黃色變綠,應該不影響讀寫,因為副本會提升為 primary shard 。集群變紅,代表有 primary shard 丟失,這個時候會影響讀寫。
3、故障轉移,資料重新分配,避免消耗性能的方式?
例如一個 primary shard 不可用了。只要設置了 secondary shard ,其中一個 secondary shard 立即會將自己提升為 primary shard;同時會將自己的資料分配到一個新的 replica 上,有時候,我們只是重啟一台機器,可以讓這個 reallocation 的動作延遲一段時間再做,從而避免無謂的資料拷貝。
4、故障轉移可能存在資料遺失的場景嘛?
node 如果故障且資料沒有寫入硬碟。就有資料遺失的可能。如果 node 重新回來,會從 translog 中恢復沒有寫入的資料
Document 分散式儲存
document 儲存在 shard 中
document 會儲存在特定的 primary shard & replica shard 中,例如 document(id=1) 儲存在 P0 & R0 shard 上
將 document 進行分散式儲存的可能解決方案:
random / round robin 的方式,但此方法在 shard 數量大時,需要多次查詢才能找到 document
維護 document & shard 之間的 mapping 關係,但當 document 數量大時,維護成本就會變得很高
透過即時運算,以 document id 為基礎,計算出要去那一個 shard 儲存 & 取得 document
document 到 shard 的路由計算方式
shard = hash(_routing) % number_of_primary_shard
hash algorithm 確保 document 均勻的分散到 primary shard 中
預設的
_routingvalue 是 document id可以自行指定 routing value,藉此讓 document 都分配到特定的 shard 上
也是因為上述路由設計機制的原因,導致於設定 index settings 之後,primary shard 數量無法隨意變更
更新 document 流程
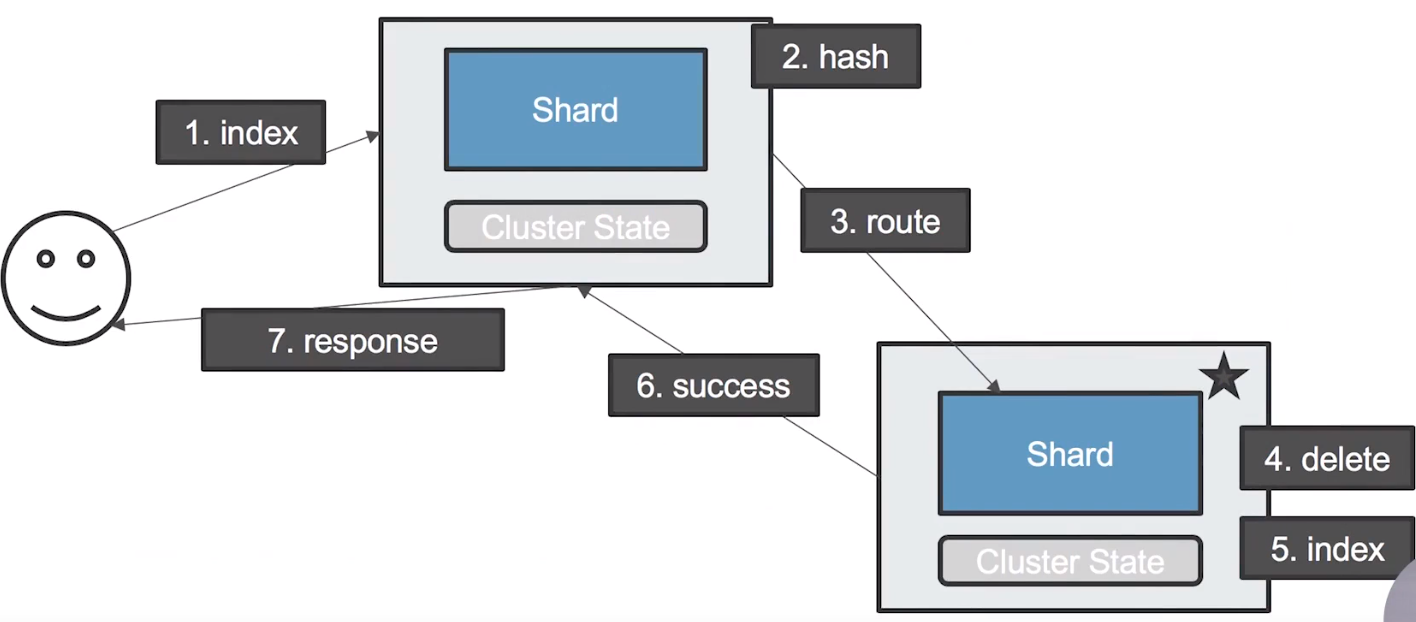
使用者送出一個 update document request 到 master node(同時也是 coordinating node)
coordinating node 透過 hash 計算出 document 存放的 shard 在哪裡
將 update request 轉發到正確的 data node 上
data node 取得 update request,會先將 document 刪除
再重新索引新的 document,完成標準的 update 操作
將更新成功訊息回傳給 coordinating node
coordinating node 回傳操作成功訊息給使用者
刪除 document 流程
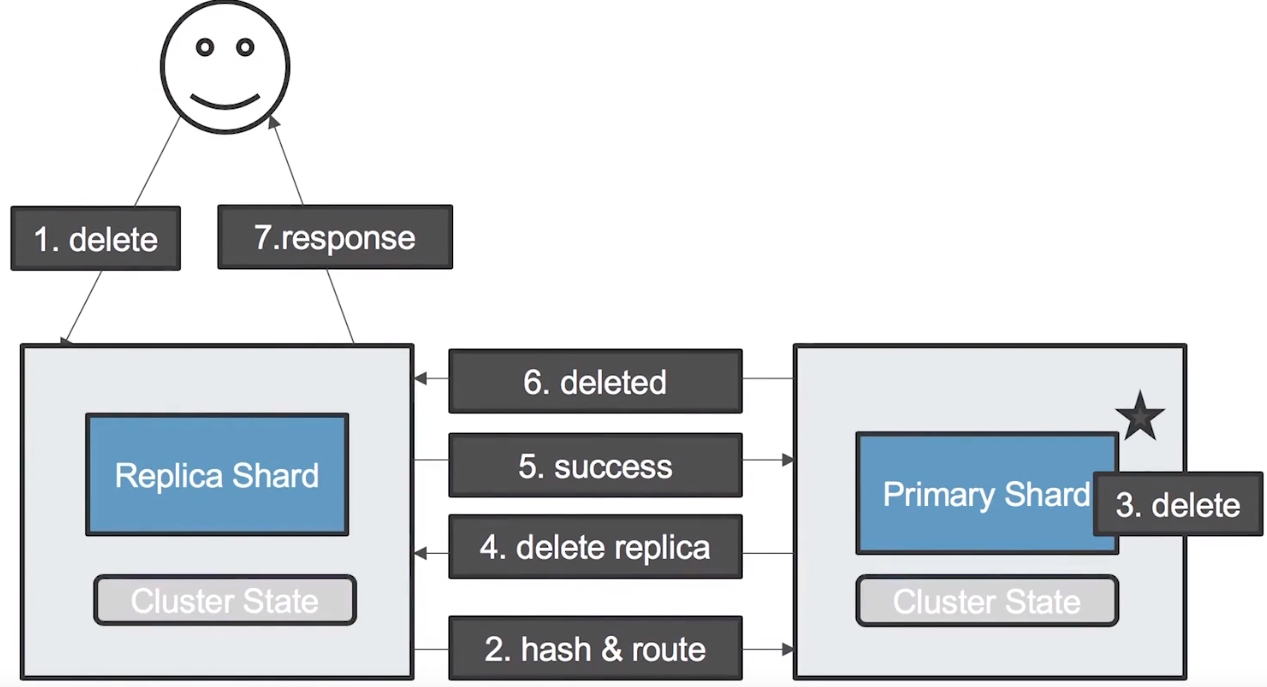
使用者送出一個 delete document request 到 master node(同時也是 coordinating node)
coordinating node 透過 hash 計算出 document 存放的 primary shard 在哪裡,並將 request 轉發到正確的 data node 上
data node 刪除 shard 中指定的 document
data node 送出 delete replica request 到儲存 replica shard 的 data node 上 (透過每個 node 上的 cluster state 才可以找到 routing 資訊)
replica shard 中的資料被刪除,data node 會回傳成功訊息
儲存 primary shard 的 data node 將刪除成功的訊息回傳給 coordinating node
coordinating node 回傳操作成功訊息給使用者
值得一看的 Q&A 資料
- 請問,視頻中更新和刪除文檔的請求,首先會發送到master節點嗎,還是通過前置的負載均衡工具分發到某一個節點?
視頻中發送到 9200,我也沒在開發環境中指定 dedicated 的節點。所以這個節點既是 master 也是 data,當然肯定也是 coordinating 節點。
在生產環境,你可以設置 dedicate 的 coordinate 節點,發查詢到這些節點。不建議直接發送請求到master節點,雖然也會工作,但是大量請求發送到 master,會有潛在的性能問題
Shard & Life cycle
shard 內部原理
shard 是 ES 中最小的工作單元
shard 是一個 Lucene 的 index
關於一些 Elasticsearch 的相關問題:
Elasticsearch 的搜尋是如何作到接近即時的 ?
Elasticsearch 如何確保臨時的停電不會造成資料遺失 ?
為什麼刪除 document 後,不會馬上釋放空間 ?
Inverted Index 的不可變動性
Inverted Index 使用 immutable design,一旦產生出來就無法變更
然而不可變動的特性會帶來以下好處:
不需要考慮同時多個 document 寫入的問題,因此避免了 lock 機制所帶來的效能問題
一旦資料進入到 file system cache,就會留在裡面;只要 cache 夠大,大部分 request 就不會有 disk access,藉此大幅提昇讀取性能
cache 容易產生 & 維護
資料可以被壓縮
不可變動的特性帶來的缺點 => 若需要讓一個新的 document 可以被搜尋,需要重建 index
Index Refresh
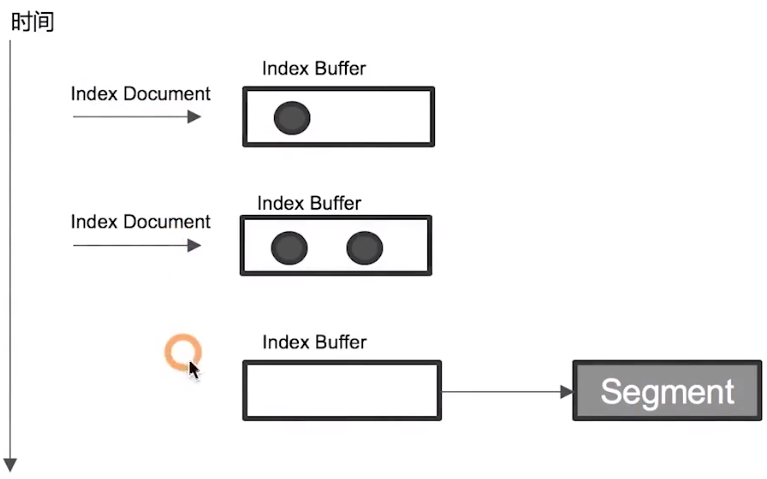
Elasticsearch 寫入 document 時,會先寫入稱為
Index Buffer的儲存空間到特定時間點(or 滿足特定條件)時,就會將 Index Buffer 中的內容寫入
Segment,而這寫入的過程就稱為Refresh,但預設不會執行 fsync 操作預設一秒一次,可以透過設定
index.refresh_interval進行調整當 document 被 refresh 進入到 segment 之後,就可以被搜尋到了
若系統有大量的資料寫入,就會產生很多 segment
當 Index Buffer 被佔滿時,也會觸發 refresh 動作,預設值是 JVM 的 10%
Transaction Log
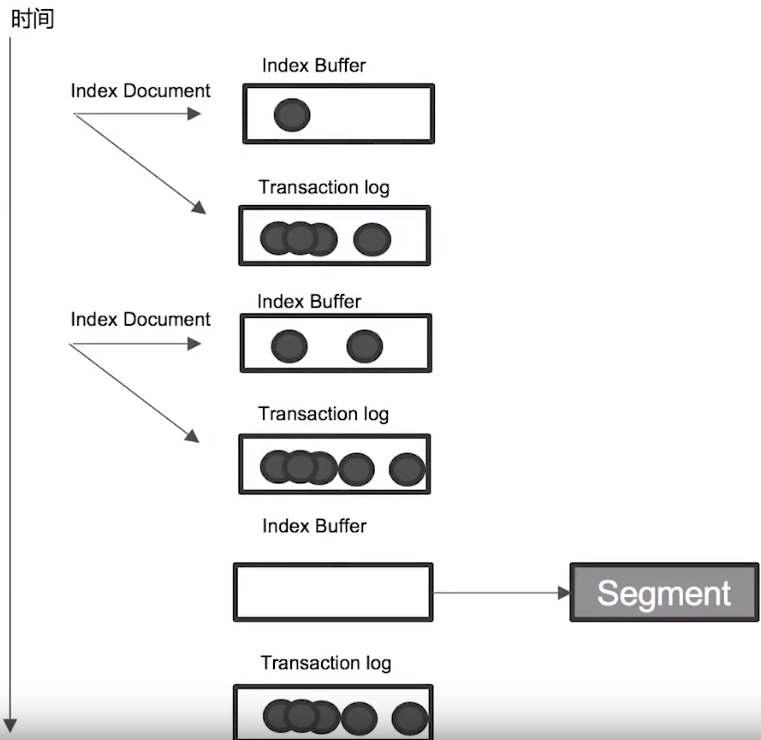
segment 寫入磁碟的過程相對耗時,因此藉由 cache,在進行 refresh 時先將 segment 寫入 cache 以開放查詢
但使用 cache 可能就會有資料遺失的問題,因此為了保證資料不會遺失,就有了 transaction log 的設計
將 document 進行索引時,同時也會寫入 transaction log,且預設都會寫入磁碟中
每個 shard 都會有對應的 transaction log
Elasticsearch 進行 refresh 時,index buffer 會被清空,但 transaction log 則不會
由於 transaction log 都會寫入磁碟中,因此當 node 從故障中恢復時,就會優先讀取 transaction log 來恢復資料
Flush
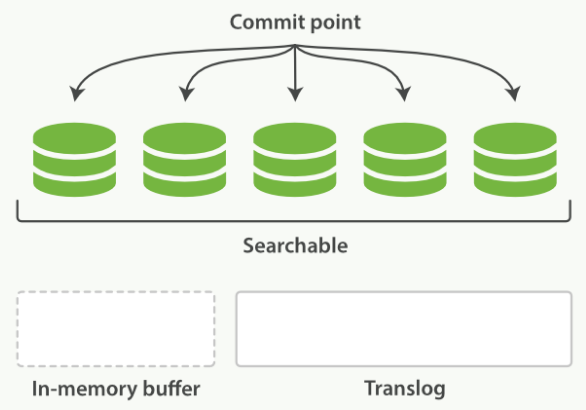
執行 refresh,將 index buffer 清空
執行 fsync,將在 cache 中的 segment 全部寫入磁碟中
清空 transaction log
由於操作對資源消耗相對大,因此預設 30 分鐘執行一次
當 transaction log 滿了(預設為 512 MB),也會觸發 flush 的操作
Merge
當 flush 工作陸陸續續完成後,segment 上的資料會寫入磁碟中,因此磁碟中就會累積越來越多的 segment 檔案,而 merge 就可以協助定期將多個 segment 檔案合併成一個
可以減少 segment 數量 & 將被刪除的 document(寫在
.del中的資訊) 從磁碟中真正的移除掉Elasticsearch 會定期自動執行 merge 工作
若是要強制執行 merge 操作,可以呼叫
POST [INDEX_NAME]/_forcemerge執行
值得一看的 Q&A 資料
- 客戶端發起資料寫入請求,對你寫的這條資料根據 _routing 規則選擇發給哪個 shard
- 確認 Index Request 中是否設置了使用哪個 Filed 的值作為路由參數,
- 如果沒有設置,則使用 mapping 中的配置,
- 如果 mapping 中也沒有配置,則使用
_id作為路由參數,然後通過 _routing 的 Hash 值選擇出 shard,最後從集群的 Meta 中找出出該 shard 的 primary節點。
- 寫入請求到達 shard 後,先把資料寫入到內存(buffer)中,同時會寫入一條日誌到 translog 日誌文件中去
- 當寫入請求到 shard 後,首先是寫 Lucene,其實就是創建索引。
- 索引創建好後並不是馬上生成 segment,這個時候索引資料還在緩存中,這裡的緩存是 lucene 的緩存,並非 Elasticsearch 緩存,lucene 緩存中的資料是不可被查詢的
- 執行refresh操作:從內存 buffer 中將資料寫入 os cache(操作系統的內存),產生一個 segment file 文件,buffer 清空
- 寫入 os cache 的同時,建立倒排索引,這時資料就可以供客戶端進行訪問了。
- 默認是每隔1秒 refresh 一次的,所以 ES 是準即時的,因為寫入的資料 1 秒之後才能被看到
- buffer 記憶體佔滿的時候也會執行 refresh 操作,buffer 預設值是 JVM內存的 10%
- 通過 ES 的 restful api 或者 java api,手動執行一次 refresh 操作,就是手動將 buffer 中的資料刷入 os cache中,讓資料立刻就可以被搜尋到
- 若要優化索引速度, 而不注重即時性, 可以降低刷新頻率。
- translog會每隔 5 秒或者在一個變更請求完成之後,將 translog 從緩存刷入磁碟。
- translog 是存儲在 os cache 中,每個分片有一個,如果節點當機會有 5 秒資料丟失,但是性能比較好,最多丟 5 秒的資料。
- 可以將 translog 設置成每次寫操作必須是直接 fsync 到磁碟,但是性能會差很多。
- 可以通過配置增加 transLog 刷磁碟的頻率來增加資料可靠性,最小可配置 100ms,但不建議這麼做,因為這會對性能有非常大的影響。
- 每 30 分鐘或者當 tanslog 的大小達到512M時候,就會執行 commit操作(flush操作),將 os cache 中所有的資料全以 segment file 的形式,持久到磁碟上去。
- 第一步,就是將 buffer 中現有資料 refresh 到 os cache 中去。
- 清空 buffer 然後強行將 os cache 中所有的資料全都一個一個的通過 segment file 的形式,持久到磁碟上去。
- 將 commit point 這個文件更新到磁碟中,每個 Shard 都有一個提交點(commit point), 其中保存了當前 Shard 成功寫入磁碟的所有 segment。
- 把 translog 文件刪掉清空,再開一個空的 translog 文件。
- flush 參數設置:
- index.translog.flush_threshold_period:
- index.translog.flush_threshold_size:
- #控制每收到多少條資料後flush一次
- index.translog.flush_threshold_ops:
- segment 的 merge 操作:
- 隨著時間,磁碟上的 segment 越來越多,需要定期進行合併。
- ES 和 Lucene 會自動進行 merge 操作,合併 segment 和刪除已經刪除的文檔。
- 我們可以手動進行 merge:POST index/_forcemerge。一般不需要,這是一個比較消耗資源的操作
當資料從 hot 移動到 warm,官方建議手動執行一下 _forcemerge
剖析 Distributed Search(分佈式查詢)及相關性算分
Distributed Search 的運作機制
- Elasticsearch 的搜尋會分為兩個階段,分別是
Query&Fetch,也就是Query-then-Fetch
Query-then-Fetch 範例
以下面的搜尋為例:
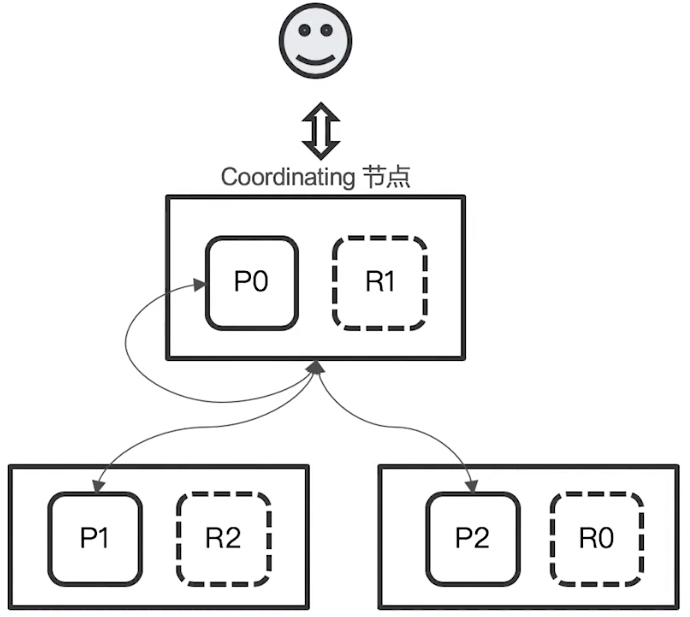
Query 階段
使用者送出 search 到 Elasticsearch,Coordinating Node 會在六個 primary & replica shard 中隨機挑選三個 shard 並送出 request 給 data node
被選中的 shard 執行查詢 & 排序,返回
From + Size個排序後的 document ID & 排序值給 Coordinating Node上圖中是 P0, P1, P2 被選中 (目前只有取得 document ID,沒有內容)
Fetch 階段
Coordinating Node 會將 Query 階段中從每個 shard 取得的 document ID 重新排序,並根據
From&Size重新選出 document ID list以 multiple GET 的方式,從對應的 shard 取得詳細的 document 資訊
Query-then-Fetch 的潛在問題
效能問題:
每個 shard 需要查詢的 document 數量 =
from+size最後 Coordinating Node 需要處理
number_of_shard * (from + size)數量的 document若是遇到深度分頁的情況,效能會變很差
相關性算分:
- 每個 shard 都基於自己 shard 上的資料進行相關度計算;若是在資料量少,shard 數量越大會導致算分越不準確
如何解決算分不準的問題 ?
資料量不大時,可以將 primary shard 數量設定為 1
但若資料足夠大時,只要確保 document 可以平均分散在多個 shard 上,結果就不會有太大偏差
使用 DFS Query Then Fetch
在搜尋的 URL 中指定參數
_search?search_type=dfs_query_then_fetch這會到各 shard 中蒐集完整的 TF & IDF 的資料,再重新匯總並算分,但這會消耗太多 CPU & memory,不建議使用
值得一看的 Q&A 資料
排序及 Doc Values & Fielddata
Sorting
Elasticsearch 預設會使用相關性算分對結果進行排序
可以透過設定
sorting參數決定排序的條件若自己給入 sort 條件時但卻不是指定
_score,則算分為 NULL
以下是幾個範例:
1 | //single field 查詢,並指定 "sort" |
若想要對 text 類型的 field 做排序:
1 | //這樣的查詢會報錯,預設是無法針對 text 類型的 field 做排序 |
sorting 的過程
sorting 是針對原始的 field 內容進行,因此 inverted index 無法發揮作用
需要使用到 forward index(正排索引),透過 document ID & field 快速得到 field 原始內容
在 Elasticsearch 中有兩種實現 sorting 的方式:
Fielddata
Doc Values (列式儲存,對 text 類型無效))
Doc Values v.s. Field data
| Doc Values | Field data | |
|---|---|---|
| 何時建立? | 資料進行索引時,和 inverted index 一起建立 | 搜尋時動態建立 |
| 建立位置 | 磁碟檔案 | JVM Heap |
| 優點 | 避免佔據大量記憶體 | 索引速度快,不佔用額外的磁碟空間 |
| 缺點 | 降低索引速度,佔用額外的磁碟空間 | document 過多時,動態建立的消耗大,佔用過多的 JVM Heap |
| 預設? | ES 2.x 之後 | ES 1.x 及之前 |
一般不會開啟 fielddata,因為對 text field 排序通常沒什麼意義,通常僅有在 aggregation 需求時才會開啟 fielddata 的設定
關閉 Doc Values
透過以下的語法,可以關閉 Doc Values:
1 | PUT test_keyword/_mapping |
Doc Values 預設啟用,可以透過 mapping 設定關閉,優點可以增加索引速度 & 減少硬碟空間的消耗
如果要重新打開,需要重建 index
若是對於不需要進行 sorting or aggregation 的欄位,就可以關閉該欄位的 Doc Values
分頁與遍歷:From, Size, Search After & Scroll API
From & Size
- Elasticsearch 預設對搜尋回傳 10 筆紀錄,
From是 document 開始位置,Size是期望取得 document 的總數
分散式系統中 Deep Pagination(深度分頁)的問題
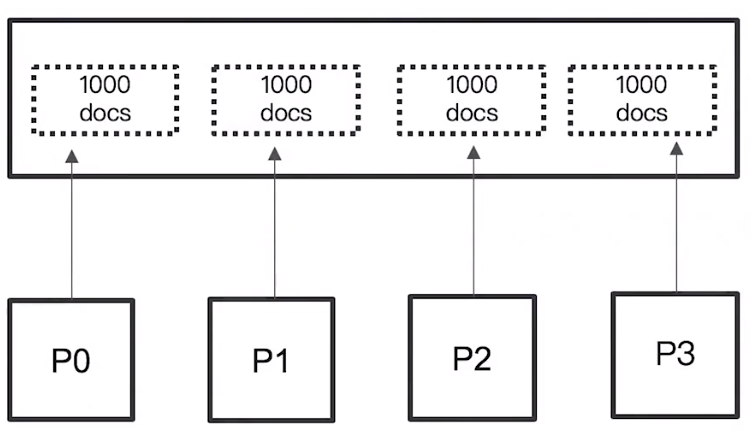
Elasticsearch 是個分散式系統,資料會分佈在多個 shard 中
但假設查詢的
From=990&Size=10時,Elasticsearch 會進行以下操作:在每個 shard 中取得 1000 個 document,然後 coordinating node 會整合所有結果,最後透過排序選取前 1000 個 document
這表示所有資料都會經過 retrieved、collected、sorted 三個階段,資料量大時其實消耗很多資源
頁數越深,佔用的 memory 越多;而為了避免記憶體耗用過大,Elasticsearch 預設限制到 10,000 個 document(可透過修改
index.max_result_window來調整)
可以透過限制搜尋資料筆數上限來避免此問題
使用 search_after 避免 Deep Pagination(深度分頁)問題
為了避免 deep pagination 的問題,Elasticsearch 提供了 search_after 的功能,以下是一個簡單範例:
1 | //透過 "search_after" 可以明確指定從哪裡開始取得資料 |
然而 search_after 會有以下兩項限制:
不支援指定頁數 (也就是表示不能指定
From)只能往下翻頁,無法往回
搜尋時需要指定上一次的
sortvalue,如此一來就可以一次一次的搜尋結果進行翻頁search_after是透過唯一排序值的定位方式,將每次要處理的 document 數量都控制在 10(可自訂size)
Scroll API
Scroll API 也是為了解決深度搜尋的另外一種方式,實踐的方法類似 search_after,作法如下:
搜尋時建立一個快照(
POST /[INDEX_NAME]/_search?scroll=5m, 5m 表示快照有效時間為 5 mins),作為後續繼續快速搜尋之用,但如果有新的資料寫入後,就沒辦法被查詢到了每次查詢時,要將上次查詢結果中的 scroll id 拿來使用,才可以正確的繼續往下搜尋
不同的搜尋類型 & 使用場景
一般搜尋:需要接近即時的取得最新的部份資料,例如:查詢最新訂單
Scroll:需要全部 document,但過程中的分頁速度要快,例如:導出全部資料
Pagination:使用
from&size,如果要處理 deep pagination 的問題,則使用search_after
值得一看的 Q&A 資料
處理 Concurrent 讀寫操作
Concurrent control 的重要性
以下是一個常見的範例,假設在沒有做 concurrent control 的狀況下,下圖的情況就有可能發生,導致實際庫存錯誤:
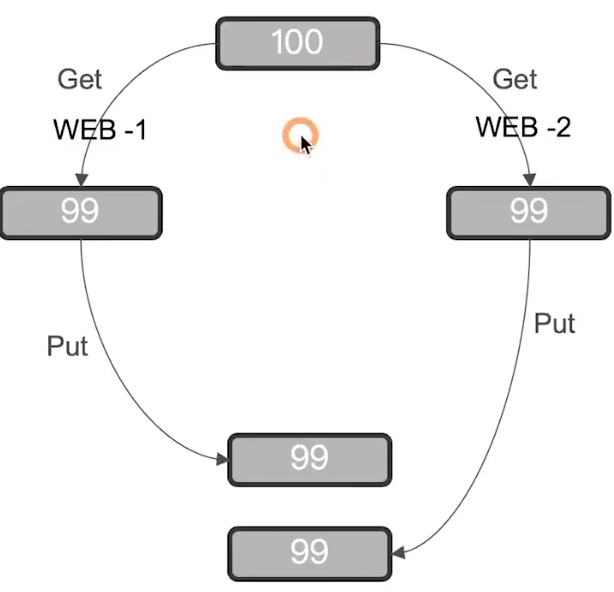
兩個 web process 同時更新某個 document,如果沒有對 concurrent control,可能會導致更新的資料遺失
悲觀鎖定(Pessimistic Locking):假設有變更衝突的可能性,因此對資源更新的時候會進行 lock,防止衝突,例如:DB row lock
樂觀鎖定(Optimistic Locking)
假設更新衝突不會發生,因此不會阻止正在嘗試更新的操作
但如果資料在讀寫中被修改,更新會失敗
通常由應用程式端來解決這樣的衝突,例如:重新嘗試更新、使用新資料、或是回應錯誤訊息給使用者
Elasticsearch 採用的即是 Optimistic Locking
Elasticsearch 如何作到 Optimistic Locking 下的 Concurrent Control ?

Elasticsearch 中的 document 是不可變更的;更新 document 會將原本的 document 標記為刪除,並增加一個全新的 document,同時 document 的
versionfield 加 1內部版本控制,可透過
if_seq_no+if_primary_term來處理外部版本(Elasticsearch 只是用來作為類似 DB backup)時,可使用
version+version_type=external來處理
以下是個簡單範例:
1 | DELETE products |
- 若是希望由系統來處理同時多筆操作更新相同資料時,可以使用
retry_on_conflict參數,在遇到 seq_no 衝突時可以自動重試